Multimodal Fusion via Hypergraph Autoencoder and Contrastive Learning for Emotion Recognition in Conversation

0

Sign in to get full access
Overview
- This paper proposes a novel multimodal fusion approach for emotion recognition in conversations.
- The approach combines a hypergraph autoencoder and contrastive learning to effectively integrate and learn representations from different modalities.
- The authors demonstrate the effectiveness of their method on several benchmark datasets for emotion recognition in conversational settings.
Plain English Explanation
The paper focuses on the task of emotion recognition in conversations. In this setting, the goal is to accurately identify the emotional state of people based on the information available from multiple sources, such as their text, audio, and visual cues.
The researchers propose a new approach that combines two key techniques:
-
Hypergraph Autoencoder: This is a type of neural network that can model complex relationships between different modalities by representing them as a hypergraph. The autoencoder learns to efficiently encode and decode this multimodal information.
-
Contrastive Learning: This is a technique that encourages the model to learn representations that are similar for related examples (e.g., different modalities of the same conversation) and different for unrelated examples. This helps the model capture the underlying connections between the modalities.
By using these two techniques together, the model is able to effectively fuse the information from different modalities and learn robust representations for accurate emotion recognition in conversations.
Technical Explanation
The proposed approach, called Multimodal Fusion via Hypergraph Autoencoder and Contrastive Learning for Emotion Recognition in Conversation, consists of several key components:
-
Hypergraph Autoencoder: The authors construct a hypergraph to represent the relationships between the different modalities (text, audio, visual). Each node in the hypergraph corresponds to a feature from a particular modality, and the hyperedges capture the complex interactions between these features. The autoencoder then learns to efficiently encode and decode this multimodal hypergraph representation.
-
Contrastive Learning: The model is trained using a contrastive loss function, which encourages the learned representations of related examples (i.e., different modalities of the same conversation) to be similar, while pushing the representations of unrelated examples to be different. This helps the model capture the underlying connections between the modalities.
-
Multimodal Fusion: The encoded representations from the hypergraph autoencoder are fused using a attention-based mechanism, which allows the model to dynamically weight the importance of each modality for the emotion recognition task.
The authors evaluate their approach on several benchmark datasets for emotion recognition in conversations, including IEMOCAP, MOSEI, and MELD. They demonstrate that their method outperforms various state-of-the-art multimodal fusion techniques, highlighting the effectiveness of the hypergraph autoencoder and contrastive learning components.
Critical Analysis
The paper presents a novel and well-designed approach for multimodal fusion in the context of emotion recognition in conversations. The key strengths of the proposed method include:
-
Effective Multimodal Representation Learning: The hypergraph autoencoder and contrastive learning components allow the model to learn robust and informative representations that capture the complex relationships between the different modalities.
-
Adaptive Multimodal Fusion: The attention-based fusion mechanism enables the model to dynamically weight the importance of each modality, which is important given that the relative importance of different modalities can vary across different conversations.
However, the paper also has a few limitations:
-
Computational Complexity: The hypergraph autoencoder and contrastive learning components may incur higher computational costs compared to simpler multimodal fusion techniques, which could be a concern for real-time applications.
-
Generalization to Other Tasks: While the authors demonstrate the effectiveness of their approach on emotion recognition in conversations, it is unclear how well the method would generalize to other multimodal tasks, such as visual question answering or multimodal machine translation.
-
Interpretability: As with many deep learning models, the internal workings of the proposed approach may be difficult to interpret, which could be a concern for applications that require more transparency.
Overall, the paper presents a promising approach for multimodal fusion in emotion recognition tasks, and the authors have demonstrated its effectiveness on several benchmark datasets. Further research could explore ways to address the computational complexity and generalization concerns, as well as investigate the model's interpretability.
