Depth Anything V2
2406.09414
3
0
Abstract
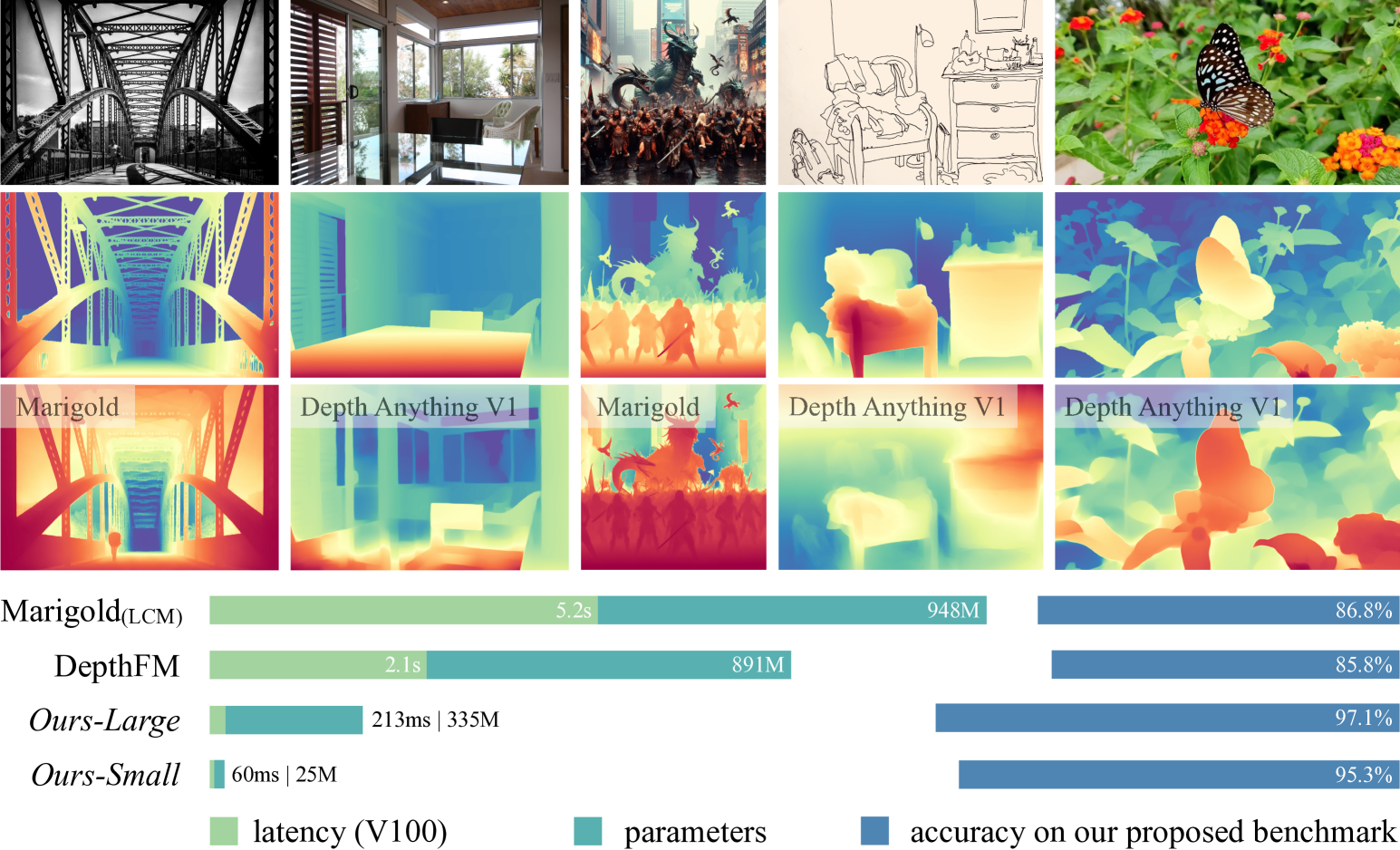
This work presents Depth Anything V2. Without pursuing fancy techniques, we aim to reveal crucial findings to pave the way towards building a powerful monocular depth estimation model. Notably, compared with V1, this version produces much finer and more robust depth predictions through three key practices: 1) replacing all labeled real images with synthetic images, 2) scaling up the capacity of our teacher model, and 3) teaching student models via the bridge of large-scale pseudo-labeled real images. Compared with the latest models built on Stable Diffusion, our models are significantly more efficient (more than 10x faster) and more accurate. We offer models of different scales (ranging from 25M to 1.3B params) to support extensive scenarios. Benefiting from their strong generalization capability, we fine-tune them with metric depth labels to obtain our metric depth models. In addition to our models, considering the limited diversity and frequent noise in current test sets, we construct a versatile evaluation benchmark with precise annotations and diverse scenes to facilitate future research.
