Latency optimized Deep Neural Networks (DNNs): An Artificial Intelligence approach at the Edge using Multiprocessor System on Chip (MPSoC)

0
Sign in to get full access
Overview
- Edge computing platforms enable running AI models at the edge, close to where data is generated
- Multiprocessor System on Chip (MPSoC) is an edge computing platform that combines multiple processors on a single chip
- This paper explores optimizing Deep Neural Networks (DNNs) for low-latency inference on MPSoC platforms
Plain English Explanation
In this paper, the researchers investigate ways to optimize Deep Neural Networks (DNNs) for low-latency inference on edge computing platforms. Specifically, they focus on Multiprocessor System on Chip (MPSoC) devices, which combine multiple processors on a single chip to enable AI processing close to where data is generated.
The key challenge is balancing the high computational requirements of DNNs with the resource constraints of edge devices. The researchers explore techniques to optimize DNN models and their deployment on MPSoC platforms to achieve low-latency, energy-efficient inference. This could enable a wide range of real-time applications at the edge, such as autonomous vehicles, smart home systems, and industrial automation.
Technical Explanation
The paper presents a comprehensive approach to optimizing DNN inference on MPSoC platforms. The researchers first develop a framework for modeling the performance and resource utilization of DNN models on MPSoC. This allows them to explore different DNN architectures and deployment strategies to meet latency and efficiency requirements.
They then propose several optimization techniques, including model compression, hardware-aware architecture search, and dynamic load balancing across the MPSoC's heterogeneous processors. These techniques are evaluated on a range of DNN models and MPSoC platforms, demonstrating significant improvements in latency and energy efficiency compared to baseline approaches.
Critical Analysis
The paper provides a comprehensive and well-designed study on optimizing DNN inference for edge computing platforms. The researchers have identified a critical challenge in the field and presented a systematic approach to address it.
One potential limitation is the reliance on specific MPSoC platforms and DNN models in the experiments. While the techniques are likely generalizable, further validation on a broader range of edge devices and application domains would strengthen the claims.
Additionally, the paper could have delved deeper into the trade-offs and design considerations involved in the optimization process. For example, how do the different techniques balance factors like accuracy, latency, and energy consumption, and how can developers make informed decisions based on their specific requirements?
Conclusion
This research represents an important step towards enabling efficient edge AI by optimizing DNN inference on MPSoC platforms. The proposed techniques can unlock the potential of edge computing for a wide range of real-time applications, from autonomous vehicles to smart home systems. As edge devices continue to play a larger role in our lives, innovations like those presented in this paper will be crucial for delivering powerful, responsive, and energy-efficient AI capabilities at the edge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Latency optimized Deep Neural Networks (DNNs): An Artificial Intelligence approach at the Edge using Multiprocessor System on Chip (MPSoC)
Seyed Nima Omidsajedi, Rekha Reddy, Jianming Yi, Jan Herbst, Christoph Lipps, Hans Dieter Schotten
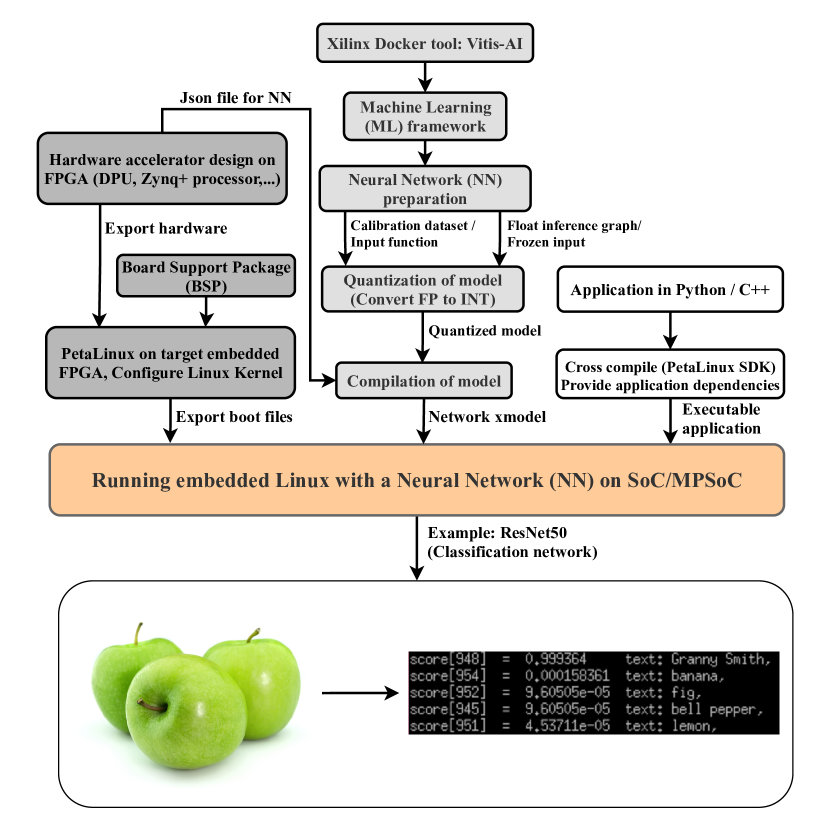
Almost in every heavily computation-dependent application, from 6G communication systems to autonomous driving platforms, a large portion of computing should be near to the client side. Edge computing (AI at Edge) in mobile devices is one of the optimized approaches for addressing this requirement. Therefore, in this work, the possibilities and challenges of implementing a low-latency and power-optimized smart mobile system are examined. Utilizing Field Programmable Gate Array (FPGA) based solutions at the edge will lead to bandwidth-optimized designs and as a consequence can boost the computational effectiveness at a system-level deadline. Moreover, various performance aspects and implementation feasibilities of Neural Networks (NNs) on both embedded FPGA edge devices (using Xilinx Multiprocessor System on Chip (MPSoC)) and Cloud are discussed throughout this research. The main goal of this work is to demonstrate a hybrid system that uses the deep learning programmable engine developed by Xilinx Inc. as the main component of the hardware accelerator. Then based on this design, an efficient system for mobile edge computing is represented by utilizing an embedded solution.
