Demystifying Datapath Accelerator Enhanced Off-path SmartNIC

0
🧪
Sign in to get full access
Overview
- Cloud applications are evolving rapidly, pushing the limits of traditional network processing hardware.
- SmartNICs are introduced to offload network tasks, but their embedded processors have limited capabilities.
- Programmable datapath accelerators (DPAs) are needed to process network traffic at line rate.
- However, there is limited understanding of DPA's performance characteristics.
Plain English Explanation
Network speeds in the cloud are growing quickly, so specialized network interface cards called SmartNICs are introduced to handle network processing tasks. This helps take the load off the main computer processors.
However, typical SmartNICs like BlueFied-2 can only handle simple control-plane tasks with their limited embedded processors. Cloud applications are evolving rapidly, so the fixed hardware in these SmartNICs can't keep up with the changing needs.
To address this, SmartNIC designers are adding programmable datapath accelerators (DPAs) that can process network traffic at high speeds. But there hasn't been much research into how well these DPAs actually perform.
Technical Explanation
This paper presents the first in-depth architectural analysis of the DPA in the latest BlueFied-3 (BF3) SmartNIC. The evaluation shows that the DPA is significantly less powerful than the Arm processor and host CPU also present in the SmartNIC.
However, the researchers identify three unique architectural characteristics of the DPA that can be leveraged to unleash its performance potential:
- Computing: The DPA has specialized instructions and a high-throughput execution pipeline.
- Networking: The DPA is tightly integrated with the network hardware for low-latency packet processing.
- Memory: The DPA has dedicated high-bandwidth memory, separate from the main system memory.
The paper then proposes three guidelines for programmers to take full advantage of these DPA capabilities:
- Leverage specialized DPA instructions to accelerate computation-heavy tasks.
- Offload network processing to the DPA to minimize latency.
- Optimize memory access patterns to maximize the DPA's high-bandwidth memory.
To demonstrate the effectiveness of these guidelines, the researchers conduct case studies, showing up to a 4.3x throughput improvement for a key-value aggregation workload.
Critical Analysis
The paper provides a valuable architectural characterization of a real-world DPA implementation, which can guide future SmartNIC and DPA design. However, the research is limited to a single DPA design (BF3), and it's unclear how generalizable the insights are to other DPA architectures.
Additionally, the paper does not address potential limitations or challenges in applying the proposed guidelines in practice. For example, it's unclear how complex it is for programmers to leverage the DPA's specialized instructions or optimize memory access patterns.
Further research could explore DPA performance across a wider range of workloads and cloud applications, as well as investigate the practical implications of programming for DPA-based SmartNICs in real-world settings.
Conclusion
This paper presents the first in-depth analysis of the architectural characteristics of a programmable datapath accelerator (DPA) in the latest BlueFied-3 SmartNIC. The researchers identify three unique DPA capabilities and propose guidelines for programmers to fully unleash the DPA's performance potential.
These insights can inform the design of future SmartNICs and DPAs, as well as guide programmers in effectively leveraging these emerging hardware accelerators to meet the evolving demands of cloud applications. However, further research is needed to understand the broader applicability and practical implications of these findings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧪
0
Demystifying Datapath Accelerator Enhanced Off-path SmartNIC
Xuzheng Chen, Jie Zhang, Ting Fu, Yifan Shen, Shu Ma, Kun Qian, Lingjun Zhu, Chao Shi, Yin Zhang, Ming Liu, Zeke Wang
Network speeds grow quickly in the modern cloud, so SmartNICs are introduced to offload network processing tasks, even application logic. However, typical multicore SmartNICs such as BlueFiled-2 are only capable of processing control-plane tasks with their embedded processors that have limited memory bandwidth and computing power. On the other hand, cloud applications evolve rapidly, such that a limited number of fixed hardware engines in a SmartNIC cannot satisfy the requirements of cloud applications. Therefore, SmartNIC programmers call for a programmable datapath accelerator (DPA) to process network traffic at line rate. However, no existing work has unveiled the performance characteristics of the existing DPA. To this end, we present the first architectural characterization of the latest DPA-enhanced BlueFiled-3 (BF3) SmartNIC. Our evaluation results indicate that BF3's DPA is significantly wimpier than the off-path Arm processor and the host CPU. However, we still identify that DPA has three unique architectural characteristics that unleash the performance potential of DPA. Specifically, we demonstrate how to take advantage of DPA's three architectural characteristics regarding computing, networking, and memory subsystems. Then we propose three important guidelines for programmers to fully unleash the potential of DPA. To demonstrate the effectiveness of our approach, we conduct detailed case studies regarding each guideline. Our case study on key-value aggregation achieves up to 4.3$times$ higher throughput by using our guidelines to optimize memory combinations.
Read more9/10/2024

