Demystifying Verbatim Memorization in Large Language Models

0
Sign in to get full access
Overview
- Examines verbatim memorization in large language models
- Investigates the extent to which models memorize their training data verbatim
- Proposes methods to measure and understand this phenomenon
Plain English Explanation
Large language models like GPT-3 have become incredibly powerful at tasks like text generation, translation, and question answering. However, there are concerns that these models may simply be memorizing large portions of their training data, rather than learning general patterns and rules.
This paper aims to demystify the extent of verbatim memorization in these large language models. The researchers develop techniques to measure how much a model has memorized from its training data, rather than learning more general knowledge. They find that while models do exhibit some degree of verbatim memorization, this is not the primary way they achieve their impressive performance. Instead, the models seem to be learning patterns and rules that allow them to generalize well to new, unseen data.
Understanding the balance between memorization and generalization is crucial, as it helps us better comprehend the inner workings of these powerful AI systems. It also allows us to identify potential privacy and security risks if models are simply regurgitating verbatim snippets of their training data. Overall, this research provides important insights into the capabilities and limitations of large language models.
Technical Explanation
The paper proposes several methods to measure verbatim memorization in large language models:
-
Nearest Neighbor Retrieval: This involves querying the model with a passage from its training data and seeing how similar the model's output is to that original passage. A high degree of similarity would indicate verbatim memorization.
-
Unique N-gram Recall: The researchers count the number of unique n-grams (sequences of n words) in the model's training data that are also present in the model's outputs. A high recall of unique n-grams suggests memorization.
-
Textual Retrieval Evaluation: This metric measures how well the model can retrieve the original training text given a query. Strong retrieval performance implies the model has memorized the training data.
Using these techniques, the researchers analyze several large language models, including GPT-2, GPT-3, and T5. They find that while these models do exhibit some degree of verbatim memorization, it is not the dominant factor behind their impressive performance. Instead, the models seem to be learning general patterns and rules that allow them to generalize well to new, unseen data.
The paper also explores the relationship between model size, dataset size, and memorization. Larger models trained on more data tend to exhibit higher levels of verbatim memorization, but this is not a linear relationship. There appear to be diminishing returns as models and datasets grow, suggesting that simply increasing scale may not be the best way to reduce memorization.
Critical Analysis
The paper provides a thoughtful and nuanced analysis of verbatim memorization in large language models. The researchers acknowledge that while some degree of memorization is present, it is not the sole or even primary driver of these models' impressive performance. They also raise important considerations around the privacy and security implications of memorization, such as the potential for models to inadvertently reveal sensitive information from their training data.
However, one potential limitation of the study is that it focuses primarily on text-based memorization, without addressing the potential for models to memorize other types of data, such as images or structured data. Additionally, the paper does not delve deeply into the specific architectural or training factors that may contribute to memorization, which could provide valuable insights for model designers.
Overall, this research represents an important step forward in understanding the capabilities and limitations of large language models. By shedding light on the role of memorization, the paper encourages readers to think critically about the inner workings of these powerful AI systems and to consider the broader implications for privacy, security, and the responsible development of advanced language technologies.
Conclusion
This paper provides a detailed examination of verbatim memorization in large language models, dispelling the notion that these models simply regurgitate their training data. Instead, the researchers find that while some degree of memorization is present, these models are primarily learning general patterns and rules that allow them to generalize well to new, unseen data.
Understanding the balance between memorization and generalization is crucial for the continued development and responsible use of large language models. This research offers valuable insights into the capabilities and limitations of these powerful AI systems, paving the way for more nuanced and thoughtful discussions around their deployment and application in real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Demystifying Verbatim Memorization in Large Language Models
Jing Huang, Diyi Yang, Christopher Potts
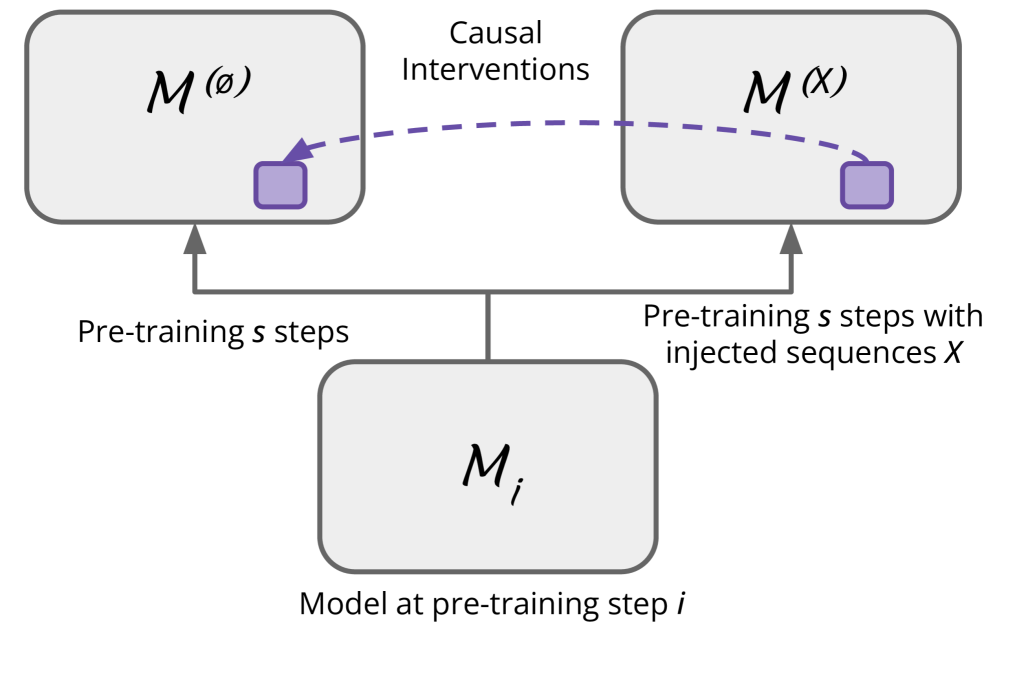
Large Language Models (LLMs) frequently memorize long sequences verbatim, often with serious legal and privacy implications. Much prior work has studied such verbatim memorization using observational data. To complement such work, we develop a framework to study verbatim memorization in a controlled setting by continuing pre-training from Pythia checkpoints with injected sequences. We find that (1) non-trivial amounts of repetition are necessary for verbatim memorization to happen; (2) later (and presumably better) checkpoints are more likely to verbatim memorize sequences, even for out-of-distribution sequences; (3) the generation of memorized sequences is triggered by distributed model states that encode high-level features and makes important use of general language modeling capabilities. Guided by these insights, we develop stress tests to evaluate unlearning methods and find they often fail to remove the verbatim memorized information, while also degrading the LM. Overall, these findings challenge the hypothesis that verbatim memorization stems from specific model weights or mechanisms. Rather, verbatim memorization is intertwined with the LM's general capabilities and thus will be very difficult to isolate and suppress without degrading model quality.
Read more7/26/2024