Read more7/29/2024
🧠
0
Efficient Edge AI: Deploying Convolutional Neural Networks on FPGA with the Gemmini Accelerator
Federico Nicolas Peccia, Svetlana Pavlitska, Tobias Fleck, Oliver Bringmann
The growing concerns regarding energy consumption and privacy have prompted the development of AI solutions deployable on the edge, circumventing the substantial CO2 emissions associated with cloud servers and mitigating risks related to sharing sensitive data. But deploying Convolutional Neural Networks (CNNs) on non-off-the-shelf edge devices remains a complex and labor-intensive task. In this paper, we present and end-to-end workflow for deployment of CNNs on Field Programmable Gate Arrays (FPGAs) using the Gemmini accelerator, which we modified for efficient implementation on FPGAs. We describe how we leverage the use of open source software on each optimization step of the deployment process, the customizations we added to them and its impact on the final system's performance. We were able to achieve real-time performance by deploying a YOLOv7 model on a Xilinx ZCU102 FPGA with an energy efficiency of 36.5 GOP/s/W. Our FPGA-based solution demonstrates superior power efficiency compared with other embedded hardware devices, and even outperforms other FPGA reference implementations. Finally, we present how this kind of solution can be integrated into a wider system, by testing our proposed platform in a traffic monitoring scenario.
Read more8/15/2024

0
New!Distributed Convolutional Neural Network Training on Mobile and Edge Clusters
Pranav Rama, Madison Threadgill, Andreas Gerstlauer
The training of deep and/or convolutional neural networks (DNNs/CNNs) is traditionally done on servers with powerful CPUs and GPUs. Recent efforts have emerged to localize machine learning tasks fully on the edge. This brings advantages in reduced latency and increased privacy, but necessitates working with resource-constrained devices. Approaches for inference and training in mobile and edge devices based on pruning, quantization or incremental and transfer learning require trading off accuracy. Several works have explored distributing inference operations on mobile and edge clusters instead. However, there is limited literature on distributed training on the edge. Existing approaches all require a central, potentially powerful edge or cloud server for coordination or offloading. In this paper, we describe an approach for distributed CNN training exclusively on mobile and edge devices. Our approach is beneficial for the initial CNN layers that are feature map dominated. It is based on partitioning forward inference and back-propagation operations among devices through tiling and fusing to maximize locality and expose communication and memory-aware parallelism. We also introduce the concept of layer grouping to further fine-tune performance based on computation and communication trade-off. Results show that for a cluster of 2-6 quad-core Raspberry Pi3 devices, training of an object-detection CNN provides a 2x-15x speedup with respect to a single core and up to 8x reduction in memory usage per device, all without sacrificing accuracy. Grouping offers up to 1.5x speedup depending on the reference profile and batch size.
Read more9/17/2024
🤯
0
Embedded Distributed Inference of Deep Neural Networks: A Systematic Review
Federico Nicol'as Peccia, Oliver Bringmann
Embedded distributed inference of Neural Networks has emerged as a promising approach for deploying machine-learning models on resource-constrained devices in an efficient and scalable manner. The inference task is distributed across a network of embedded devices, with each device contributing to the overall computation by performing a portion of the workload. In some cases, more powerful devices such as edge or cloud servers can be part of the system to be responsible of the most demanding layers of the network. As the demand for intelligent systems and the complexity of the deployed neural network models increases, this approach is becoming more relevant in a variety of applications such as robotics, autonomous vehicles, smart cities, Industry 4.0 and smart health. We present a systematic review of papers published during the last six years which describe techniques and methods to distribute Neural Networks across these kind of systems. We provide an overview of the current state-of-the-art by analysing more than 100 papers, present a new taxonomy to characterize them, and discuss trends and challenges in the field.
Read more5/7/2024