DeblurDiNAT: A Lightweight and Effective Transformer for Image Deblurring

0
Sign in to get full access
Overview
- This paper introduces DeblurDiNAT, a lightweight and effective transformer model for image deblurring.
- It explores the use of a novel attention mechanism called Directional Normalization Attention (DiNAT) to improve the performance of image deblurring.
- The model demonstrates state-of-the-art results on various benchmark datasets while maintaining a small model size and fast inference time.
Plain English Explanation
Image deblurring is the process of restoring a blurred image back to its original, sharp state. This is a common problem in photography, where camera shake or movement can cause blurry images. Effective image deblurring models can help improve the quality of photos and videos.
The authors of this paper have developed a new transformer-based model called DeblurDiNAT that is designed to be lightweight and efficient for image deblurring tasks. Transformers are a type of neural network architecture that has shown great success in a variety of tasks, including image and language processing.
The key innovation in DeblurDiNAT is the use of a novel attention mechanism called Directional Normalization Attention (DiNAT). This attention mechanism helps the model focus on the most relevant parts of the image during the deblurring process, leading to improved performance.
The researchers demonstrate that DeblurDiNAT achieves state-of-the-art results on popular image deblurring benchmark datasets, while also maintaining a small model size and fast inference time. This makes it a practical and effective solution for real-world applications, such as improving the quality of photos taken on smartphones or video deblurring.
Technical Explanation
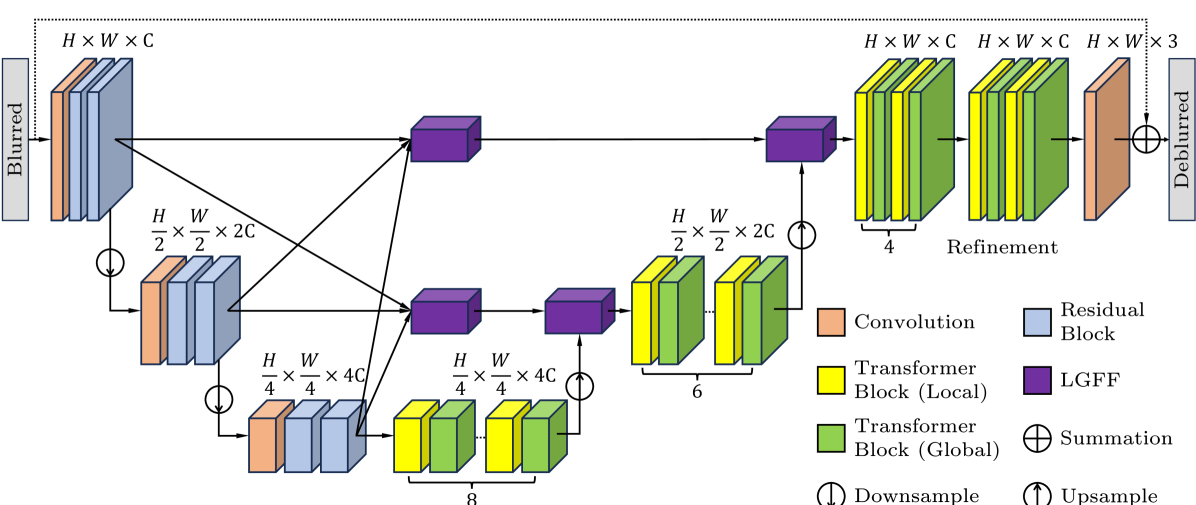
The DeblurDiNAT model consists of a transformer-based architecture that leverages the Directional Normalization Attention (DiNAT) mechanism. The DiNAT module is designed to capture the directional information in the input image, which is crucial for effective image deblurring.
The model takes a blurred input image and generates a deblurred output image. It is composed of several key components:
- Encoder: The encoder takes the input image and generates a feature representation using a series of convolutional and pooling layers.
- DiNAT Module: The DiNAT module applies the novel attention mechanism to the feature representation, allowing the model to focus on the most relevant parts of the image for deblurring.
- Decoder: The decoder takes the processed features from the DiNAT module and generates the final deblurred output image.
