DepthMOT: Depth Cues Lead to a Strong Multi-Object Tracker
2404.05518
0
0
Abstract
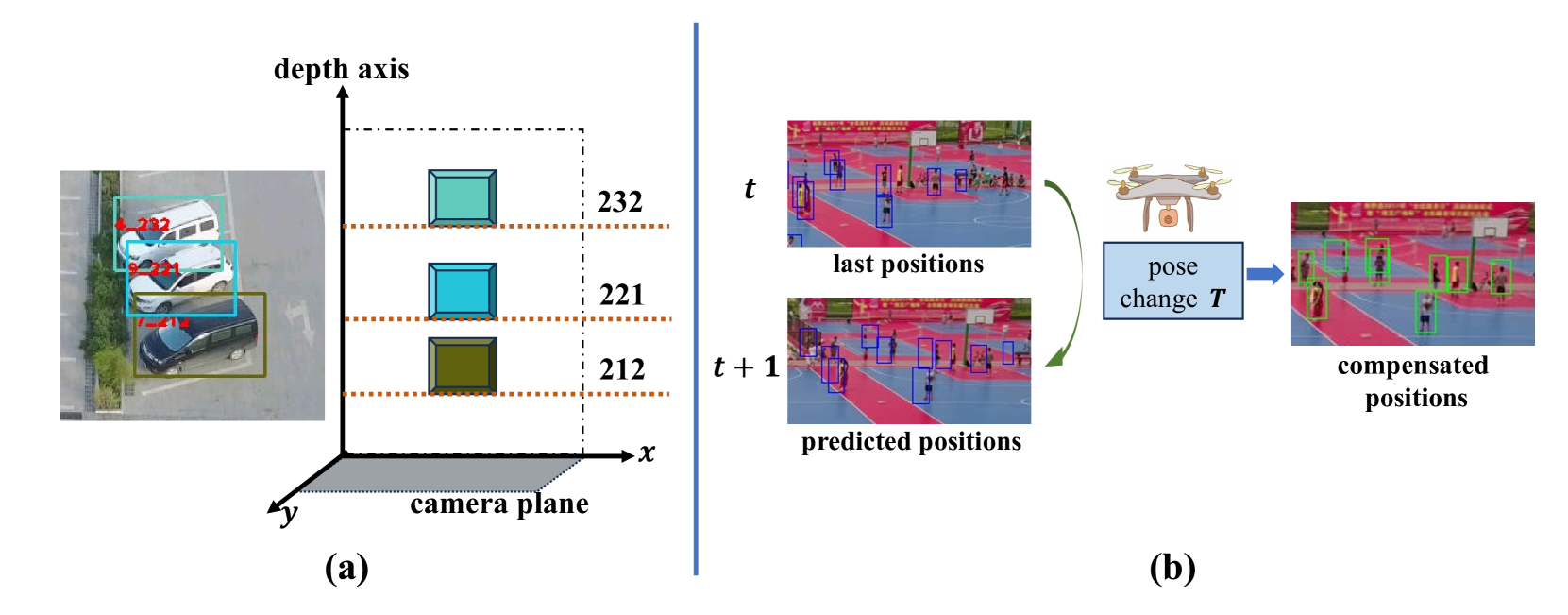
Accurately distinguishing each object is a fundamental goal of Multi-object tracking (MOT) algorithms. However, achieving this goal still remains challenging, primarily due to: (i) For crowded scenes with occluded objects, the high overlap of object bounding boxes leads to confusion among closely located objects. Nevertheless, humans naturally perceive the depth of elements in a scene when observing 2D videos. Inspired by this, even though the bounding boxes of objects are close on the camera plane, we can differentiate them in the depth dimension, thereby establishing a 3D perception of the objects. (ii) For videos with rapidly irregular camera motion, abrupt changes in object positions can result in ID switches. However, if the camera pose are known, we can compensate for the errors in linear motion models. In this paper, we propose textit{DepthMOT}, which achieves: (i) detecting and estimating scene depth map textit{end-to-end}, (ii) compensating the irregular camera motion by camera pose estimation. Extensive experiments demonstrate the superior performance of DepthMOT in VisDrone-MOT and UAVDT datasets. The code will be available at url{https://github.com/JackWoo0831/DepthMOT}.
