Demonstration-Regularized RL

0
🌀
Sign in to get full access
Overview
- This paper explores how incorporating expert demonstrations can improve the sample efficiency of reinforcement learning (RL).
- The researchers study a specific RL approach called demonstration-regularized reinforcement learning, which uses expert demonstrations to guide the learning process.
- They provide theoretical analyses to quantify how much expert demonstrations can reduce the sample complexity of RL in both finite and linear Markov decision processes.
- As a byproduct, the paper also presents convergence guarantees for behavior cloning, a technique that mimics expert policies.
- Additionally, the researchers show that demonstration-regularized methods are provably efficient for reinforcement learning from human feedback (RLHF).
Plain English Explanation
Reinforcement learning is a powerful technique for training AI systems, but it often requires a lot of trial-and-error experience to learn effectively. This paper explores how incorporating expert demonstrations can help make reinforcement learning more sample-efficient. The researchers study a specific approach called "demonstration-regularized reinforcement learning," which uses expert demonstrations to guide the learning process and help the AI system learn more quickly.
The key idea is that by observing how experts solve a task, the AI system can learn more efficiently and avoid making as many mistakes during the training process. The researchers provide a theoretical analysis to show how this approach can significantly reduce the number of samples (or experiences) the AI system needs to learn an optimal policy, both in finite and linear Markov decision processes.
As a side benefit, the paper also presents strong guarantees for a related technique called "behavior cloning," which tries to directly mimic the expert's policy. The researchers show that this approach can be reliably used to learn from expert demonstrations.
Finally, the paper explores how demonstration-regularized methods can be particularly useful for reinforcement learning from human feedback (RLHF), a technique that is becoming increasingly important for training AI systems that interact with people. The researchers provide theoretical evidence showing the benefits of using KL-regularization (a specific type of regularization) to handle the uncertainty in estimating human rewards, which sets their approach apart from previous work.
Technical Explanation
The key technical contributions of this paper are:
-
Theoretical Analysis of Demonstration-Regularized RL: The researchers provide a detailed theoretical analysis to quantify how expert demonstrations can reduce the sample complexity of reinforcement learning. Specifically, they show that using $N^E$ expert demonstrations enables the identification of an optimal policy with a sample complexity of order $\tilde{O}(\text{Poly}(S,A,H)/(\epsilon^2 N^E))$ in finite MDPs and $\tilde{O}(\text{Poly}(d,H)/(\epsilon^2 N^E))$ in linear MDPs. Here, $\epsilon$ is the target precision, $H$ the horizon, $A$ the number of actions, $S$ the number of states (in the finite case), and $d$ the dimension of the feature space (in the linear case).
-
Tight Convergence Guarantees for Behavior Cloning: As a byproduct, the paper also presents tight convergence guarantees for the behavior cloning procedure under general assumptions on the policy classes. This provides a stronger theoretical foundation for using behavior cloning to learn from expert demonstrations.
-
Theoretical Analysis of Demonstration-Regularized RLHF: The researchers establish that demonstration-regularized methods are provably efficient for reinforcement learning from human feedback (RLHF). They provide theoretical evidence showing the benefits of using KL-regularization to handle reward estimation uncertainty, in contrast to prior work that has relied on pessimism injection.
The theoretical analyses build on techniques from previous work in reverse curriculum learning and hybrid inverse reinforcement learning, adapting them to the demonstration-regularized setting.
Critical Analysis
The paper provides a strong theoretical foundation for understanding the benefits of incorporating expert demonstrations into reinforcement learning. The authors' analyses rigorously quantify the sample complexity improvements that can be achieved, which is an important step in making RL more practical for real-world applications.
That said, the theoretical results rely on several assumptions, such as the availability of a sufficiently large and representative set of expert demonstrations, as well as the ability to accurately model the underlying Markov decision process. In practice, these assumptions may not always hold, and the performance gains may be more modest.
Additionally, the paper focuses on the theoretical aspects and does not provide extensive empirical evaluations. It would be valuable to see how the proposed demonstration-regularized RL methods perform in comparison to other state-of-the-art approaches in realistic environments.