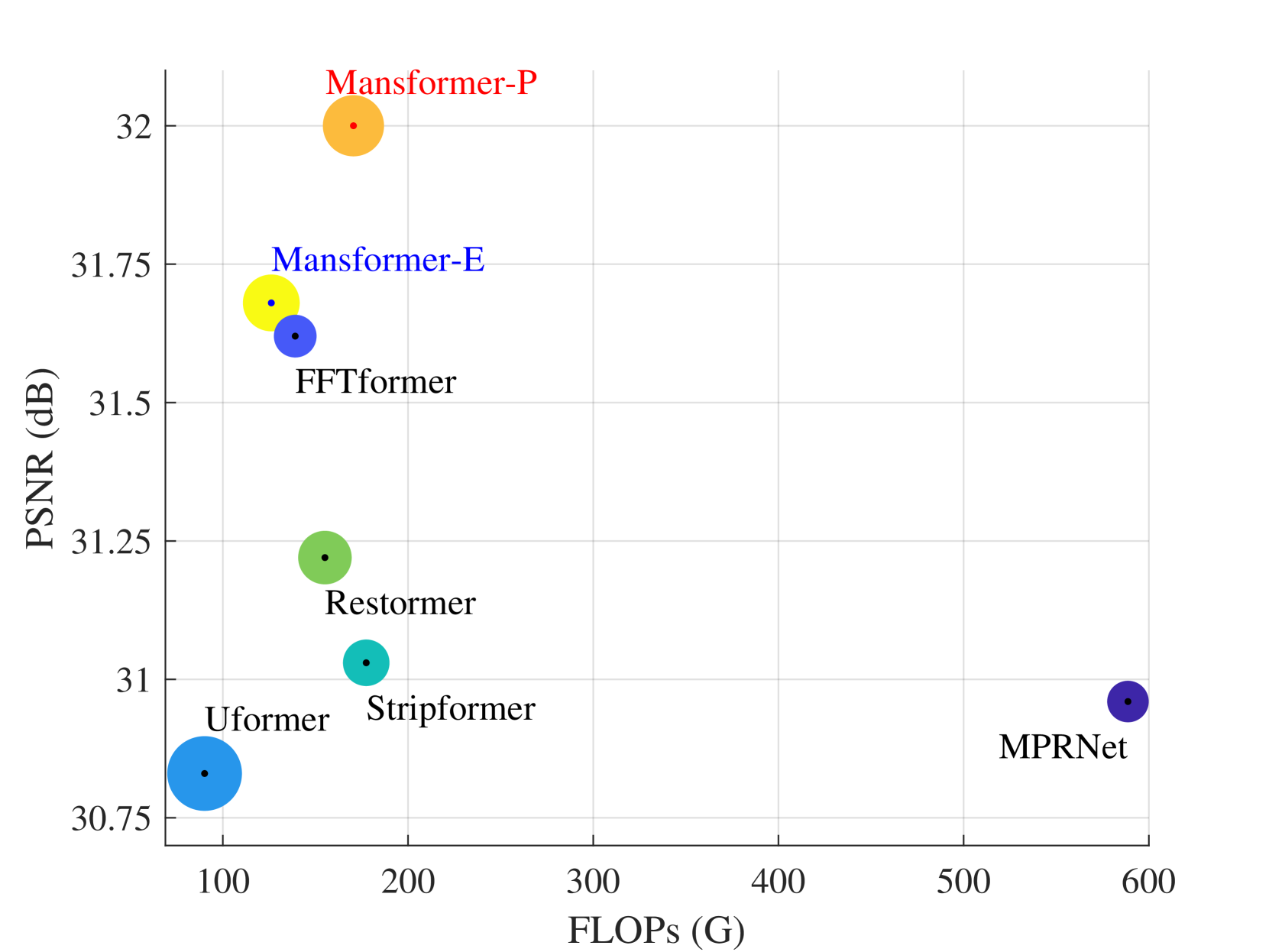
The researchers conducted extensive experiments on various image deblurring benchmark datasets, including GoPro, REDS, and Köhler, and demonstrated that DeblurDiNAT outperforms state-of-the-art image deblurring models in terms of both quantitative and qualitative metrics. Additionally, the model has a small parameter size and fast inference time, making it suitable for real-world applications.
Critical Analysis
The paper presents a well-designed and effective solution for image deblurring, but there are a few potential limitations and areas for further research:
- Generalization to diverse blur types: The paper mainly evaluates the model on uniform blur datasets, which may not fully capture the complexity of real-world blur scenarios. It would be interesting to see how DeblurDiNAT performs on datasets with more diverse blur types.
- Integrating multi-frame information: The current model operates on single-frame inputs, but incorporating information from multiple frames could potentially further improve deblurring performance, especially for video applications.
- Adapting to different hardware platforms: While the paper highlights the efficiency of DeblurDiNAT, it would be valuable to assess its performance and practicality on a wider range of hardware platforms, including mobile devices and embedded systems.
Overall, the DeblurDiNAT model presents a promising approach to efficient and effective image deblurring, and the researchers have demonstrated its potential through thorough experimentation and analysis.
Conclusion
The DeblurDiNAT model introduced in this paper represents a significant advancement in the field of image deblurring. By leveraging a novel attention mechanism called Directional Normalization Attention, the model is able to achieve state-of-the-art performance on various benchmark datasets while maintaining a small model size and fast inference time.
This work has important implications for real-world applications, such as improving the quality of photos and videos captured on mobile devices. The efficiency and effectiveness of DeblurDiNAT make it a practical solution that could be widely adopted in a variety of imaging and multimedia applications.
