Give Me an Example Like This: Episodic Active Reinforcement Learning from Demonstrations

0
Sign in to get full access
Overview
- This paper presents an "episodic active reinforcement learning" (EARL) approach to enable AI agents to learn from human demonstrations in an interactive and adaptive manner.
- The key idea is to allow the agent to actively request demonstrations of specific behaviors from a human, rather than passively observing a fixed set of demonstrations.
- This allows the agent to focus its learning on the most informative examples, leading to more efficient and effective skill acquisition.
Plain English Explanation
The researchers developed a new way for AI agents to learn from watching humans perform tasks. Typically, an AI agent is shown a fixed set of demonstrations and has to learn from that. But in this approach, the AI agent can actively ask the human to show it specific examples that it thinks will be most helpful for learning.
This is like a student asking their teacher for examples that will help them understand a concept better, rather than just passively watching the teacher demonstrate things. By being able to request the most informative examples, the AI agent can learn more efficiently and effectively.
For example, imagine an AI robot learning to make coffee. Instead of just watching a person make coffee a few times, the robot could ask the person to show it how to handle the coffee pot in different ways, or how to adjust the grind size. This allows the robot to hone in on the key skills it needs to master, rather than wasting time on parts of the task it already understands.
The internal link method allows the AI to actively shape its own learning process, rather than passively receiving demonstrations. This "human-in-the-loop" approach internal link leverages the unique capabilities of both the human and the AI to learn more effectively together.
Technical Explanation
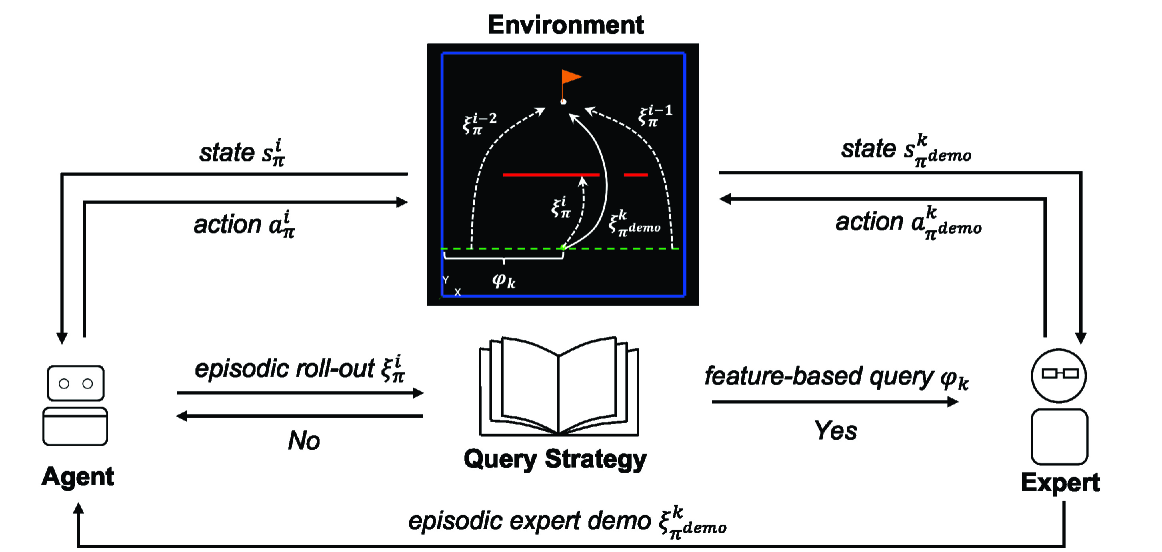
The core of the EARL approach is an interactive learning framework where the AI agent can request specific demonstrations from a human teacher. This is in contrast to the typical "passive observation" paradigm where the agent simply observes a fixed set of demonstrations.
The agent uses a reward prediction model to estimate how informative a potential demonstration would be for improving its skills. It then actively selects which demonstrations to request from the human based on this predicted reward. This allows the agent to focus its learning on the most beneficial examples.
The paper demonstrates EARL in the context of simulated robotic manipulation tasks. The results show that this active learning approach leads to faster skill acquisition compared to passive observation, as the agent is able to efficiently target the most useful demonstrations.
The internal link framework also incorporates elements of inverse reinforcement learning, where the agent tries to infer the underlying reward function that guides the human's demonstrations. This allows the agent to generalize the learned skills beyond the specific examples shown.
Overall, the EARL approach represents an important step towards more natural and efficient human-agent interaction internal link in the context of skill learning and knowledge transfer.
Critical Analysis
One potential limitation of the EARL approach is that it relies on the human teacher being able to provide high-quality, informative demonstrations on demand. In real-world settings, humans may not always be able to perfectly demonstrate the exact behavior the agent is requesting.
The paper acknowledges this challenge and suggests that techniques like internal link "demonstration expansion" could help address it. However, further research is needed to fully understand the robustness of EARL in the face of imperfect human demonstrations.
Additionally, the current EARL framework assumes a single human teacher. Extending this to handle multiple, potentially contradictory human teachers could be an interesting area for future work. Dealing with human biases and ensuring the agent learns general, unbiased skills would also be an important consideration.
Overall, the EARL approach represents a promising step forward in enabling more natural and efficient human-agent collaboration for skill learning. Addressing the challenges around handling imperfect or inconsistent human demonstrations will be key to realizing the full potential of this interactive learning paradigm.
Conclusion
This paper introduces an "episodic active reinforcement learning" (EARL) framework that allows AI agents to actively request demonstrations from human teachers, rather than passively observing a fixed set of examples. This interactive approach enables more efficient and effective skill acquisition, as the agent can focus its learning on the most informative demonstrations.
The results demonstrate the benefits of this human-in-the-loop learning paradigm, which combines the strengths of human domain knowledge and AI's ability to rapidly learn from data. As AI systems become more prevalent in our lives, developing techniques like EARL that facilitate natural and productive collaboration between humans and machines will be crucial.
While the current EARL framework has some limitations, particularly around handling imperfect human demonstrations, the core idea represents an important step towards more intuitive and effective human-agent interaction. Further research in this direction has the potential to unlock new frontiers in AI-powered skill learning and knowledge transfer.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Give Me an Example Like This: Episodic Active Reinforcement Learning from Demonstrations
Muhan Hou, Koen Hindriks, A. E. Eiben, Kim Baraka
Reinforcement Learning (RL) has achieved great success in sequential decision-making problems, but often at the cost of a large number of agent-environment interactions. To improve sample efficiency, methods like Reinforcement Learning from Expert Demonstrations (RLED) introduce external expert demonstrations to facilitate agent exploration during the learning process. In practice, these demonstrations, which are often collected from human users, are costly and hence often constrained to a limited amount. How to select the best set of human demonstrations that is most beneficial for learning therefore becomes a major concern. This paper presents EARLY (Episodic Active Learning from demonstration querY), an algorithm that enables a learning agent to generate optimized queries of expert demonstrations in a trajectory-based feature space. Based on a trajectory-level estimate of uncertainty in the agent's current policy, EARLY determines the optimized timing and content for feature-based queries. By querying episodic demonstrations as opposed to isolated state-action pairs, EARLY improves the human teaching experience and achieves better learning performance. We validate the effectiveness of our method in three simulated navigation tasks of increasing difficulty. The results show that our method is able to achieve expert-level performance for all three tasks with convergence over 30% faster than other baseline methods when demonstrations are generated by simulated oracle policies. The results of a follow-up pilot user study (N=18) further validate that our method can still maintain a significantly better convergence in the case of human expert demonstrators while achieving a better user experience in perceived task load and consuming significantly less human time.
Read more6/10/2024
🌀
0
Demonstration-Regularized RL
Daniil Tiapkin, Denis Belomestny, Daniele Calandriello, Eric Moulines, Alexey Naumov, Pierre Perrault, Michal Valko, Pierre Menard
Incorporating expert demonstrations has empirically helped to improve the sample efficiency of reinforcement learning (RL). This paper quantifies theoretically to what extent this extra information reduces RL's sample complexity. In particular, we study the demonstration-regularized reinforcement learning that leverages the expert demonstrations by KL-regularization for a policy learned by behavior cloning. Our findings reveal that using $N^{mathrm{E}}$ expert demonstrations enables the identification of an optimal policy at a sample complexity of order $widetilde{O}(mathrm{Poly}(S,A,H)/(varepsilon^2 N^{mathrm{E}}))$ in finite and $widetilde{O}(mathrm{Poly}(d,H)/(varepsilon^2 N^{mathrm{E}}))$ in linear Markov decision processes, where $varepsilon$ is the target precision, $H$ the horizon, $A$ the number of action, $S$ the number of states in the finite case and $d$ the dimension of the feature space in the linear case. As a by-product, we provide tight convergence guarantees for the behaviour cloning procedure under general assumptions on the policy classes. Additionally, we establish that demonstration-regularized methods are provably efficient for reinforcement learning from human feedback (RLHF). In this respect, we provide theoretical evidence showing the benefits of KL-regularization for RLHF in tabular and linear MDPs. Interestingly, we avoid pessimism injection by employing computationally feasible regularization to handle reward estimation uncertainty, thus setting our approach apart from the prior works.
Read more6/11/2024