Create account to get full access
Overview
- This paper introduces Depth Anything V2, an improved version of the Depth Anything model for monocular depth estimation.
- The key innovations include addressing challenges with using synthetic data and leveraging large-scale unlabeled data to improve the model's performance.
- The paper builds on prior work in repurposing diffusion-based image generators for monocular depth, domain-transferred synthetic data generation, and self-supervised two-frame multi-camera depth estimation.
Plain English Explanation
The paper describes an improved version of a model called Depth Anything, which can estimate the depth or distance of objects in a single image. This is a challenging computer vision task, as depth information is not directly available in a 2D image.
The key innovation in Depth Anything V2 is how it addresses the challenges of using synthetic data to train the model. Synthetic data, generated by computer graphics, can provide a large amount of labeled depth information. However, there can be differences between synthetic and real-world images that limit the model's performance on real data.
To overcome this, the researchers developed new techniques to better leverage large amounts of unlabeled real-world data. By combining this with the synthetic data in a smart way, they were able to create a more robust and accurate depth estimation model.
The paper builds on previous work in related areas, such as using diffusion models (a type of generative AI) to estimate depth, and self-supervised depth estimation from multiple camera views. By incorporating these ideas, the researchers were able to create a more powerful and flexible depth estimation system.
Technical Explanation
The paper first revisits the design of the Depth Anything V1 model, which relied heavily on synthetic data with labeled depth information. While this provided a large training dataset, the researchers identified challenges in using solely synthetic data, as there can be significant differences between synthetic and real-world images.
To address this, the paper introduces several key innovations in Depth Anything V2:
-
Leveraging Large-Scale Unlabeled Data: The researchers developed techniques to effectively utilize large amounts of unlabeled real-world images to complement the synthetic data. This helps the model learn more robust features that generalize better to real-world scenes.
-
Improved Synthetic Data Generation: Building on prior work in domain-transferred synthetic data generation, the researchers enhanced the realism and diversity of the synthetic training data.
-
Repurposing Diffusion Models: Inspired by repurposing diffusion-based image generators for monocular depth, the paper incorporates diffusion models into the depth estimation pipeline to better leverage learned visual representations.
-
Self-Supervised Multi-Camera Depth: The researchers also drew on ideas from self-supervised two-frame multi-camera depth estimation to extract additional depth cues from multiple views of the same scene.
Through extensive experiments, the paper demonstrates that Depth Anything V2 achieves state-of-the-art performance on standard monocular depth estimation benchmarks, outperforming previous methods.
Critical Analysis
The paper provides a comprehensive and well-designed approach to addressing the limitations of the original Depth Anything model. The researchers have thoughtfully incorporated insights from related work to create a more robust and effective depth estimation system.
One potential limitation is the reliance on synthetic data, even with the improvements in domain transfer and data generation. There may still be inherent differences between synthetic and real-world scenes that could limit the model's performance on certain types of images or environments.
Additionally, the paper does not delve deeply into the potential biases or failure modes of the Depth Anything V2 model. It would be valuable to understand how the model performs on a diverse set of real-world scenes, including challenging cases like occluded objects, unusual lighting conditions, or unconventional camera angles.
Further research could also explore ways to make the model more interpretable and explainable, providing insights into how it is making depth predictions and where it may be prone to errors. This could help developers and users better understand the model's strengths and limitations.
Conclusion
The Depth Anything V2 paper presents a significant advancement in monocular depth estimation by addressing key challenges in leveraging synthetic data and incorporating large-scale unlabeled real-world data. The researchers' innovative techniques, such as repurposing diffusion models and self-supervised multi-camera depth estimation, have led to state-of-the-art performance on standard benchmarks.
