DehazeDCT: Towards Effective Non-Homogeneous Dehazing via Deformable Convolutional Transformer

0

Sign in to get full access
Overview
- This paper proposes a novel image dehazing method called DehazeDCT that leverages a Deformable Convolutional Transformer (DCT) architecture to effectively handle non-homogeneous haze.
- The method aims to improve upon existing dehazing approaches by addressing the challenge of non-uniform haze distributions, which can be difficult to handle effectively.
- The DCT module in DehazeDCT is designed to adaptively capture the varying haze characteristics across an image, leading to more robust and accurate dehazing performance.
Plain English Explanation
The research paper introduces a new technique called DehazeDCT for removing haze or fog from images. Haze and fog can make images look blurry and unclear, making it hard to see details. Existing dehazing methods often struggle with non-uniform haze, where the haze levels vary across different parts of the image.
DehazeDCT addresses this challenge by using a special type of neural network called a Deformable Convolutional Transformer (DCT). The DCT module is able to adaptively capture the varying haze characteristics in different regions of the image. This allows the dehazing process to be tailored to the specific haze patterns present, leading to clearer and more accurate results.
The key innovation in DehazeDCT is this DCT module, which gives the system the flexibility to handle non-homogeneous haze that typical dehazing methods have difficulty with. By adapting to the unique haze distribution in each image, DehazeDCT can produce superior dehazing performance compared to previous approaches.
Technical Explanation
The authors of the paper propose a new image dehazing method called DehazeDCT that utilizes a Deformable Convolutional Transformer (DCT) module to effectively handle non-homogeneous haze. Existing dehazing techniques often struggle with uneven haze distributions, where the haze levels vary across different regions of an image.
To address this challenge, the DehazeDCT architecture incorporates a DCT module that is designed to adaptively capture the varying haze characteristics. The DCT leverages deformable convolutions and a transformer-based design to give the model the flexibility to focus on and process the hazy regions in a dynamic, content-aware manner.
This adaptive dehazing capability of the DCT module is a key innovation of the DehazeDCT approach. By tailoring the dehazing process to the specific haze patterns in each image, the method can produce more accurate and effective results compared to previous non-homogeneous dehazing techniques.
The paper also presents a comprehensive evaluation of DehazeDCT on several benchmark datasets, demonstrating its superior performance over state-of-the-art dehazing methods. The authors analyze the impact of the DCT module and show how it enables DehazeDCT to handle a wide range of non-uniform haze conditions.
Critical Analysis
The DehazeDCT method proposed in the paper represents an interesting and promising approach to addressing the challenge of non-homogeneous haze removal. The authors have identified an important limitation of existing dehazing techniques and have developed an innovative solution using the DCT module.
One potential area for further exploration is the computational efficiency and real-world deployment of the DehazeDCT model. The use of a transformer-based architecture and deformable convolutions may incur additional computational costs compared to simpler dehazing approaches. The authors could investigate ways to optimize the model for faster inference or explore lighter-weight variants without sacrificing too much performance.
Additionally, while the paper provides comprehensive evaluations on benchmark datasets, it would be valuable to see more analysis of the method's generalization capabilities and robustness to diverse real-world haze conditions. Assessing the model's performance on a wider range of hazy scenes, including those with complex backgrounds or varying environmental factors, could help validate its practical applicability.
Overall, the DehazeDCT method is a noteworthy contribution to the field of image dehazing, particularly in its ability to handle non-uniform haze distributions. As the authors continue to refine and build upon this work, it could lead to further advancements in producing clear and detailed images in challenging atmospheric conditions.
Conclusion
The DehazeDCT paper presents a novel image dehazing approach that leverages a Deformable Convolutional Transformer (DCT) module to effectively handle non-homogeneous haze. The key innovation of the method is its ability to adaptively capture the varying haze characteristics across different regions of an image, which allows for more accurate and robust dehazing performance compared to previous techniques.
The comprehensive evaluations conducted by the authors demonstrate the effectiveness of the DehazeDCT approach, particularly in addressing the challenge of non-uniform haze distributions. This work represents a significant step forward in the field of image dehazing, and the insights and techniques developed in this paper could have broader implications for other computer vision tasks involving adaptive, content-aware processing.
