DER-GCN: Dialogue and Event Relation-Aware Graph Convolutional Neural Network for Multimodal Dialogue Emotion Recognition

0
Sign in to get full access
Overview
- The paper proposes a new graph convolutional neural network (DER-GCN) for multimodal dialogue emotion recognition.
- DER-GCN leverages dialogue and event relations to build a graph that captures the complex interactions in a dialogue.
- The model uses multiple information transformers and masked graph autoencoders to effectively learn representations from the dialogue graph.
- Experiments show DER-GCN outperforms state-of-the-art methods on benchmark datasets for multimodal dialogue emotion recognition.
Plain English Explanation
Multimodal dialogue emotion recognition is the task of identifying the emotional state of a person based on their spoken words, tone of voice, facial expressions, and other signals during a conversation. This is an important capability for human-AI interaction and dialogue systems.
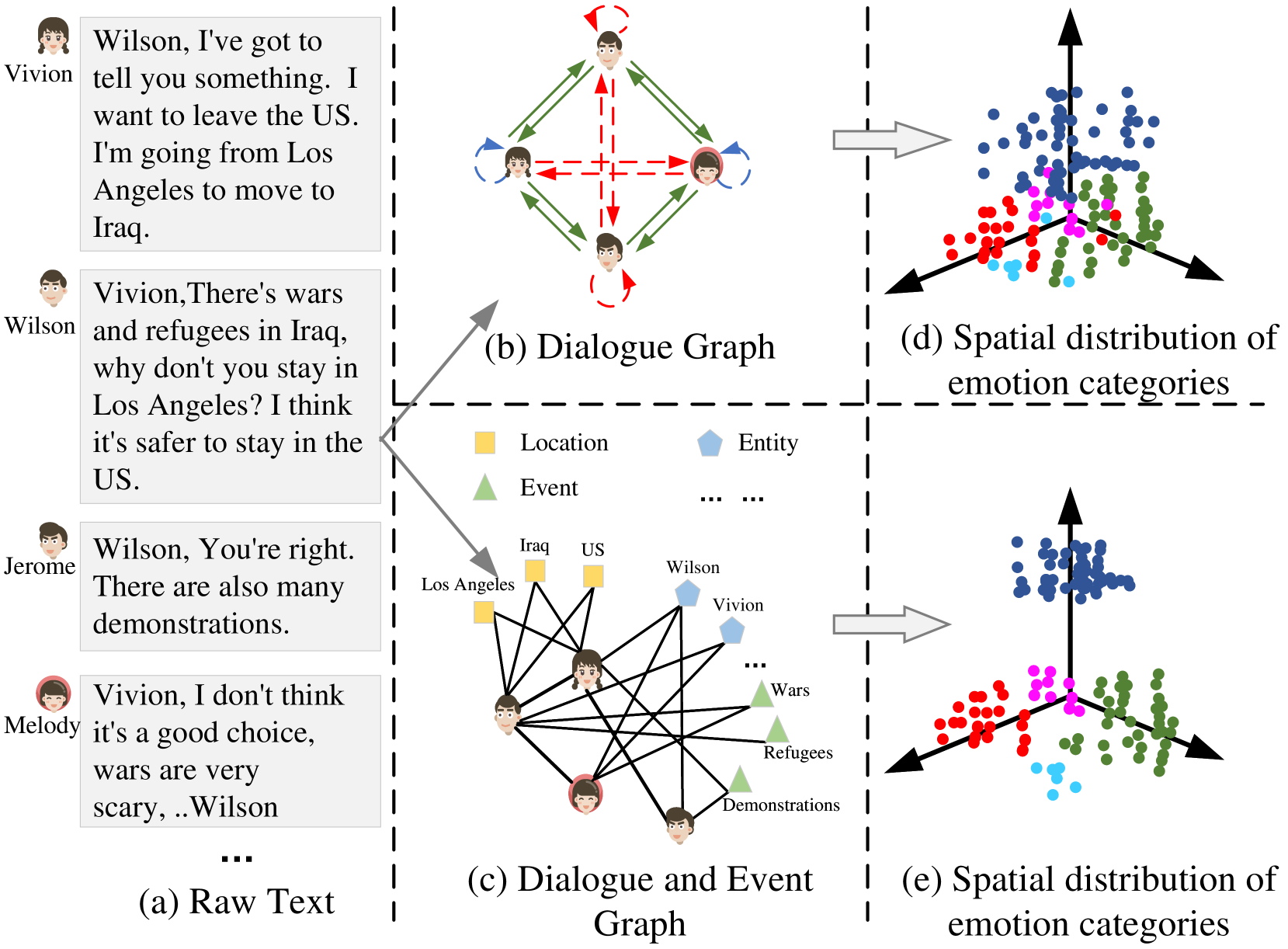
The key innovation in this paper is the DER-GCN model, which uses a graph neural network to better capture the complex relationships in a dialogue. Typical approaches treat each dialogue turn in isolation, but DER-GCN builds a graph that represents how the different conversational cues (words, gestures, events, etc.) are connected and influence each other.