This work has important implications for a wide range of applications, from augmented reality and robotics to computational photography and autonomous vehicles. By enabling accurate depth estimation from single images, Depth Anything V2 could unlock new capabilities and enhance existing technologies in these domains.
As the field of computer vision continues to evolve, the insights and approaches introduced in this paper will likely influence and inspire future research, pushing the boundaries of what's possible in monocular depth estimation and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao
0
0
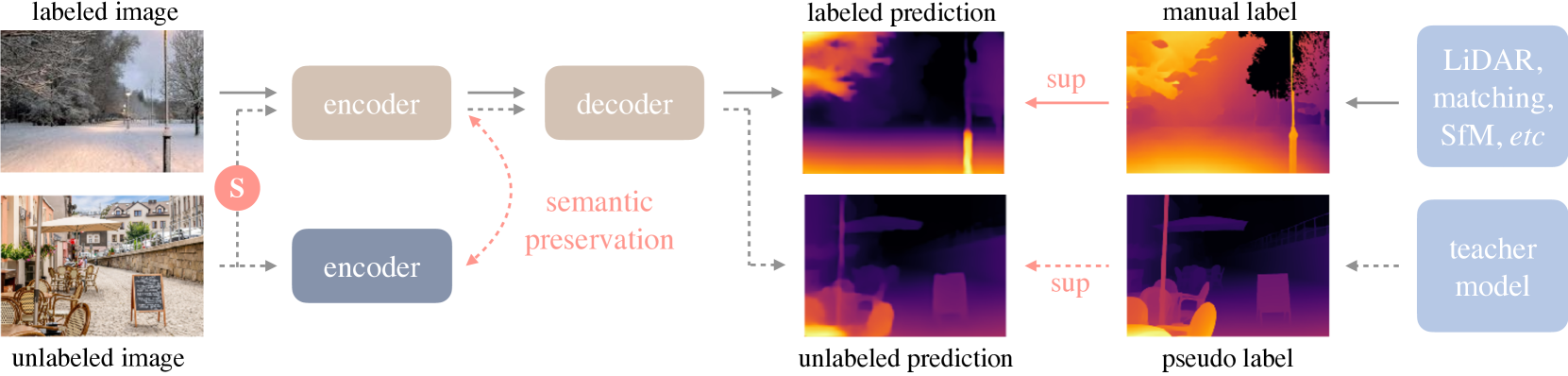
This work presents Depth Anything, a highly practical solution for robust monocular depth estimation. Without pursuing novel technical modules, we aim to build a simple yet powerful foundation model dealing with any images under any circumstances. To this end, we scale up the dataset by designing a data engine to collect and automatically annotate large-scale unlabeled data (~62M), which significantly enlarges the data coverage and thus is able to reduce the generalization error. We investigate two simple yet effective strategies that make data scaling-up promising. First, a more challenging optimization target is created by leveraging data augmentation tools. It compels the model to actively seek extra visual knowledge and acquire robust representations. Second, an auxiliary supervision is developed to enforce the model to inherit rich semantic priors from pre-trained encoders. We evaluate its zero-shot capabilities extensively, including six public datasets and randomly captured photos. It demonstrates impressive generalization ability. Further, through fine-tuning it with metric depth information from NYUv2 and KITTI, new SOTAs are set. Our better depth model also results in a better depth-conditioned ControlNet. Our models are released at https://github.com/LiheYoung/Depth-Anything.