Create account to get full access
Overview
- This paper introduces DepthMOT, a multi-object tracking system that leverages depth cues to improve tracking performance.
- The key idea is to incorporate depth information, in addition to traditional 2D visual features, to better distinguish and track multiple objects.
- The authors demonstrate that DepthMOT outperforms state-of-the-art 2D-based multi-object trackers on several benchmarks.
Plain English Explanation
Tracking Multiple Objects in 3D Space Imagine you're trying to keep track of multiple people moving around a room. It can be challenging to follow each person, especially if they're occluded by others or move quickly. DepthMOT: Depth Cues Lead to a Strong Multi-Object Tracker is a system that aims to make this task easier by using depth information.
Depth, or the distance of an object from the camera, can provide valuable cues to help distinguish and track different people or objects. For example, if two people are close together in the 2D image, but one is in the foreground and the other in the background, depth information can help the system tell them apart.
By incorporating depth data, in addition to traditional visual features, DepthMOT is able to more accurately identify and follow multiple objects as they move around. The authors show that their system outperforms other state-of-the-art multi-object trackers that rely only on 2D information.
Potential Applications This technology could be useful in a variety of applications where keeping track of multiple moving objects is important, such as surveillance, autonomous vehicles, or sports analytics. By better leveraging depth data, DepthMOT could help improve the performance of these systems.
Technical Explanation
The key innovation of DepthMOT is the incorporation of depth information into a multi-object tracking framework. Traditionally, multi-object trackers have relied solely on 2D visual features, such as object appearance and motion, to associate detections across frames and maintain individual object identities.
In contrast, DepthMOT leverages depth data, either from a dedicated depth sensor or estimated from a monocular camera, to better distinguish and track multiple objects. The authors propose several depth-aware modules, including a depth-based data association component and a depth-aware object representation, that are integrated into a multi-object tracking pipeline.
The authors evaluate DepthMOT on several popular multi-object tracking benchmarks and demonstrate significant performance improvements over state-of-the-art 2D-based trackers. They attribute these gains to the system's ability to better handle occlusions and resolve ambiguities in object associations by utilizing depth information.
Critical Analysis
The DepthMOT approach represents an important step forward in multi-object tracking by leveraging depth cues. However, the authors acknowledge several limitations and areas for future work:
- The system's performance is still dependent on the quality and accuracy of the depth data, which can be challenging to obtain, especially in monocular setups.
- The depth-aware modules added additional computational complexity, which could impact the system's real-time capabilities, particularly on resource-constrained platforms.
- The paper focuses on static camera setups, and it's unclear how well DepthMOT would generalize to more dynamic, ego-centric camera scenarios.
Furthermore, the authors do not provide a thorough analysis of potential biases or failure cases of their depth-based approach. It would be valuable to understand the types of scenarios where depth information may not be sufficient or could even lead to degraded performance compared to 2D-only methods.
Conclusion
DepthMOT represents an exciting advance in multi-object tracking by leveraging depth cues to improve object detection and association. The authors demonstrate that incorporating depth information can lead to significant performance gains over traditional 2D-based trackers.
While the current system has some limitations, the underlying idea of combining 2D visual features with depth data is a promising direction for further research and development. As depth sensing technologies continue to improve, we can expect to see more sophisticated multi-object tracking systems that can robustly handle a wide range of real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Track Initialization and Re-Identification for~3D Multi-View Multi-Object Tracking
Linh Van Ma, Tran Thien Dat Nguyen, Ba-Ngu Vo, Hyunsung Jang, Moongu Jeon
0
0
We propose a 3D multi-object tracking (MOT) solution using only 2D detections from monocular cameras, which automatically initiates/terminates tracks as well as resolves track appearance-reappearance and occlusions. Moreover, this approach does not require detector retraining when cameras are reconfigured but only the camera matrices of reconfigured cameras need to be updated. Our approach is based on a Bayesian multi-object formulation that integrates track initiation/termination, re-identification, occlusion handling, and data association into a single Bayes filtering recursion. However, the exact filter that utilizes all these functionalities is numerically intractable due to the exponentially growing number of terms in the (multi-object) filtering density, while existing approximations trade-off some of these functionalities for speed. To this end, we develop a more efficient approximation suitable for online MOT by incorporating object features and kinematics into the measurement model, which improves data association and subsequently reduces the number of terms. Specifically, we exploit the 2D detections and extracted features from multiple cameras to provide a better approximation of the multi-object filtering density to realize the track initiation/termination and re-identification functionalities. Further, incorporating a tractable geometric occlusion model based on 2D projections of 3D objects on the camera planes realizes the occlusion handling functionality of the filter. Evaluation of the proposed solution on challenging datasets demonstrates significant improvements and robustness when camera configurations change on-the-fly, compared to existing multi-view MOT solutions. The source code is publicly available at https://github.com/linh-gist/mv-glmb-ab.
