Depth Pro: Sharp Monocular Metric Depth in Less Than a Second

0

Sign in to get full access
Overview
- This paper presents a novel monocular depth estimation model called "Depth Pro" that can produce sharp, metric depth maps in under one second.
- The model outperforms existing state-of-the-art methods in both accuracy and inference speed.
- The authors developed specialized network architecture and training strategies to enable this level of performance.
Plain English Explanation
The researchers have created a new computer vision model that can quickly estimate the 3D depth or distance information from a single 2D image. This is known as "monocular depth estimation," and it has many useful applications, such as in robotics, self-driving cars, and augmented reality.
Existing depth estimation models often struggle to produce accurate, high-resolution depth maps quickly. The key innovation in this work is the Depth Pro model, which uses a specialized neural network architecture and training approach to overcome these limitations. Depth Pro can generate sharp, metric (true scale) depth maps in under one second, outperforming previous state-of-the-art methods.
This advance in monocular depth estimation could enable new real-time applications that require fast and accurate 3D scene understanding from a single camera. For example, it could help robots better navigate their environments or allow augmented reality apps to more realistically blend virtual objects into the real world.
Technical Explanation
The authors developed a monocular depth estimation model called Depth Pro that can produce high-quality depth maps in less than a second. This is a significant improvement over existing approaches, which often struggle to achieve both high accuracy and fast inference speed.
The key innovations in Depth Pro are:
- Specialized network architecture: The model uses a novel encoder-decoder structure with spatial pyramid pooling and other custom components to enable efficient and accurate depth estimation.
- Adaptive supervision: The training process adaptively adjusts the loss function to focus on learning sharp depth boundaries and preserving metric scale.
- Self-supervised pre-training: The model is first pre-trained on a large-scale self-supervised depth task before fine-tuning on the target dataset, which boosts performance.
Experimental results show that Depth Pro outperforms previous state-of-the-art monocular depth estimation methods on multiple benchmarks, while also achieving faster inference times of less than one second per image.
Critical Analysis
The Depth Pro paper presents a compelling technical advance in monocular depth estimation, but there are a few potential limitations and areas for further research:
- Dataset bias: The authors train and evaluate Depth Pro on standard depth estimation datasets, but these datasets may not fully capture the diverse real-world scenes that the model would need to handle in practical applications.
- Generalization: While Depth Pro demonstrates strong performance on the tested benchmarks, it's unclear how well the model would generalize to very different environments or task requirements beyond the scope of the paper.
- Hardware dependence: The fast inference speed of Depth Pro is enabled by specialized hardware (e.g., GPU acceleration), so the model's real-world applicability may be limited in scenarios with constrained computational resources.
Overall, the Depth Pro model represents an important technical advancement, but further research is needed to fully understand its practical limitations and potential for real-world deployment.
Conclusion
This paper introduces Depth Pro, a novel monocular depth estimation model that can produce high-quality, metric depth maps in less than a second. By developing a specialized network architecture and training approach, the authors have significantly advanced the state-of-the-art in terms of both accuracy and inference speed for this task.
The ability to quickly and accurately estimate 3D depth information from a single 2D image has many promising applications, such as in robotic navigation, autonomous driving, and augmented reality. While the Depth Pro model shows impressive results, further research is needed to address potential limitations around dataset bias, generalization, and hardware dependence.