Conclusion
This paper introduces a novel multimodal fusion approach for emotion recognition in conversations, combining a hypergraph autoencoder and contrastive learning. The proposed method effectively integrates and learns representations from different modalities, such as text, audio, and visual cues, and demonstrates state-of-the-art performance on several benchmark datasets. While the approach has some computational and interpretability challenges, it represents an important step forward in advancing multimodal fusion techniques for emotion recognition in conversational settings, with potential applications in areas like human-computer interaction, mental health monitoring, and customer service.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multimodal Fusion via Hypergraph Autoencoder and Contrastive Learning for Emotion Recognition in Conversation
Zijian Yi, Ziming Zhao, Zhishu Shen, Tiehua Zhang
Multimodal emotion recognition in conversation (MERC) seeks to identify the speakers' emotions expressed in each utterance, offering significant potential across diverse fields. The challenge of MERC lies in balancing speaker modeling and context modeling, encompassing both long-distance and short-distance contexts, as well as addressing the complexity of multimodal information fusion. Recent research adopts graph-based methods to model intricate conversational relationships effectively. Nevertheless, the majority of these methods utilize a fixed fully connected structure to link all utterances, relying on convolution to interpret complex context. This approach can inherently heighten the redundancy in contextual messages and excessive graph network smoothing, particularly in the context of long-distance conversations. To address this issue, we propose a framework that dynamically adjusts hypergraph connections by variational hypergraph autoencoder (VHGAE), and employs contrastive learning to mitigate uncertainty factors during the reconstruction process. Experimental results demonstrate the effectiveness of our proposal against the state-of-the-art methods on IEMOCAP and MELD datasets. We release the code to support the reproducibility of this work at https://github.com/yzjred/-HAUCL.
Read more8/6/2024

0
Efficient Long-distance Latent Relation-aware Graph Neural Network for Multi-modal Emotion Recognition in Conversations
Yuntao Shou, Wei Ai, Jiayi Du, Tao Meng, Haiyan Liu, Nan Yin
The task of multi-modal emotion recognition in conversation (MERC) aims to analyze the genuine emotional state of each utterance based on the multi-modal information in the conversation, which is crucial for conversation understanding. Existing methods focus on using graph neural networks (GNN) to model conversational relationships and capture contextual latent semantic relationships. However, due to the complexity of GNN, existing methods cannot efficiently capture the potential dependencies between long-distance utterances, which limits the performance of MERC. In this paper, we propose an Efficient Long-distance Latent Relation-aware Graph Neural Network (ELR-GNN) for multi-modal emotion recognition in conversations. Specifically, we first use pre-extracted text, video and audio features as input to Bi-LSTM to capture contextual semantic information and obtain low-level utterance features. Then, we use low-level utterance features to construct a conversational emotion interaction graph. To efficiently capture the potential dependencies between long-distance utterances, we use the dilated generalized forward push algorithm to precompute the emotional propagation between global utterances and design an emotional relation-aware operator to capture the potential semantic associations between different utterances. Furthermore, we combine early fusion and adaptive late fusion mechanisms to fuse latent dependency information between speaker relationship information and context. Finally, we obtain high-level discourse features and feed them into MLP for emotion prediction. Extensive experimental results show that ELR-GNN achieves state-of-the-art performance on the benchmark datasets IEMOCAP and MELD, with running times reduced by 52% and 35%, respectively.
Read more9/4/2024

0
Revisiting Multimodal Emotion Recognition in Conversation from the Perspective of Graph Spectrum
Tao Meng, Fuchen Zhang, Yuntao Shou, Wei Ai, Nan Yin, Keqin Li
Efficiently capturing consistent and complementary semantic features in a multimodal conversation context is crucial for Multimodal Emotion Recognition in Conversation (MERC). Existing methods mainly use graph structures to model dialogue context semantic dependencies and employ Graph Neural Networks (GNN) to capture multimodal semantic features for emotion recognition. However, these methods are limited by some inherent characteristics of GNN, such as over-smoothing and low-pass filtering, resulting in the inability to learn long-distance consistency information and complementary information efficiently. Since consistency and complementarity information correspond to low-frequency and high-frequency information, respectively, this paper revisits the problem of multimodal emotion recognition in conversation from the perspective of the graph spectrum. Specifically, we propose a Graph-Spectrum-based Multimodal Consistency and Complementary collaborative learning framework GS-MCC. First, GS-MCC uses a sliding window to construct a multimodal interaction graph to model conversational relationships and uses efficient Fourier graph operators to extract long-distance high-frequency and low-frequency information, respectively. Then, GS-MCC uses contrastive learning to construct self-supervised signals that reflect complementarity and consistent semantic collaboration with high and low-frequency signals, thereby improving the ability of high and low-frequency information to reflect real emotions. Finally, GS-MCC inputs the collaborative high and low-frequency information into the MLP network and softmax function for emotion prediction. Extensive experiments have proven the superiority of the GS-MCC architecture proposed in this paper on two benchmark data sets.