4/9/2024

Depth Anywhere: Enhancing 360 Monocular Depth Estimation via Perspective Distillation and Unlabeled Data Augmentation
Ning-Hsu Wang, Yu-Lun Liu
0
0
Accurately estimating depth in 360-degree imagery is crucial for virtual reality, autonomous navigation, and immersive media applications. Existing depth estimation methods designed for perspective-view imagery fail when applied to 360-degree images due to different camera projections and distortions, whereas 360-degree methods perform inferior due to the lack of labeled data pairs. We propose a new depth estimation framework that utilizes unlabeled 360-degree data effectively. Our approach uses state-of-the-art perspective depth estimation models as teacher models to generate pseudo labels through a six-face cube projection technique, enabling efficient labeling of depth in 360-degree images. This method leverages the increasing availability of large datasets. Our approach includes two main stages: offline mask generation for invalid regions and an online semi-supervised joint training regime. We tested our approach on benchmark datasets such as Matterport3D and Stanford2D3D, showing significant improvements in depth estimation accuracy, particularly in zero-shot scenarios. Our proposed training pipeline can enhance any 360 monocular depth estimator and demonstrates effective knowledge transfer across different camera projections and data types. See our project page for results: https://albert100121.github.io/Depth-Anywhere/
6/19/2024
🖼️
Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Metzger, Rodrigo Caye Daudt, Konrad Schindler
0
0
Monocular depth estimation is a fundamental computer vision task. Recovering 3D depth from a single image is geometrically ill-posed and requires scene understanding, so it is not surprising that the rise of deep learning has led to a breakthrough. The impressive progress of monocular depth estimators has mirrored the growth in model capacity, from relatively modest CNNs to large Transformer architectures. Still, monocular depth estimators tend to struggle when presented with images with unfamiliar content and layout, since their knowledge of the visual world is restricted by the data seen during training, and challenged by zero-shot generalization to new domains. This motivates us to explore whether the extensive priors captured in recent generative diffusion models can enable better, more generalizable depth estimation. We introduce Marigold, a method for affine-invariant monocular depth estimation that is derived from Stable Diffusion and retains its rich prior knowledge. The estimator can be fine-tuned in a couple of days on a single GPU using only synthetic training data. It delivers state-of-the-art performance across a wide range of datasets, including over 20% performance gains in specific cases. Project page: https://marigoldmonodepth.github.io.
4/4/2024
Domain-Transferred Synthetic Data Generation for Improving Monocular Depth Estimation
Seungyeop Lee, Knut Peterson, Solmaz Arezoomandan, Bill Cai, Peihan Li, Lifeng Zhou, David Han
0
0
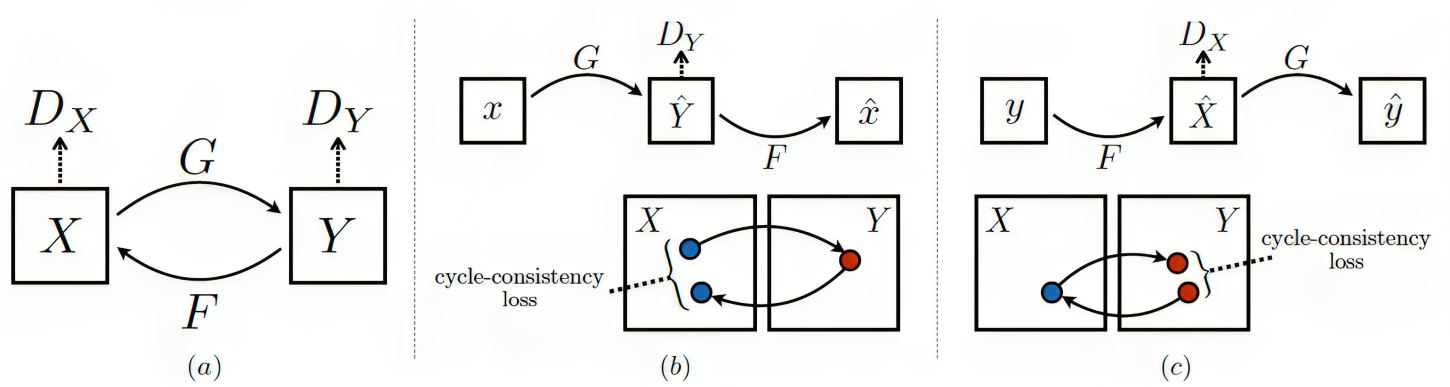
A major obstacle to the development of effective monocular depth estimation algorithms is the difficulty in obtaining high-quality depth data that corresponds to collected RGB images. Collecting this data is time-consuming and costly, and even data collected by modern sensors has limited range or resolution, and is subject to inconsistencies and noise. To combat this, we propose a method of data generation in simulation using 3D synthetic environments and CycleGAN domain transfer. We compare this method of data generation to the popular NYUDepth V2 dataset by training a depth estimation model based on the DenseDepth structure using different training sets of real and simulated data. We evaluate the performance of the models on newly collected images and LiDAR depth data from a Husky robot to verify the generalizability of the approach and show that GAN-transformed data can serve as an effective alternative to real-world data, particularly in depth estimation.
5/3/2024