Finally, the paper does not address some potential challenges with using expert demonstrations, such as the potential for the AI system to overfit to the demonstrations or the difficulty of obtaining high-quality expert data in certain domains. Exploring these practical considerations would be an important direction for future research.
Conclusion
This paper makes important theoretical contributions to understanding how expert demonstrations can improve the sample efficiency of reinforcement learning. By providing rigorous analyses of demonstration-regularized RL and behavior cloning, the researchers have laid a solid foundation for further developing these techniques and applying them to real-world problems.
The findings also suggest that demonstration-regularized methods could be particularly useful for reinforcement learning from human feedback, which is a crucial capability as AI systems become more integrated into our lives. Overall, this work represents a significant step forward in bridging the gap between the sample-hungry nature of RL and the practical needs of deploying these systems in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
0
Demonstration-Regularized RL
Daniil Tiapkin, Denis Belomestny, Daniele Calandriello, Eric Moulines, Alexey Naumov, Pierre Perrault, Michal Valko, Pierre Menard
Incorporating expert demonstrations has empirically helped to improve the sample efficiency of reinforcement learning (RL). This paper quantifies theoretically to what extent this extra information reduces RL's sample complexity. In particular, we study the demonstration-regularized reinforcement learning that leverages the expert demonstrations by KL-regularization for a policy learned by behavior cloning. Our findings reveal that using $N^{mathrm{E}}$ expert demonstrations enables the identification of an optimal policy at a sample complexity of order $widetilde{O}(mathrm{Poly}(S,A,H)/(varepsilon^2 N^{mathrm{E}}))$ in finite and $widetilde{O}(mathrm{Poly}(d,H)/(varepsilon^2 N^{mathrm{E}}))$ in linear Markov decision processes, where $varepsilon$ is the target precision, $H$ the horizon, $A$ the number of action, $S$ the number of states in the finite case and $d$ the dimension of the feature space in the linear case. As a by-product, we provide tight convergence guarantees for the behaviour cloning procedure under general assumptions on the policy classes. Additionally, we establish that demonstration-regularized methods are provably efficient for reinforcement learning from human feedback (RLHF). In this respect, we provide theoretical evidence showing the benefits of KL-regularization for RLHF in tabular and linear MDPs. Interestingly, we avoid pessimism injection by employing computationally feasible regularization to handle reward estimation uncertainty, thus setting our approach apart from the prior works.
Read more6/11/2024
0
Give Me an Example Like This: Episodic Active Reinforcement Learning from Demonstrations
Muhan Hou, Koen Hindriks, A. E. Eiben, Kim Baraka
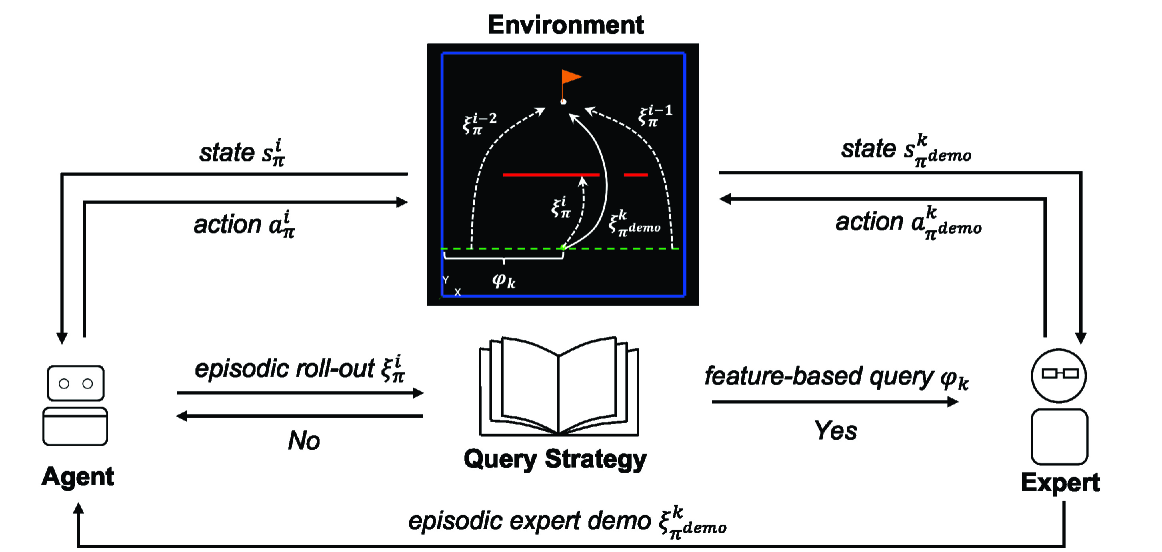