Read more5/6/2024
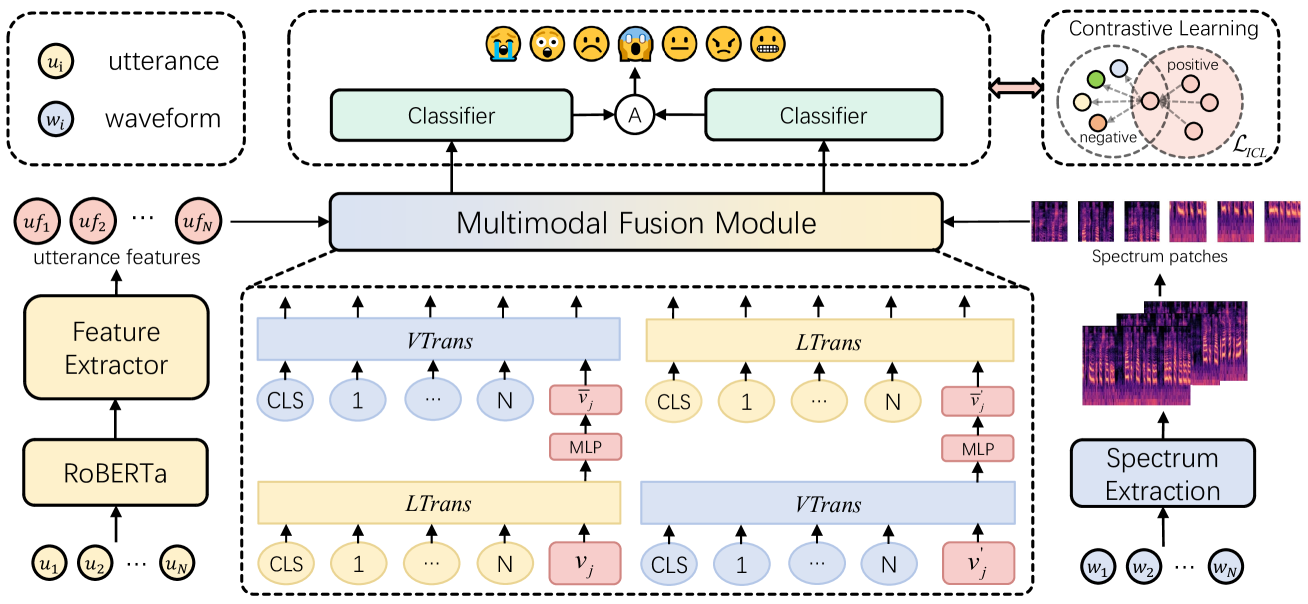
0
Enhancing Emotion Recognition in Conversation through Emotional Cross-Modal Fusion and Inter-class Contrastive Learning
Haoxiang Shi, Xulong Zhang, Ning Cheng, Yong Zhang, Jun Yu, Jing Xiao, Jianzong Wang
The purpose of emotion recognition in conversation (ERC) is to identify the emotion category of an utterance based on contextual information. Previous ERC methods relied on simple connections for cross-modal fusion and ignored the information differences between modalities, resulting in the model being unable to focus on modality-specific emotional information. At the same time, the shared information between modalities was not processed to generate emotions. Information redundancy problem. To overcome these limitations, we propose a cross-modal fusion emotion prediction network based on vector connections. The network mainly includes two stages: the multi-modal feature fusion stage based on connection vectors and the emotion classification stage based on fused features. Furthermore, we design a supervised inter-class contrastive learning module based on emotion labels. Experimental results confirm the effectiveness of the proposed method, demonstrating excellent performance on the IEMOCAP and MELD datasets.
Read more5/29/2024