Roadside Monocular 3D Detection via 2D Detection Prompting
2404.01064
0
0
Abstract
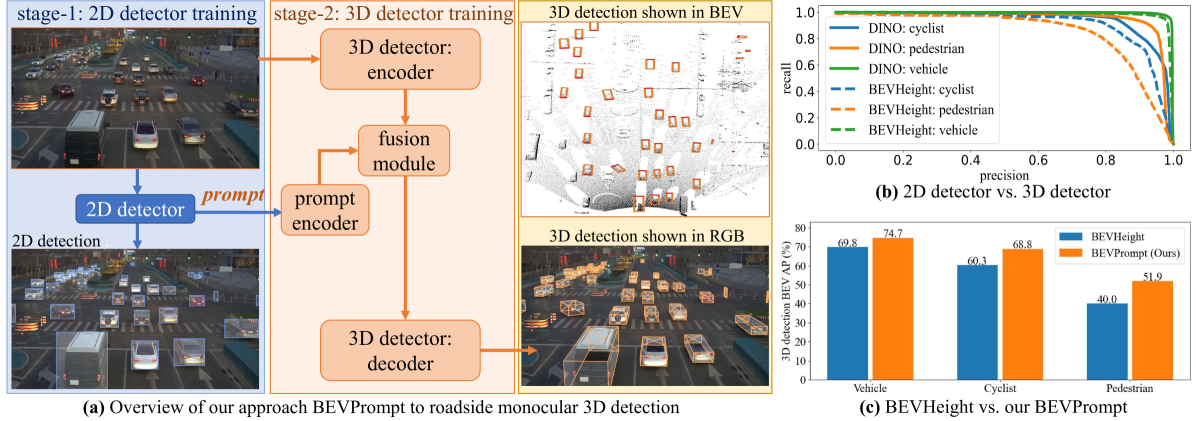
The problem of roadside monocular 3D detection requires detecting objects of interested classes in a 2D RGB frame and predicting their 3D information such as locations in bird's-eye-view (BEV). It has broad applications in traffic control, vehicle-vehicle communication, and vehicle-infrastructure cooperative perception. To approach this problem, we present a novel and simple method by prompting the 3D detector using 2D detections. Our method builds on a key insight that, compared with 3D detectors, a 2D detector is much easier to train and performs significantly better w.r.t detections on the 2D image plane. That said, one can exploit 2D detections of a well-trained 2D detector as prompts to a 3D detector, being trained in a way of inflating such 2D detections to 3D towards 3D detection. To construct better prompts using the 2D detector, we explore three techniques: (a) concatenating both 2D and 3D detectors' features, (b) attentively fusing 2D and 3D detectors' features, and (c) encoding predicted 2D boxes x, y, width, height, label and attentively fusing such with the 3D detector's features. Surprisingly, the third performs the best. Moreover, we present a yaw tuning tactic and a class-grouping strategy that merges classes based on their functionality; these techniques improve 3D detection performance further. Comprehensive ablation studies and extensive experiments demonstrate that our method resoundingly outperforms prior works, achieving the state-of-the-art on two large-scale roadside 3D detection benchmarks.
Create account to get full access
Overview
- This paper proposes a novel method for 3D object detection from monocular images, called "Roadside Monocular 3D Detection via 2D Detection Prompting".
- The key idea is to leverage 2D object detection as a prompt to improve the performance of 3D object detection from a single camera.
- The method aims to enable 3D perception in real-world scenarios, such as autonomous driving, where only a monocular camera is available.
Plain English Explanation
The paper presents a new way to detect 3D objects, like cars and pedestrians, using just a single camera. This is an important problem for technologies like self-driving cars, where we need to understand the 3D world around the vehicle using limited sensors.
The researchers' approach is to first use a 2D object detector to identify things in the camera image. They then take this 2D detection information and use it to help a 3D object detector do its job better. The 2D detections act as a "prompt" to guide the 3D detector towards the right objects and their locations in the 3D space.
This is a clever way to leverage existing 2D detection models to improve 3D perception from a single camera. By combining the 2D and 3D information, the method can achieve higher accuracy compared to using 3D detection alone. This could be very useful for real-world applications where only a single camera is available, like in many self-driving car setups.