As the research in this area continues to evolve, further refinements and extensions of the DehazeDCT method, such as improving computational efficiency and exploring its generalization to diverse real-world scenarios, could lead to even more impactful advancements in the ability to produce clear and detailed images in hazy conditions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DehazeDCT: Towards Effective Non-Homogeneous Dehazing via Deformable Convolutional Transformer
Wei Dong, Han Zhou, Ruiyi Wang, Xiaohong Liu, Guangtao Zhai, Jun Chen
Image dehazing, a pivotal task in low-level vision, aims to restore the visibility and detail from hazy images. Many deep learning methods with powerful representation learning capability demonstrate advanced performance on non-homogeneous dehazing, however, these methods usually struggle with processing high-resolution images (e.g., $4000 times 6000$) due to their heavy computational demands. To address these challenges, we introduce an innovative non-homogeneous Dehazing method via Deformable Convolutional Transformer-like architecture (DehazeDCT). Specifically, we first design a transformer-like network based on deformable convolution v4, which offers long-range dependency and adaptive spatial aggregation capabilities and demonstrates faster convergence and forward speed. Furthermore, we leverage a lightweight Retinex-inspired transformer to achieve color correction and structure refinement. Extensive experiment results and highly competitive performance of our method in NTIRE 2024 Dense and Non-Homogeneous Dehazing Challenge, ranking second among all 16 submissions, demonstrate the superior capability of our proposed method. The code is available: https://github.com/movingforward100/Dehazing_R.
Read more7/9/2024

0
HDRTransDC: High Dynamic Range Image Reconstruction with Transformer Deformation Convolution
Shuaikang Shang, Xuejing Kang, Anlong Ming
High Dynamic Range (HDR) imaging aims to generate an artifact-free HDR image with realistic details by fusing multi-exposure Low Dynamic Range (LDR) images. Caused by large motion and severe under-/over-exposure among input LDR images, HDR imaging suffers from ghosting artifacts and fusion distortions. To address these critical issues, we propose an HDR Transformer Deformation Convolution (HDRTransDC) network to generate high-quality HDR images, which consists of the Transformer Deformable Convolution Alignment Module (TDCAM) and the Dynamic Weight Fusion Block (DWFB). To solve the ghosting artifacts, the proposed TDCAM extracts long-distance content similar to the reference feature in the entire non-reference features, which can accurately remove misalignment and fill the content occluded by moving objects. For the purpose of eliminating fusion distortions, we propose DWFB to spatially adaptively select useful information across frames to effectively fuse multi-exposed features. Extensive experiments show that our method quantitatively and qualitatively achieves state-of-the-art performance.
Read more8/30/2024
0
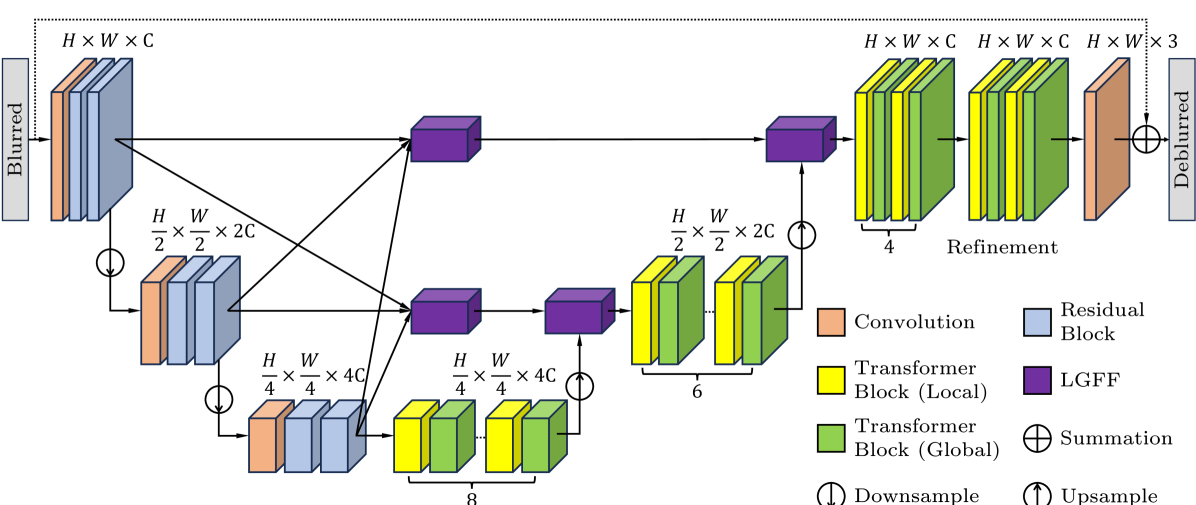
DeblurDiNAT: A Lightweight and Effective Transformer for Image Deblurring
Hanzhou Liu, Binghan Li, Chengkai Liu, Mi Lu
Although prior state-of-the-art (SOTA) deblurring networks achieve high metric scores on synthetic datasets, there are two challenges which prevent them from perceptual image deblurring. First, a deblurring model overtrained on synthetic datasets may collapse in a broad range of unseen real-world scenarios. Second, the conventional metrics PSNR and SSIM may not correctly reflect the perceptual quality observed by human eyes. To this end, we propose DeblurDiNAT, a generalizable and efficient encoder-decoder Transformer which restores clean images visually close to the ground truth. We adopt an alternating dilation factor structure to capture local and global blur patterns. We propose a local cross-channel learner to assist self-attention layers to learn short-range cross-channel relationships. In addition, we present a linear feed-forward network and a non-linear dual-stage feature fusion module for faster feature propagation across the network. Compared to nearest competitors, our model demonstrates the strongest generalization ability and achieves the best perceptual quality on mainstream image deblurring datasets with 3%-68% fewer parameters.