The model uses multiple information transformers to extract meaningful representations from the different modalities (text, audio, video). It also employs masked graph autoencoders to learn robust features from the dialogue graph structure. This allows the model to uncover intricate connections between the various cues that contribute to the overall emotional state.
The experiments show that this dialogue and event relation-aware approach outperforms other state-of-the-art methods for multimodal dialogue emotion recognition. This suggests the importance of modeling the complex interactions within a dialogue to accurately infer the emotional state of the participants.
Technical Explanation
The key technical contributions of the DER-GCN model are:
-
Dialogue and Event Relation Graph: The authors construct a graph representation of the dialogue that captures the relationships between different conversational elements, such as utterances, speakers, emotions, and relevant events. This allows the model to reason about how these different factors influence each other.
-
Multiple Information Transformers: The model uses separate Transformer networks to extract features from the text, audio, and video modalities. This allows it to effectively process the multimodal inputs.
-
Masked Graph Autoencoder: DER-GCN employs a masked graph autoencoder to learn robust representations of the dialogue graph structure. This helps the model uncover latent connections between the different elements of the conversation.
-
Contrastive Learning: The authors utilize a contrastive learning objective to further improve the learned representations by encouraging the model to distinguish between positive and negative samples in the dialogue graph.
The experimental results show that DER-GCN outperforms state-of-the-art methods for multimodal dialogue emotion recognition on benchmark datasets like IEMOCAP and EmotionLines. This demonstrates the benefits of the dialogue and event relation-aware graph representation and the effectiveness of the proposed neural architecture.
Critical Analysis
One limitation of the DER-GCN model is that it relies on the availability of detailed annotations for the dialogue events and relations, which may not always be feasible in real-world scenarios. The authors acknowledge this and suggest exploring weakly supervised or unsupervised methods for constructing the dialogue graph as a potential area for future research.
Additionally, the paper does not provide a thorough analysis of the model's interpretability or its ability to explain the reasoning behind its emotion predictions. Investigating the model's interpretability and explainability could be a valuable direction for further research, as it would help users understand and trust the model's decisions.
Another potential concern is the model's scalability to larger and more complex dialogue datasets. The authors evaluate DER-GCN on relatively small datasets, and it would be interesting to see how the model performs on larger-scale dialogue corpora with more diverse emotional expressions and conversational dynamics.
Conclusion
The DER-GCN model proposed in this paper represents a significant advancement in the field of multimodal dialogue emotion recognition. By leveraging the dialogue and event relations to build a graph representation of the conversation, the model is able to capture the complex interactions between the various conversational cues and achieve state-of-the-art performance on benchmark datasets.
The work highlights the importance of modeling the inherent structure and dynamics of a dialogue, rather than treating each utterance in isolation. This insight has broader implications for the design of intelligent dialogue systems and human-AI interaction, where understanding the contextual and relational aspects of communication is crucial for achieving natural and effective interactions.
While the paper presents a promising approach, further research is needed to address the limitations and explore ways to make the model more scalable, interpretable, and practical for real-world applications. Overall, this work represents an important step towards more advanced and robust multimodal dialogue understanding capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DER-GCN: Dialogue and Event Relation-Aware Graph Convolutional Neural Network for Multimodal Dialogue Emotion Recognition
Wei Ai, Yuntao Shou, Tao Meng, Nan Yin, Keqin Li
With the continuous development of deep learning (DL), the task of multimodal dialogue emotion recognition (MDER) has recently received extensive research attention, which is also an essential branch of DL. The MDER aims to identify the emotional information contained in different modalities, e.g., text, video, and audio, in different dialogue scenes. However, existing research has focused on modeling contextual semantic information and dialogue relations between speakers while ignoring the impact of event relations on emotion. To tackle the above issues, we propose a novel Dialogue and Event Relation-Aware Graph Convolutional Neural Network for Multimodal Emotion Recognition (DER-GCN) method. It models dialogue relations between speakers and captures latent event relations information. Specifically, we construct a weighted multi-relationship graph to simultaneously capture the dependencies between speakers and event relations in a dialogue. Moreover, we also introduce a Self-Supervised Masked Graph Autoencoder (SMGAE) to improve the fusion representation ability of features and structures. Next, we design a new Multiple Information Transformer (MIT) to capture the correlation between different relations, which can provide a better fuse of the multivariate information between relations. Finally, we propose a loss optimization strategy based on contrastive learning to enhance the representation learning ability of minority class features. We conduct extensive experiments on the IEMOCAP and MELD benchmark datasets, which verify the effectiveness of the DER-GCN model. The results demonstrate that our model significantly improves both the average accuracy and the f1 value of emotion recognition.