Technical Explanation
The paper proposes a "Roadside Monocular 3D Detection" approach that utilizes 2D object detection as a "prompt" to enhance the performance of 3D object detection from a single camera.
The core idea is to first run a 2D object detector on the camera image to identify the locations of objects. These 2D detections are then used to guide and constrain the 3D object detection process, helping the 3D detector focus on the right regions and better estimate the 3D properties of the detected objects.
The method consists of several key components:
- A 2D object detection module to generate initial 2D bounding boxes and confidence scores.
- A 3D object detection module that takes the 2D detections as input and outputs 3D bounding boxes.
- A fusion module that combines the 2D and 3D detection results to produce the final 3D object predictions.
The authors demonstrate the effectiveness of their approach on several benchmark datasets for monocular 3D object detection. They show that by leveraging the 2D detection information, their method can outperform state-of-the-art 3D detectors that do not use this additional cue.
Critical Analysis
The paper presents a well-designed and carefully evaluated approach to the challenging problem of monocular 3D object detection. The authors have thoughtfully incorporated 2D detection as a prompting mechanism to boost the 3D detection performance, which is a clever and promising idea.
One potential limitation is that the method's performance may still be constrained by the accuracy of the underlying 2D object detector. If the 2D detections contain errors or miss objects, this could negatively impact the final 3D predictions. The authors acknowledge this and suggest exploring more robust 2D detection methods as future work.
Additionally, the paper focuses on evaluating the approach on standard computer vision benchmarks, but it would be valuable to see how it performs in more realistic, complex driving scenes. Real-world deployment would likely introduce additional challenges, such as handling occlusions, varying lighting conditions, and diverse object categories.
Overall, the paper makes a compelling contribution to the field of 3D perception from monocular images. The proposed 2D-to-3D prompting technique is a meaningful step forward and could have significant implications for applications like autonomous driving, where affordable and reliable 3D sensing is a crucial requirement.
Conclusion
This paper presents a novel approach for 3D object detection using a single camera, called "Roadside Monocular 3D Detection via 2D Detection Prompting". The key innovation is to leverage 2D object detection as a prompt to guide and enhance the performance of 3D object detection.
By combining the 2D and 3D detection information, the method can achieve higher accuracy compared to using 3D detection alone. This is an important advancement, as monocular 3D perception is a challenging problem with numerous real-world applications, such as autonomous driving, where affordable and reliable 3D sensing is a critical requirement.
While the paper demonstrates promising results on standard benchmarks, further research is needed to address potential limitations, such as the method's reliance on the accuracy of the underlying 2D detector. Exploring the approach's performance in more complex, realistic driving scenarios would also be a valuable next step. Overall, this work represents a meaningful contribution to the field of 3D perception from monocular images.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MOSE: Boosting Vision-based Roadside 3D Object Detection with Scene Cues
Xiahan Chen, Mingjian Chen, Sanli Tang, Yi Niu, Jiang Zhu
0
0
3D object detection based on roadside cameras is an additional way for autonomous driving to alleviate the challenges of occlusion and short perception range from vehicle cameras. Previous methods for roadside 3D object detection mainly focus on modeling the depth or height of objects, neglecting the stationary of cameras and the characteristic of inter-frame consistency. In this work, we propose a novel framework, namely MOSE, for MOnocular 3D object detection with Scene cuEs. The scene cues are the frame-invariant scene-specific features, which are crucial for object localization and can be intuitively regarded as the height between the surface of the real road and the virtual ground plane. In the proposed framework, a scene cue bank is designed to aggregate scene cues from multiple frames of the same scene with a carefully designed extrinsic augmentation strategy. Then, a transformer-based decoder lifts the aggregated scene cues as well as the 3D position embeddings for 3D object location, which boosts generalization ability in heterologous scenes. The extensive experiment results on two public benchmarks demonstrate the state-of-the-art performance of the proposed method, which surpasses the existing methods by a large margin.
