Describe-then-Reason: Improving Multimodal Mathematical Reasoning through Visual Comprehension Training

0
🏋️
Sign in to get full access
Overview
- Open-source multimodal large language models (MLLMs) excel at many tasks involving text and images, but struggle with complex mathematical reasoning compared to proprietary models
- Fine-tuning MLLMs with intermediate steps (rationales) can improve their mathematical reasoning, but they still lack in visual comprehension due to inadequate visual-centric training
- The proposed VCAR approach aims to address this by first improving the visual comprehension of MLLMs through visual description generation, then training on generating rationales with the help of these descriptions
Plain English Explanation
Large language models trained on both text and images (multimodal models) are very capable at a wide variety of tasks involving both text and visuals. However, when it comes to complex mathematical reasoning, they still lag behind more specialized proprietary models like GPT-4V and Gemini-Pro.
Researchers have tried to improve the mathematical reasoning skills of these multimodal models by providing them with additional training on explaining their reasoning step-by-step (called "rationales"). This does help, but the models still struggle with accurately interpreting visual elements like mathematical figures and diagrams. This is likely because they haven't received enough targeted training on visual comprehension.
To address this, the researchers propose a new two-step training approach called VCAR. First, they train the multimodal model to get better at describing visual content in general. Then, they train it again, this time on generating those step-by-step rationales, but with the help of the visual descriptions it learned earlier.
The idea is that by first mastering the skill of understanding and describing visual information, the model will be better equipped to reason about and explain mathematical concepts that rely heavily on visual elements. The researchers' experiments show that this VCAR approach significantly outperforms previous methods, especially on problems that require strong visual comprehension.
Technical Explanation
The paper proposes a new two-step training pipeline called VCAR (Visual Comprehension and Reasoning) to improve the multimodal mathematical reasoning capabilities of open-source large language models (MLLMs).
In the first step, the model is trained on a visual description generation task to enhance its visual comprehension abilities. This helps the model develop a stronger understanding of visual elements like diagrams and figures, which are crucial for reasoning about mathematical concepts.
In the second step, the model is further trained on generating rationales - step-by-step explanations of its reasoning process. Crucially, this rationale generation is assisted by the visual descriptions the model learned in the first step. This allows the model to better ground its mathematical reasoning in the relevant visual information.
The researchers evaluate VCAR on two popular benchmarks for multimodal mathematical reasoning. They find that VCAR substantially outperforms baseline methods that only use rationale supervision, especially on problems that have high visual demands. This suggests that the two-stage training approach of first improving visual comprehension, and then using that to aid reasoning, is an effective way to boost the multimodal mathematical skills of large language models.
Critical Analysis
The paper makes a compelling case for the importance of visual comprehension in enabling robust multimodal mathematical reasoning. By systematically addressing this shortcoming in existing open-source models, the VCAR approach represents an important step forward.
However, the paper does not explore the limitations of the visual description generation task used in the first training stage. It's possible that models trained on this task may still struggle to fully capture the nuances and contextual information required for complex mathematical reasoning. Additional research may be needed to identify the optimal visual pretraining objectives and architectures.
Furthermore, the experiments are conducted on a relatively narrow set of benchmarks. It would be valuable to see how VCAR performs on a wider range of multimodal reasoning tasks, including those that involve more diverse visual inputs beyond just mathematical figures.
Finally, the paper does not discuss the computational and training resource requirements of the VCAR approach compared to other methods. This information would be useful for evaluating the scalability and practical applicability of the proposed technique.
Overall, the VCAR framework is a promising direction, but further research is needed to fully understand its strengths, weaknesses, and broader implications for advancing the state of the art in multimodal reasoning.
Conclusion
This paper presents a novel two-step training approach called VCAR that significantly improves the multimodal mathematical reasoning capabilities of open-source large language models. By first enhancing the models' visual comprehension through a description generation task, and then leveraging those visual understanding skills to aid in step-by-step reasoning, VCAR is able to outperform previous methods that solely relied on rationale supervision.
The key insight is that strong visual comprehension is crucial for tackling complex mathematical problems that involve interpreting and reasoning about various visual elements. The VCAR framework provides a principled way to address this shortcoming in existing open-source multimodal models, paving the way for more robust and capable reasoning systems.