5/30/2024
🔄
Enhanced Object Tracking by Self-Supervised Auxiliary Depth Estimation Learning
Zhenyu Wei, Yujie He, Zhanchuan Cai
0
0
RGB-D tracking significantly improves the accuracy of object tracking. However, its dependency on real depth inputs and the complexity involved in multi-modal fusion limit its applicability across various scenarios. The utilization of depth information in RGB-D tracking inspired us to propose a new method, named MDETrack, which trains a tracking network with an additional capability to understand the depth of scenes, through supervised or self-supervised auxiliary Monocular Depth Estimation learning. The outputs of MDETrack's unified feature extractor are fed to the side-by-side tracking head and auxiliary depth estimation head, respectively. The auxiliary module will be discarded in inference, thus keeping the same inference speed. We evaluated our models with various training strategies on multiple datasets, and the results show an improved tracking accuracy even without real depth. Through these findings we highlight the potential of depth estimation in enhancing object tracking performance.
5/24/2024
🔎
UncertaintyTrack: Exploiting Detection and Localization Uncertainty in Multi-Object Tracking
Chang Won Lee, Steven L. Waslander
0
0
Multi-object tracking (MOT) methods have seen a significant boost in performance recently, due to strong interest from the research community and steadily improving object detection methods. The majority of tracking methods follow the tracking-by-detection (TBD) paradigm, blindly trust the incoming detections with no sense of their associated localization uncertainty. This lack of uncertainty awareness poses a problem in safety-critical tasks such as autonomous driving where passengers could be put at risk due to erroneous detections that have propagated to downstream tasks, including MOT. While there are existing works in probabilistic object detection that predict the localization uncertainty around the boxes, no work in 2D MOT for autonomous driving has studied whether these estimates are meaningful enough to be leveraged effectively in object tracking. We introduce UncertaintyTrack, a collection of extensions that can be applied to multiple TBD trackers to account for localization uncertainty estimates from probabilistic object detectors. Experiments on the Berkeley Deep Drive MOT dataset show that the combination of our method and informative uncertainty estimates reduces the number of ID switches by around 19% and improves mMOTA by 2-3%. The source code is available at https://github.com/TRAILab/UncertaintyTrack
5/1/2024

MOSE: Boosting Vision-based Roadside 3D Object Detection with Scene Cues
Xiahan Chen, Mingjian Chen, Sanli Tang, Yi Niu, Jiang Zhu
0
0
3D object detection based on roadside cameras is an additional way for autonomous driving to alleviate the challenges of occlusion and short perception range from vehicle cameras. Previous methods for roadside 3D object detection mainly focus on modeling the depth or height of objects, neglecting the stationary of cameras and the characteristic of inter-frame consistency. In this work, we propose a novel framework, namely MOSE, for MOnocular 3D object detection with Scene cuEs. The scene cues are the frame-invariant scene-specific features, which are crucial for object localization and can be intuitively regarded as the height between the surface of the real road and the virtual ground plane. In the proposed framework, a scene cue bank is designed to aggregate scene cues from multiple frames of the same scene with a carefully designed extrinsic augmentation strategy. Then, a transformer-based decoder lifts the aggregated scene cues as well as the 3D position embeddings for 3D object location, which boosts generalization ability in heterologous scenes. The extensive experiment results on two public benchmarks demonstrate the state-of-the-art performance of the proposed method, which surpasses the existing methods by a large margin.
4/9/2024