0
New!Extended Reality System for Robotic Learning from Human Demonstration
Isaac Ngui, Courtney McBeth, Grace He, Andr'e Corr^ea Santos, Luciano Soares, Marco Morales, Nancy M. Amato
Many real-world tasks are intuitive for a human to perform, but difficult to encode algorithmically when utilizing a robot to perform the tasks. In these scenarios, robotic systems can benefit from expert demonstrations to learn how to perform each task. In many settings, it may be difficult or unsafe to use a physical robot to provide these demonstrations, for example, considering cooking tasks such as slicing with a knife. Extended reality provides a natural setting for demonstrating robotic trajectories while bypassing safety concerns and providing a broader range of interaction modalities. We propose the Robot Action Demonstration in Extended Reality (RADER) system, a generic extended reality interface for learning from demonstration. We additionally present its application to an existing state-of-the-art learning from demonstration approach and show comparable results between demonstrations given on a physical robot and those given using our extended reality system.
Read more9/20/2024

0
Reverse Forward Curriculum Learning for Extreme Sample and Demonstration Efficiency in Reinforcement Learning
Stone Tao, Arth Shukla, Tse-kai Chan, Hao Su
Reinforcement learning (RL) presents a promising framework to learn policies through environment interaction, but often requires an infeasible amount of interaction data to solve complex tasks from sparse rewards. One direction includes augmenting RL with offline data demonstrating desired tasks, but past work often require a lot of high-quality demonstration data that is difficult to obtain, especially for domains such as robotics. Our approach consists of a reverse curriculum followed by a forward curriculum. Unique to our approach compared to past work is the ability to efficiently leverage more than one demonstration via a per-demonstration reverse curriculum generated via state resets. The result of our reverse curriculum is an initial policy that performs well on a narrow initial state distribution and helps overcome difficult exploration problems. A forward curriculum is then used to accelerate the training of the initial policy to perform well on the full initial state distribution of the task and improve demonstration and sample efficiency. We show how the combination of a reverse curriculum and forward curriculum in our method, RFCL, enables significant improvements in demonstration and sample efficiency compared against various state-of-the-art learning-from-demonstration baselines, even solving previously unsolvable tasks that require high precision and control.
Read more5/7/2024