While further research is needed to fully understand the limitations and broader applicability of this approach, the results presented in this paper represent an important advancement in the field of multimodal artificial intelligence. As the demand for AI systems that can seamlessly integrate and reason about both textual and visual information continues to grow, techniques like VCAR will become increasingly valuable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
Describe-then-Reason: Improving Multimodal Mathematical Reasoning through Visual Comprehension Training
Mengzhao Jia, Zhihan Zhang, Wenhao Yu, Fangkai Jiao, Meng Jiang
Open-source multimodal large language models (MLLMs) excel in various tasks involving textual and visual inputs but still struggle with complex multimodal mathematical reasoning, lagging behind proprietary models like GPT-4V(ision) and Gemini-Pro. Although fine-tuning with intermediate steps (i.e., rationales) elicits some mathematical reasoning skills, the resulting models still fall short in visual comprehension due to inadequate visual-centric supervision, which leads to inaccurate interpretation of math figures. To address this issue, we propose a two-step training pipeline VCAR, which emphasizes the Visual Comprehension training in Addition to mathematical Reasoning learning. It first improves the visual comprehension ability of MLLMs through the visual description generation task, followed by another training step on generating rationales with the assistance of descriptions. Experimental results on two popular benchmarks demonstrate that VCAR substantially outperforms baseline methods solely relying on rationale supervision, especially on problems with high visual demands.
Read more4/29/2024
0
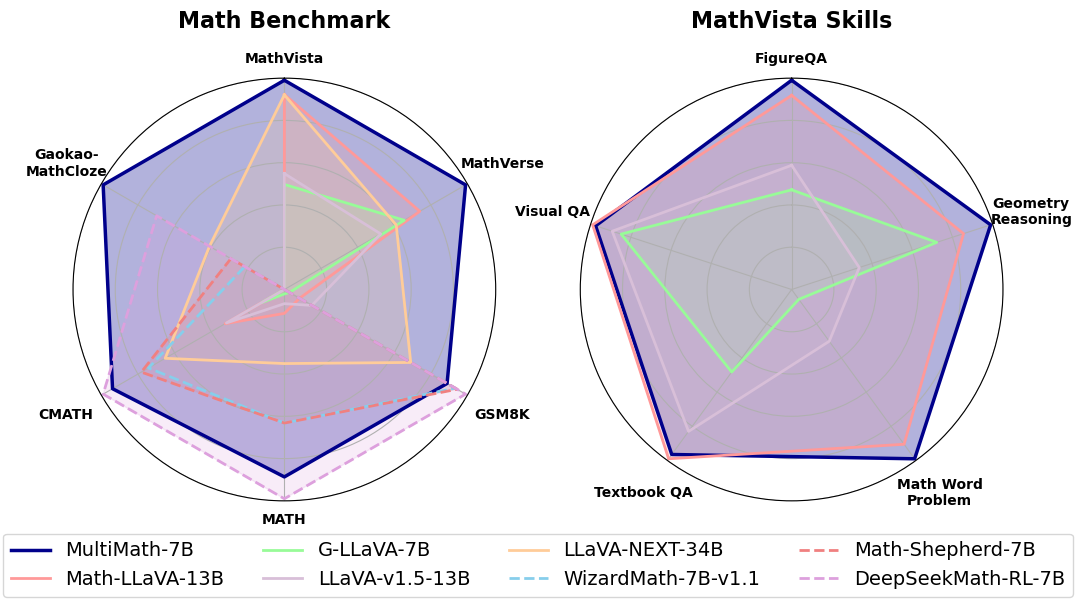
MultiMath: Bridging Visual and Mathematical Reasoning for Large Language Models
Shuai Peng, Di Fu, Liangcai Gao, Xiuqin Zhong, Hongguang Fu, Zhi Tang
The rapid development of large language models (LLMs) has spurred extensive research into their domain-specific capabilities, particularly mathematical reasoning. However, most open-source LLMs focus solely on mathematical reasoning, neglecting the integration with visual injection, despite the fact that many mathematical tasks rely on visual inputs such as geometric diagrams, charts, and function plots. To fill this gap, we introduce textbf{MultiMath-7B}, a multimodal large language model that bridges the gap between math and vision. textbf{MultiMath-7B} is trained through a four-stage process, focusing on vision-language alignment, visual and math instruction-tuning, and process-supervised reinforcement learning. We also construct a novel, diverse and comprehensive multimodal mathematical dataset, textbf{MultiMath-300K}, which spans K-12 levels with image captions and step-wise solutions. MultiMath-7B achieves state-of-the-art (SOTA) performance among open-source models on existing multimodal mathematical benchmarks and also excels on text-only mathematical benchmarks. Our model and dataset are available at {textcolor{blue}{url{https://github.com/pengshuai-rin/MultiMath}}}.