Nevertheless, this work represents an important step forward in the field of monocular depth estimation and could enable new real-time 3D perception capabilities in a wide range of computer vision and robotics applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
Aleksei Bochkovskii, Amael Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R. Richter, Vladlen Koltun
We present a foundation model for zero-shot metric monocular depth estimation. Our model, Depth Pro, synthesizes high-resolution depth maps with unparalleled sharpness and high-frequency details. The predictions are metric, with absolute scale, without relying on the availability of metadata such as camera intrinsics. And the model is fast, producing a 2.25-megapixel depth map in 0.3 seconds on a standard GPU. These characteristics are enabled by a number of technical contributions, including an efficient multi-scale vision transformer for dense prediction, a training protocol that combines real and synthetic datasets to achieve high metric accuracy alongside fine boundary tracing, dedicated evaluation metrics for boundary accuracy in estimated depth maps, and state-of-the-art focal length estimation from a single image. Extensive experiments analyze specific design choices and demonstrate that Depth Pro outperforms prior work along multiple dimensions. We release code and weights at https://github.com/apple/ml-depth-pro
Read more10/4/2024
2
Depth Anything V2
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao
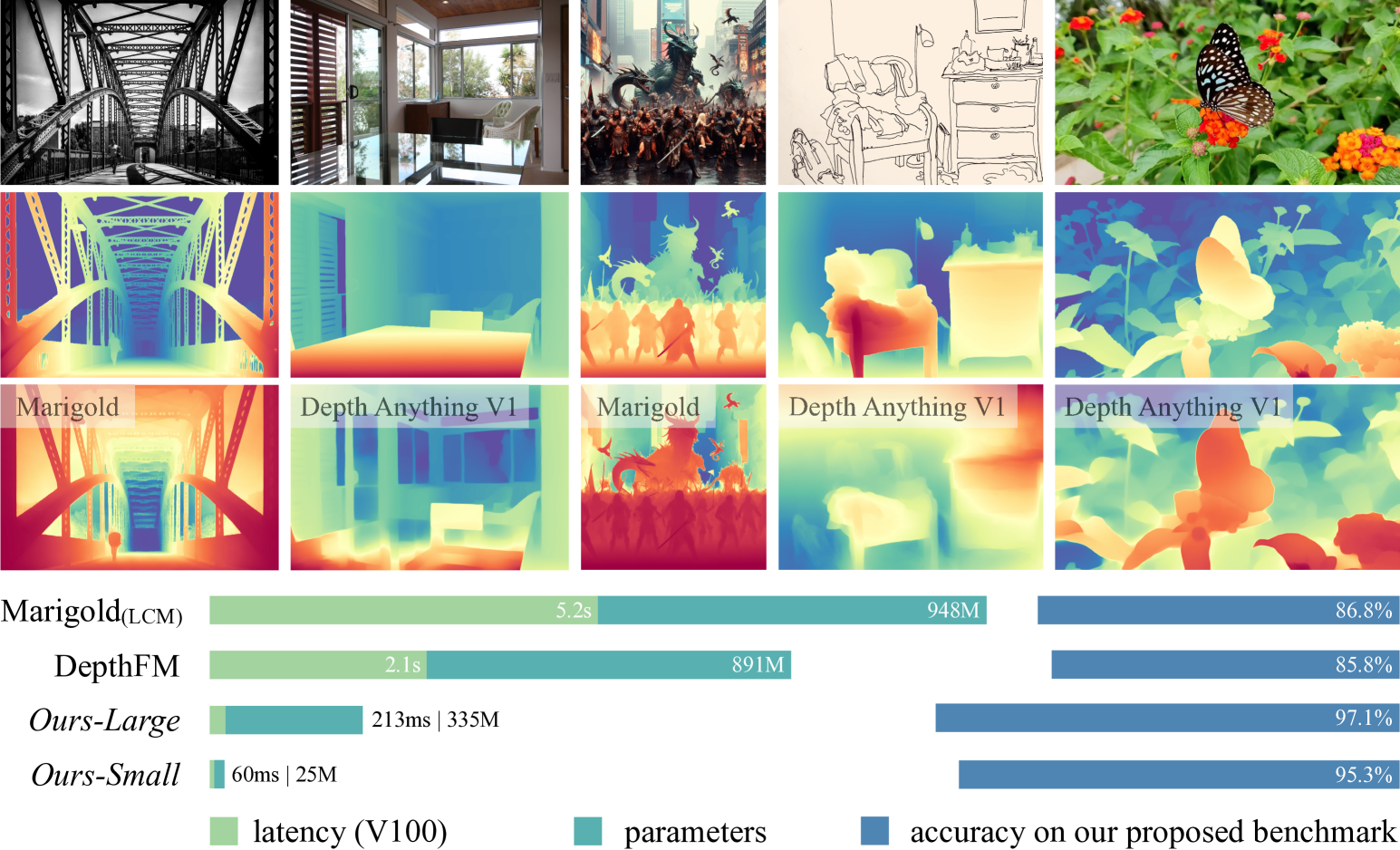
This work presents Depth Anything V2. Without pursuing fancy techniques, we aim to reveal crucial findings to pave the way towards building a powerful monocular depth estimation model. Notably, compared with V1, this version produces much finer and more robust depth predictions through three key practices: 1) replacing all labeled real images with synthetic images, 2) scaling up the capacity of our teacher model, and 3) teaching student models via the bridge of large-scale pseudo-labeled real images. Compared with the latest models built on Stable Diffusion, our models are significantly more efficient (more than 10x faster) and more accurate. We offer models of different scales (ranging from 25M to 1.3B params) to support extensive scenarios. Benefiting from their strong generalization capability, we fine-tune them with metric depth labels to obtain our metric depth models. In addition to our models, considering the limited diversity and frequent noise in current test sets, we construct a versatile evaluation benchmark with precise annotations and diverse scenes to facilitate future research.