Read more7/12/2024
0
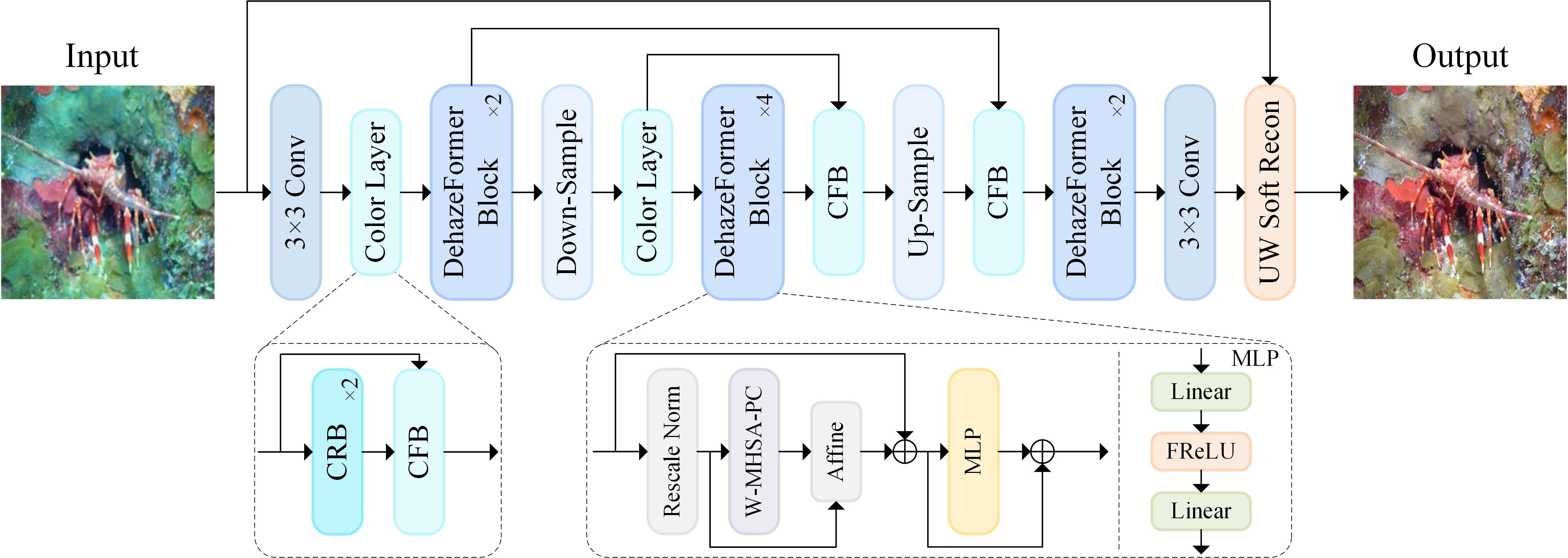
Underwater Image Enhancement via Dehazing and Color Restoration
Chengqin Wu, Shuai Yu, Qingson Hu, Jingxiang Xu, Lijun Zhang
With the rapid development of marine engineering projects such as marine resource extraction and oceanic surveys, underwater visual imaging and analysis has become a critical technology. Unfortunately, due to the inevitable non-linear attenuation of light in underwater environments, underwater images and videos often suffer from low contrast, blurriness, and color degradation, which significantly complicate the subsequent research. Existing underwater image enhancement methods often treat the haze and color cast as a unified degradation process and disregard their independence and interdependence, which limits the performance improvement. Here, we propose a Vision Transformer (ViT)-based network (referred to as WaterFormer) to improve the underwater image quality. WaterFormer contains three major components: a dehazing block (DehazeFormer Block) to capture the self-correlated haze features and extract deep-level features, a Color Restoration Block (CRB) to capture self-correlated color cast features, and a Channel Fusion Block (CFB) to capture fusion features within the network. To ensure authenticity, a soft reconstruction layer based on the underwater imaging physics model is included. To improve the quality of the enhanced images, we introduce the Chromatic Consistency Loss and Sobel Color Loss to train the network. Comprehensive experimental results demonstrate that WaterFormer outperforms other state-of-the-art methods in enhancing underwater images.
Read more9/17/2024