Reinforcement Learning (RL) has achieved great success in sequential decision-making problems, but often at the cost of a large number of agent-environment interactions. To improve sample efficiency, methods like Reinforcement Learning from Expert Demonstrations (RLED) introduce external expert demonstrations to facilitate agent exploration during the learning process. In practice, these demonstrations, which are often collected from human users, are costly and hence often constrained to a limited amount. How to select the best set of human demonstrations that is most beneficial for learning therefore becomes a major concern. This paper presents EARLY (Episodic Active Learning from demonstration querY), an algorithm that enables a learning agent to generate optimized queries of expert demonstrations in a trajectory-based feature space. Based on a trajectory-level estimate of uncertainty in the agent's current policy, EARLY determines the optimized timing and content for feature-based queries. By querying episodic demonstrations as opposed to isolated state-action pairs, EARLY improves the human teaching experience and achieves better learning performance. We validate the effectiveness of our method in three simulated navigation tasks of increasing difficulty. The results show that our method is able to achieve expert-level performance for all three tasks with convergence over 30% faster than other baseline methods when demonstrations are generated by simulated oracle policies. The results of a follow-up pilot user study (N=18) further validate that our method can still maintain a significantly better convergence in the case of human expert demonstrators while achieving a better user experience in perceived task load and consuming significantly less human time.
Read more6/10/2024

0
Countering Reward Over-optimization in LLM with Demonstration-Guided Reinforcement Learning
Mathieu Rita, Florian Strub, Rahma Chaabouni, Paul Michel, Emmanuel Dupoux, Olivier Pietquin
While Reinforcement Learning (RL) has been proven essential for tuning large language models (LLMs), it can lead to reward over-optimization (ROO). Existing approaches address ROO by adding KL regularization, requiring computationally expensive hyperparameter tuning. Additionally, KL regularization focuses solely on regularizing the language policy, neglecting a potential source of regularization: the reward function itself. Inspired by demonstration-guided RL, we here introduce the Reward Calibration from Demonstration (RCfD), which leverages human demonstrations and a reward model to recalibrate the reward objective. Formally, given a prompt, the RCfD objective minimizes the distance between the demonstrations' and LLM's rewards rather than directly maximizing the reward function. This objective shift avoids incentivizing the LLM to exploit the reward model and promotes more natural and diverse language generation. We show the effectiveness of RCfD on three language tasks, which achieves comparable performance to carefully tuned baselines while mitigating ROO.
Read more5/1/2024
🏅
0
Convergence of a model-free entropy-regularized inverse reinforcement learning algorithm
Titouan Renard, Andreas Schlaginhaufen, Tingting Ni, Maryam Kamgarpour
Given a dataset of expert demonstrations, inverse reinforcement learning (IRL) aims to recover a reward for which the expert is optimal. This work proposes a model-free algorithm to solve entropy-regularized IRL problem. In particular, we employ a stochastic gradient descent update for the reward and a stochastic soft policy iteration update for the policy. Assuming access to a generative model, we prove that our algorithm is guaranteed to recover a reward for which the expert is $varepsilon$-optimal using $mathcal{O}(1/varepsilon^{2})$ samples of the Markov decision process (MDP). Furthermore, with $mathcal{O}(1/varepsilon^{4})$ samples we prove that the optimal policy corresponding to the recovered reward is $varepsilon$-close to the expert policy in total variation distance.
Read more4/24/2024