Read more9/4/2024

0
Efficient Long-distance Latent Relation-aware Graph Neural Network for Multi-modal Emotion Recognition in Conversations
Yuntao Shou, Wei Ai, Jiayi Du, Tao Meng, Haiyan Liu, Nan Yin
The task of multi-modal emotion recognition in conversation (MERC) aims to analyze the genuine emotional state of each utterance based on the multi-modal information in the conversation, which is crucial for conversation understanding. Existing methods focus on using graph neural networks (GNN) to model conversational relationships and capture contextual latent semantic relationships. However, due to the complexity of GNN, existing methods cannot efficiently capture the potential dependencies between long-distance utterances, which limits the performance of MERC. In this paper, we propose an Efficient Long-distance Latent Relation-aware Graph Neural Network (ELR-GNN) for multi-modal emotion recognition in conversations. Specifically, we first use pre-extracted text, video and audio features as input to Bi-LSTM to capture contextual semantic information and obtain low-level utterance features. Then, we use low-level utterance features to construct a conversational emotion interaction graph. To efficiently capture the potential dependencies between long-distance utterances, we use the dilated generalized forward push algorithm to precompute the emotional propagation between global utterances and design an emotional relation-aware operator to capture the potential semantic associations between different utterances. Furthermore, we combine early fusion and adaptive late fusion mechanisms to fuse latent dependency information between speaker relationship information and context. Finally, we obtain high-level discourse features and feed them into MLP for emotion prediction. Extensive experimental results show that ELR-GNN achieves state-of-the-art performance on the benchmark datasets IEMOCAP and MELD, with running times reduced by 52% and 35%, respectively.
Read more9/4/2024

0
Multimodal Fusion via Hypergraph Autoencoder and Contrastive Learning for Emotion Recognition in Conversation
Zijian Yi, Ziming Zhao, Zhishu Shen, Tiehua Zhang
Multimodal emotion recognition in conversation (MERC) seeks to identify the speakers' emotions expressed in each utterance, offering significant potential across diverse fields. The challenge of MERC lies in balancing speaker modeling and context modeling, encompassing both long-distance and short-distance contexts, as well as addressing the complexity of multimodal information fusion. Recent research adopts graph-based methods to model intricate conversational relationships effectively. Nevertheless, the majority of these methods utilize a fixed fully connected structure to link all utterances, relying on convolution to interpret complex context. This approach can inherently heighten the redundancy in contextual messages and excessive graph network smoothing, particularly in the context of long-distance conversations. To address this issue, we propose a framework that dynamically adjusts hypergraph connections by variational hypergraph autoencoder (VHGAE), and employs contrastive learning to mitigate uncertainty factors during the reconstruction process. Experimental results demonstrate the effectiveness of our proposal against the state-of-the-art methods on IEMOCAP and MELD datasets. We release the code to support the reproducibility of this work at https://github.com/yzjred/-HAUCL.
Read more8/6/2024

0
Masked Graph Learning with Recurrent Alignment for Multimodal Emotion Recognition in Conversation
Tao Meng, Fuchen Zhang, Yuntao Shou, Hongen Shao, Wei Ai, Keqin Li
Since Multimodal Emotion Recognition in Conversation (MERC) can be applied to public opinion monitoring, intelligent dialogue robots, and other fields, it has received extensive research attention in recent years. Unlike traditional unimodal emotion recognition, MERC can fuse complementary semantic information between multiple modalities (e.g., text, audio, and vision) to improve emotion recognition. However, previous work ignored the inter-modal alignment process and the intra-modal noise information before multimodal fusion but directly fuses multimodal features, which will hinder the model for representation learning. In this study, we have developed a novel approach called Masked Graph Learning with Recursive Alignment (MGLRA) to tackle this problem, which uses a recurrent iterative module with memory to align multimodal features, and then uses the masked GCN for multimodal feature fusion. First, we employ LSTM to capture contextual information and use a graph attention-filtering mechanism to eliminate noise effectively within the modality. Second, we build a recurrent iteration module with a memory function, which can use communication between different modalities to eliminate the gap between modalities and achieve the preliminary alignment of features between modalities. Then, a cross-modal multi-head attention mechanism is introduced to achieve feature alignment between modalities and construct a masked GCN for multimodal feature fusion, which can perform random mask reconstruction on the nodes in the graph to obtain better node feature representation. Finally, we utilize a multilayer perceptron (MLP) for emotion recognition. Extensive experiments on two benchmark datasets (i.e., IEMOCAP and MELD) demonstrate that {MGLRA} outperforms state-of-the-art methods.
Read more7/25/2024