Read more6/14/2024
0
Metric3D v2: A Versatile Monocular Geometric Foundation Model for Zero-shot Metric Depth and Surface Normal Estimation
Mu Hu, Wei Yin, Chi Zhang, Zhipeng Cai, Xiaoxiao Long, Hao Chen, Kaixuan Wang, Gang Yu, Chunhua Shen, Shaojie Shen
We introduce Metric3D v2, a geometric foundation model for zero-shot metric depth and surface normal estimation from a single image, which is crucial for metric 3D recovery. While depth and normal are geometrically related and highly complimentary, they present distinct challenges. SoTA monocular depth methods achieve zero-shot generalization by learning affine-invariant depths, which cannot recover real-world metrics. Meanwhile, SoTA normal estimation methods have limited zero-shot performance due to the lack of large-scale labeled data. To tackle these issues, we propose solutions for both metric depth estimation and surface normal estimation. For metric depth estimation, we show that the key to a zero-shot single-view model lies in resolving the metric ambiguity from various camera models and large-scale data training. We propose a canonical camera space transformation module, which explicitly addresses the ambiguity problem and can be effortlessly plugged into existing monocular models. For surface normal estimation, we propose a joint depth-normal optimization module to distill diverse data knowledge from metric depth, enabling normal estimators to learn beyond normal labels. Equipped with these modules, our depth-normal models can be stably trained with over 16 million of images from thousands of camera models with different-type annotations, resulting in zero-shot generalization to in-the-wild images with unseen camera settings. Our method enables the accurate recovery of metric 3D structures on randomly collected internet images, paving the way for plausible single-image metrology. Our project page is at https://JUGGHM.github.io/Metric3Dv2.
Read more8/19/2024

0
SM4Depth: Seamless Monocular Metric Depth Estimation across Multiple Cameras and Scenes by One Model
Yihao Liu, Feng Xue, Anlong Ming, Mingshuai Zhao, Huadong Ma, Nicu Sebe
In the last year, universal monocular metric depth estimation (universal MMDE) has gained considerable attention, serving as the foundation model for various multimedia tasks, such as video and image editing. Nonetheless, current approaches face challenges in maintaining consistent accuracy across diverse scenes without scene-specific parameters and pre-training, hindering the practicality of MMDE. Furthermore, these methods rely on extensive datasets comprising millions, if not tens of millions, of data for training, leading to significant time and hardware expenses. This paper presents SM$^4$Depth, a model that seamlessly works for both indoor and outdoor scenes, without needing extensive training data and GPU clusters. Firstly, to obtain consistent depth across diverse scenes, we propose a novel metric scale modeling, i.e., variation-based unnormalized depth bins. It reduces the ambiguity of the conventional metric bins and enables better adaptation to large depth gaps of scenes during training. Secondly, we propose a divide and conquer solution to reduce reliance on massive training data. Instead of estimating directly from the vast solution space, the metric bins are estimated from multiple solution sub-spaces to reduce complexity. Additionally, we introduce an uncut depth dataset, BUPT Depth, to evaluate the depth accuracy and consistency across various indoor and outdoor scenes. Trained on a consumer-grade GPU using just 150K RGB-D pairs, SM$^4$Depth achieves outstanding performance on the most never-before-seen datasets, especially maintaining consistent accuracy across indoors and outdoors. The code can be found https://github.com/mRobotit/SM4Depth.
Read more8/16/2024