Read more9/4/2024

0
Advancing Large Multi-modal Models with Explicit Chain-of-Reasoning and Visual Question Generation
Kohei Uehara, Nabarun Goswami, Hanqin Wang, Toshiaki Baba, Kohtaro Tanaka, Tomohiro Hashimoto, Kai Wang, Rei Ito, Takagi Naoya, Ryo Umagami, Yingyi Wen, Tanachai Anakewat, Tatsuya Harada
The increasing demand for intelligent systems capable of interpreting and reasoning about visual content requires the development of large Vision-and-Language Models (VLMs) that are not only accurate but also have explicit reasoning capabilities. This paper presents a novel approach to develop a VLM with the ability to conduct explicit reasoning based on visual content and textual instructions. We introduce a system that can ask a question to acquire necessary knowledge, thereby enhancing the robustness and explicability of the reasoning process. To this end, we developed a novel dataset generated by a Large Language Model (LLM), designed to promote chain-of-thought reasoning combined with a question-asking mechanism. The dataset covers a range of tasks, from common ones like caption generation to specialized VQA tasks that require expert knowledge. Furthermore, using the dataset we created, we fine-tuned an existing VLM. This training enabled the models to generate questions and perform iterative reasoning during inference. The results demonstrated a stride toward a more robust, accurate, and interpretable VLM, capable of reasoning explicitly and seeking information proactively when confronted with ambiguous visual input.
Read more7/19/2024
0
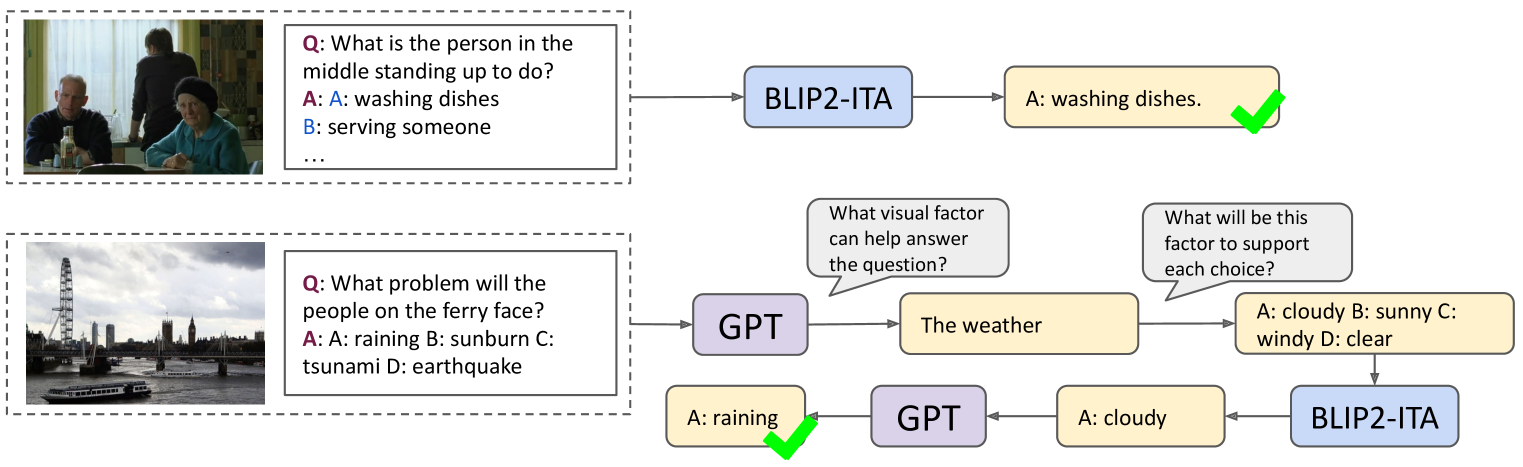
ViCor: Bridging Visual Understanding and Commonsense Reasoning with Large Language Models
Kaiwen Zhou, Kwonjoon Lee, Teruhisa Misu, Xin Eric Wang
In our work, we explore the synergistic capabilities of pre-trained vision-and-language models (VLMs) and large language models (LLMs) on visual commonsense reasoning (VCR) problems. We find that VLMs and LLMs-based decision pipelines are good at different kinds of VCR problems. Pre-trained VLMs exhibit strong performance for problems involving understanding the literal visual content, which we noted as visual commonsense understanding (VCU). For problems where the goal is to infer conclusions beyond image content, which we noted as visual commonsense inference (VCI), VLMs face difficulties, while LLMs, given sufficient visual evidence, can use commonsense to infer the answer well. We empirically validate this by letting LLMs classify VCR problems into these two categories and show the significant difference between VLM and LLM with image caption decision pipelines on two subproblems. Moreover, we identify a challenge with VLMs' passive perception, which may miss crucial context information, leading to incorrect reasoning by LLMs. Based on these, we suggest a collaborative approach, named ViCor, where pre-trained LLMs serve as problem classifiers to analyze the problem category, then either use VLMs to answer the question directly or actively instruct VLMs to concentrate on and gather relevant visual elements to support potential commonsense inferences. We evaluate our framework on two VCR benchmark datasets and outperform all other methods that do not require in-domain fine-tuning.
Read more5/20/2024