The researchers have also highlighted potential avenues for further research, such as exploring more diverse blur types and incorporating multi-frame information. As the field of image deblurring continues to evolve, the innovative approaches and insights presented in this paper will undoubtedly contribute to the development of even more advanced and capable deblurring models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DeblurDiNAT: A Lightweight and Effective Transformer for Image Deblurring
Hanzhou Liu, Binghan Li, Chengkai Liu, Mi Lu
Although prior state-of-the-art (SOTA) deblurring networks achieve high metric scores on synthetic datasets, there are two challenges which prevent them from perceptual image deblurring. First, a deblurring model overtrained on synthetic datasets may collapse in a broad range of unseen real-world scenarios. Second, the conventional metrics PSNR and SSIM may not correctly reflect the perceptual quality observed by human eyes. To this end, we propose DeblurDiNAT, a generalizable and efficient encoder-decoder Transformer which restores clean images visually close to the ground truth. We adopt an alternating dilation factor structure to capture local and global blur patterns. We propose a local cross-channel learner to assist self-attention layers to learn short-range cross-channel relationships. In addition, we present a linear feed-forward network and a non-linear dual-stage feature fusion module for faster feature propagation across the network. Compared to nearest competitors, our model demonstrates the strongest generalization ability and achieves the best perceptual quality on mainstream image deblurring datasets with 3%-68% fewer parameters.
Read more7/12/2024

0
EdgeNAT: Transformer for Efficient Edge Detection
Jinghuai Jie, Yan Guo, Guixing Wu, Junmin Wu, Baojian Hua
Transformers, renowned for their powerful feature extraction capabilities, have played an increasingly prominent role in various vision tasks. Especially, recent advancements present transformer with hierarchical structures such as Dilated Neighborhood Attention Transformer (DiNAT), demonstrating outstanding ability to efficiently capture both global and local features. However, transformers' application in edge detection has not been fully exploited. In this paper, we propose EdgeNAT, a one-stage transformer-based edge detector with DiNAT as the encoder, capable of extracting object boundaries and meaningful edges both accurately and efficiently. On the one hand, EdgeNAT captures global contextual information and detailed local cues with DiNAT, on the other hand, it enhances feature representation with a novel SCAF-MLA decoder by utilizing both inter-spatial and inter-channel relationships of feature maps. Extensive experiments on multiple datasets show that our method achieves state-of-the-art performance on both RGB and depth images. Notably, on the widely used BSDS500 dataset, our L model achieves impressive performances, with ODS F-measure and OIS F-measure of 86.0%, 87.6% for multi-scale input,and 84.9%, and 86.3% for single-scale input, surpassing the current state-of-the-art EDTER by 1.2%, 1.1%, 1.7%, and 1.6%, respectively. Moreover, as for throughput, our approach runs at 20.87 FPS on RTX 4090 GPU with single-scale input. The code for our method will be released soon.
Read more8/21/2024
0
Mansformer: Efficient Transformer of Mixed Attention for Image Deblurring and Beyond
Pin-Hung Kuo, Jinshan Pan, Shao-Yi Chien, Ming-Hsuan Yang
Transformer has made an enormous success in natural language processing and high-level vision over the past few years. However, the complexity of self-attention is quadratic to the image size, which makes it infeasible for high-resolution vision tasks. In this paper, we propose the Mansformer, a Transformer of mixed attention that combines multiple self-attentions, gate, and multi-layer perceptions (MLPs), to explore and employ more possibilities of self-attention. Taking efficiency into account, we design four kinds of self-attention, whose complexities are all linear. By elaborate adjustment of the tensor shapes and dimensions for the dot product, we split the typical self-attention of quadratic complexity into four operations of linear complexity. To adaptively merge these different kinds of self-attention, we take advantage of an architecture similar to Squeeze-and-Excitation Networks. Furthermore, we make it to merge the two-staged Transformer design into one stage by the proposed gated-dconv MLP. Image deblurring is our main target, while extensive quantitative and qualitative evaluations show that this method performs favorably against the state-of-the-art methods far more than simply deblurring. The source codes and trained models will be made available to the public.
Read more4/10/2024

0
DaBiT: Depth and Blur informed Transformer for Joint Refocusing and Super-Resolution
Crispian Morris, Nantheera Anantrasirichai, Fan Zhang, David Bull
In many real-world scenarios, recorded videos suffer from accidental focus blur, and while video deblurring methods exist, most specifically target motion blur. This paper introduces a framework optimised for the joint task of focal deblurring (refocusing) and video super-resolution (VSR). The proposed method employs novel map guided transformers, in addition to image propagation, to effectively leverage the continuous spatial variance of focal blur and restore the footage. We also introduce a flow re-focusing module to efficiently align relevant features between the blurry and sharp domains. Additionally, we propose a novel technique for generating synthetic focal blur data, broadening the model's learning capabilities to include a wider array of content. We have made a new benchmark dataset, DAVIS-Blur, available. This dataset, a modified extension of the popular DAVIS video segmentation set, provides realistic out-of-focus blur degradations as well as the corresponding blur maps. Comprehensive experiments on DAVIS-Blur demonstrate the superiority of our approach. We achieve state-of-the-art results with an average PSNR performance over 1.9dB greater than comparable existing video restoration methods. Our source code will be made available at https://github.com/crispianm/DaBiT
Read more7/11/2024