4/9/2024

SGV3D:Towards Scenario Generalization for Vision-based Roadside 3D Object Detection
Lei Yang, Xinyu Zhang, Jun Li, Li Wang, Chuang Zhang, Li Ju, Zhiwei Li, Yang Shen
0
0
Roadside perception can greatly increase the safety of autonomous vehicles by extending their perception ability beyond the visual range and addressing blind spots. However, current state-of-the-art vision-based roadside detection methods possess high accuracy on labeled scenes but have inferior performance on new scenes. This is because roadside cameras remain stationary after installation and can only collect data from a single scene, resulting in the algorithm overfitting these roadside backgrounds and camera poses. To address this issue, in this paper, we propose an innovative Scenario Generalization Framework for Vision-based Roadside 3D Object Detection, dubbed SGV3D. Specifically, we employ a Background-suppressed Module (BSM) to mitigate background overfitting in vision-centric pipelines by attenuating background features during the 2D to bird's-eye-view projection. Furthermore, by introducing the Semi-supervised Data Generation Pipeline (SSDG) using unlabeled images from new scenes, diverse instance foregrounds with varying camera poses are generated, addressing the risk of overfitting specific camera poses. We evaluate our method on two large-scale roadside benchmarks. Our method surpasses all previous methods by a significant margin in new scenes, including +42.57% for vehicle, +5.87% for pedestrian, and +14.89% for cyclist compared to BEVHeight on the DAIR-V2X-I heterologous benchmark. On the larger-scale Rope3D heterologous benchmark, we achieve notable gains of 14.48% for car and 12.41% for large vehicle. We aspire to contribute insights on the exploration of roadside perception techniques, emphasizing their capability for scenario generalization. The code will be available at https://github.com/yanglei18/SGV3D
4/10/2024

Monocular 3D lane detection for Autonomous Driving: Recent Achievements, Challenges, and Outlooks
Fulong Ma, Weiqing Qi, Guoyang Zhao, Linwei Zheng, Sheng Wang, Yuxuan Liu, Ming Liu
0
0
3D lane detection is essential in autonomous driving as it extracts structural and traffic information from the road in three-dimensional space, aiding self-driving cars in logical, safe, and comfortable path planning and motion control. Given the cost of sensors and the advantages of visual data in color information, 3D lane detection based on monocular vision is an important research direction in the realm of autonomous driving, increasingly gaining attention in both industry and academia. Regrettably, recent advancements in visual perception seem inadequate for the development of fully reliable 3D lane detection algorithms, which also hampers the progress of vision-based fully autonomous vehicles. We believe that there is still considerable room for improvement in 3D lane detection algorithms for autonomous vehicles using visual sensors, and significant enhancements are needed. This review looks back and analyzes the current state of achievements in the field of 3D lane detection research. It covers all current monocular-based 3D lane detection processes, discusses the performance of these cutting-edge algorithms, analyzes the time complexity of various algorithms, and highlights the main achievements and limitations of ongoing research efforts. The survey also includes a comprehensive discussion of available 3D lane detection datasets and the challenges that researchers face but have not yet resolved. Finally, our work outlines future research directions and invites researchers and practitioners to join this exciting field.
4/22/2024

Long-Tailed 3D Detection via 2D Late Fusion
Yechi Ma, Neehar Peri, Shuoquan Wei, Wei Hua, Deva Ramanan, Yanan Li, Shu Kong
0
0
Long-Tailed 3D Object Detection (LT3D) addresses the problem of accurately detecting objects from both common and rare classes. Contemporary multi-modal detectors achieve low AP on rare-classes (e.g., CMT only achieves 9.4 AP on stroller), presumably because training detectors end-to-end with significant class imbalance is challenging. To address this limitation, we delve into a simple late-fusion framework that ensembles independently trained uni-modal LiDAR and RGB detectors. Importantly, such a late-fusion framework allows us to leverage large-scale uni-modal datasets (with more examples for rare classes) to train better uni-modal RGB detectors, unlike prevailing multimodal detectors that require paired multi-modal training data. Notably, our approach significantly improves rare-class detection by 7.2% over prior work. Further, we examine three critical components of our simple late-fusion approach from first principles and investigate whether to train 2D or 3D RGB detectors, whether to match RGB and LiDAR detections in 3D or the projected 2D image plane for fusion, and how to fuse matched detections. Extensive experiments reveal that 2D RGB detectors achieve better recognition accuracy for rare classes than 3D RGB detectors and matching on the 2D image plane mitigates depth estimation errors. Our late-fusion approach achieves 51.4 mAP on the established nuScenes LT3D benchmark, improving over prior work by 5.9 mAP!
6/17/2024