0
Advancements in Traffic Processing Using Programmable Hardware Flow Offload
Luca Deri, Alfredo Cardigliano, Francesco Fusco
The exponential growth of data traffic and the increasing complexity of networked applications demand effective solutions capable of passively inspecting and analysing the network traffic for monitoring and security purposes. Implementing network probes in software using general-purpose operating systems has been made possible by advances in packet-capture technologies, such as kernel-bypass frameworks, and by multi-queue adapters designed to distribute the network workload in multi-core processors. Modern SmartNICs, in addition, have introduced stateful mechanisms to associate actions to network flows such as forwarding packets or updating traffic statistics for an individual flow. In this paper, we describe our experience in exploiting those functionalities in a modern network probe and we perform a detailed study of the performance characteristics under different scenarios. Compared to pure CPU-based solutions, SmartNICs with flow-offload technologies provide substantial benefits when implementing forwarding applications. However, the main limitation of having to keep large flow tables in the host memory remains largely unsolved for realistic monitoring and security applications.
Read more7/24/2024

0
A Comprehensive Survey on SmartNICs: Architectures, Development Models, Applications, and Research Directions
Elie Kfoury, Samia Choueiri, Ali Mazloum, Ali AlSabeh, Jose Gomez, Jorge Crichigno
The end of Moore's Law and Dennard Scaling has slowed processor improvements in the past decade. While multi-core processors have improved performance, they are limited by the application's level of parallelism, as prescribed by Amdahl's Law. This has led to the emergence of domain-specific processors that specialize in a narrow range of functions. Smart Network Interface Cards (SmartNICs) can be seen as an evolutionary technology that combines heterogeneous domain-specific processors and general-purpose cores to offload infrastructure tasks. Despite the impressive advantages of SmartNICs and their importance in modern networks, the literature has been missing a comprehensive survey. To this end, this paper provides a background encompassing an overview of the evolution of NICs from basic to SmartNICs, describing their architectures, development environments, and advantages over legacy NICs. The paper then presents a comprehensive taxonomy of applications offloaded to SmartNICs, covering network, security, storage, and machine learning functions. Challenges associated with SmartNIC development and deployment are discussed, along with current initiatives and open research issues.
Read more5/16/2024
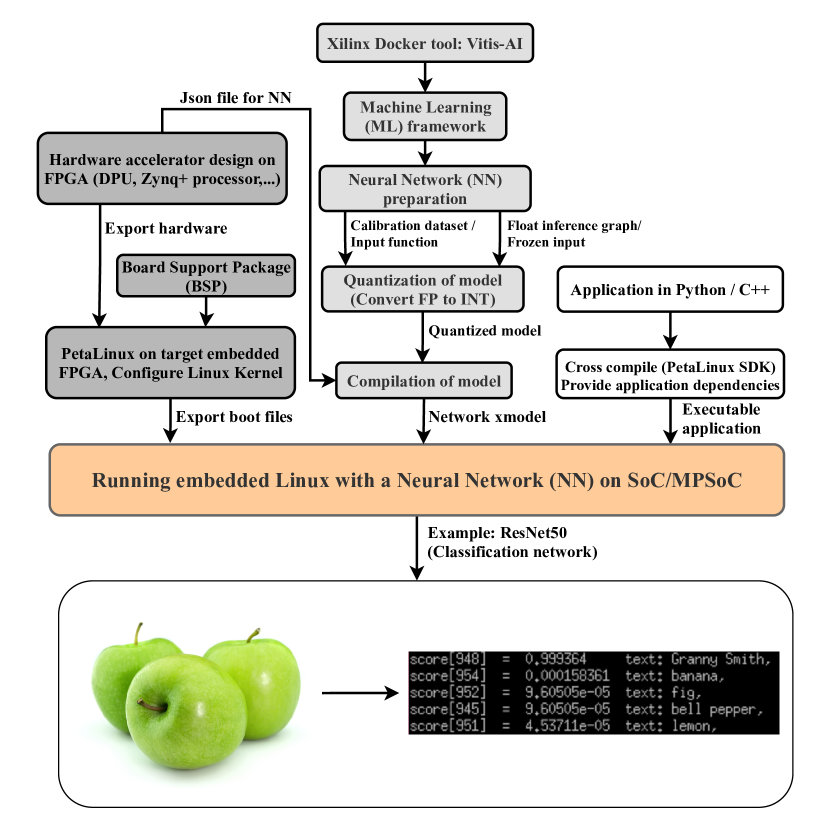
0
Latency optimized Deep Neural Networks (DNNs): An Artificial Intelligence approach at the Edge using Multiprocessor System on Chip (MPSoC)
Seyed Nima Omidsajedi, Rekha Reddy, Jianming Yi, Jan Herbst, Christoph Lipps, Hans Dieter Schotten
Almost in every heavily computation-dependent application, from 6G communication systems to autonomous driving platforms, a large portion of computing should be near to the client side. Edge computing (AI at Edge) in mobile devices is one of the optimized approaches for addressing this requirement. Therefore, in this work, the possibilities and challenges of implementing a low-latency and power-optimized smart mobile system are examined. Utilizing Field Programmable Gate Array (FPGA) based solutions at the edge will lead to bandwidth-optimized designs and as a consequence can boost the computational effectiveness at a system-level deadline. Moreover, various performance aspects and implementation feasibilities of Neural Networks (NNs) on both embedded FPGA edge devices (using Xilinx Multiprocessor System on Chip (MPSoC)) and Cloud are discussed throughout this research. The main goal of this work is to demonstrate a hybrid system that uses the deep learning programmable engine developed by Xilinx Inc. as the main component of the hardware accelerator. Then based on this design, an efficient system for mobile edge computing is represented by utilizing an embedded solution.
Read more7/29/2024