0
A Multi-Perspective Analysis of Memorization in Large Language Models
Bowen Chen, Namgi Han, Yusuke Miyao
Large Language Models (LLMs), trained on massive corpora with billions of parameters, show unprecedented performance in various fields. Though surprised by their excellent performances, researchers also noticed some special behaviors of those LLMs. One of those behaviors is memorization, in which LLMs can generate the same content used to train them. Though previous research has discussed memorization, the memorization of LLMs still lacks explanation, especially the cause of memorization and the dynamics of generating them. In this research, we comprehensively discussed memorization from various perspectives and extended the discussion scope to not only just the memorized content but also less and unmemorized content. Through various studies, we found that: (1) Through experiments, we revealed the relation of memorization between model size, continuation size, and context size. Further, we showed how unmemorized sentences transition to memorized sentences. (2) Through embedding analysis, we showed the distribution and decoding dynamics across model size in embedding space for sentences with different memorization scores. The n-gram statistics analysis presents d (3) An analysis over n-gram and entropy decoding dynamics discovered a boundary effect when the model starts to generate memorized sentences or unmemorized sentences. (4)We trained a Transformer model to predict the memorization of different models, showing that it is possible to predict memorizations by context.
Read more6/5/2024
💬
0
To Each (Textual Sequence) Its Own: Improving Memorized-Data Unlearning in Large Language Models
George-Octavian Barbulescu, Peter Triantafillou
LLMs have been found to memorize training textual sequences and regurgitate verbatim said sequences during text generation time. This fact is known to be the cause of privacy and related (e.g., copyright) problems. Unlearning in LLMs then takes the form of devising new algorithms that will properly deal with these side-effects of memorized data, while not hurting the model's utility. We offer a fresh perspective towards this goal, namely, that each textual sequence to be forgotten should be treated differently when being unlearned based on its degree of memorization within the LLM. We contribute a new metric for measuring unlearning quality, an adversarial attack showing that SOTA algorithms lacking this perspective fail for privacy, and two new unlearning methods based on Gradient Ascent and Task Arithmetic, respectively. A comprehensive performance evaluation across an extensive suite of NLP tasks then mapped the solution space, identifying the best solutions under different scales in model capacities and forget set sizes and quantified the gains of the new approaches.
Read more5/7/2024

0
Uncovering Latent Memories: Assessing Data Leakage and Memorization Patterns in Large Language Models
Sunny Duan, Mikail Khona, Abhiram Iyer, Rylan Schaeffer, Ila R Fiete
Frontier AI systems are making transformative impacts across society, but such benefits are not without costs: models trained on web-scale datasets containing personal and private data raise profound concerns about data privacy and security. Language models are trained on extensive corpora including potentially sensitive or proprietary information, and the risk of data leakage - where the model response reveals pieces of such information - remains inadequately understood. Prior work has investigated what factors drive memorization and have identified that sequence complexity and the number of repetitions drive memorization. Here, we focus on the evolution of memorization over training. We begin by reproducing findings that the probability of memorizing a sequence scales logarithmically with the number of times it is present in the data. We next show that sequences which are apparently not memorized after the first encounter can be uncovered throughout the course of training even without subsequent encounters, a phenomenon we term latent memorization. The presence of latent memorization presents a challenge for data privacy as memorized sequences may be hidden at the final checkpoint of the model but remain easily recoverable. To this end, we develop a diagnostic test relying on the cross entropy loss to uncover latent memorized sequences with high accuracy.
Read more7/26/2024