Design and Analysis of Efficient Attention in Transformers for Social Group Activity Recognition
2404.09964
0
0

Abstract
Social group activity recognition is a challenging task extended from group activity recognition, where social groups must be recognized with their activities and group members. Existing methods tackle this task by leveraging region features of individuals following existing group activity recognition methods. However, the effectiveness of region features is susceptible to person localization and variable semantics of individual actions. To overcome these issues, we propose leveraging attention modules in transformers to generate social group features. In this method, multiple embeddings are used to aggregate features for a social group, each of which is assigned to a group member without duplication. Due to this non-duplicated assignment, the number of embeddings must be significant to avoid missing group members and thus renders attention in transformers ineffective. To find optimal attention designs with a large number of embeddings, we explore several design choices of queries for feature aggregation and self-attention modules in transformer decoders. Extensive experimental results show that the proposed method achieves state-of-the-art performance and verify that the proposed attention designs are highly effective on social group activity recognition.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper presents a novel attention mechanism for transformers that improves efficiency and performance in the task of social group activity recognition.
- The proposed approach, called Efficient Attention, aims to capture the complex social interactions and group dynamics present in social scenes.
- The authors conduct extensive experiments to evaluate the effectiveness of their Efficient Attention mechanism on several benchmark datasets for social group activity recognition.
Plain English Explanation
The paper focuses on a computer vision problem called "social group activity recognition." This involves using AI models to analyze images or videos and identify the activities and interactions taking place within social groups, such as a group of people at a party or in a park.
To tackle this challenge, the researchers developed a new type of attention mechanism for transformer models. Attention is a key component of transformer models that allows them to focus on the most relevant parts of the input when making predictions. The researchers' "Efficient Attention" mechanism is designed to more effectively capture the complex social dynamics and group interactions present in these types of scenes.
Through their experiments, the authors show that their Efficient Attention transformer outperforms other state-of-the-art models on several standard benchmarks for social group activity recognition. This suggests their approach is better able to understand and recognize the nuanced group behaviors and interactions that occur in social settings.
Technical Explanation
The paper proposes a novel attention mechanism called "Efficient Attention" that is tailored for the task of social group activity recognition. Mansformer: Efficient Transformer with Mixed Attention for Image Deblurring and Transformer-based Model for Prediction of Human Gaze Behavior are two related works that also explore efficient attention mechanisms for vision-based tasks.
The key idea behind Efficient Attention is to capture the interactions and dynamics within social groups more effectively than standard attention. The authors observe that in social scenes, individuals' actions and behaviors are heavily influenced by their group context and the actions of others around them.
To model these complex social dependencies, the Efficient Attention mechanism incorporates three main components:
- Spatial Attention: This focuses on modeling the spatial relationships and proximity between individuals in the scene.
- Temporal Attention: This captures the temporal dynamics and evolution of group activities over time.
- Relational Attention: This models the higher-level social relationships and interactions between individuals and groups.
Abstractors: Relational Cross-Attention with Inductive Bias is another related work that explores the importance of relational attention for understanding social interactions.
The authors integrate these three attention modules into a transformer-based architecture and demonstrate its effectiveness on several social group activity recognition benchmarks. Their experiments show that the Efficient Attention mechanism outperforms standard attention-based transformers and other state-of-the-art approaches.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the Efficient Attention mechanism. The authors carefully ablate the different components of their approach and provide detailed analysis to understand the contributions of each attention module.
However, one potential limitation is that the experiments are primarily conducted on existing benchmark datasets, which may not fully capture the diversity and complexity of real-world social group activities. Modeling Social Interaction Dynamics Using Temporal Graph is a related work that explores the challenges of modeling social dynamics in more naturalistic settings.
Additionally, while the Efficient Attention mechanism shows promising results, it is still a relatively complex model with multiple attention modules. Further research could explore ways to simplify the architecture without sacrificing performance, which would be important for practical deployment in real-world applications.
Overall, the paper makes a valuable contribution to the field of social group activity recognition, and the Efficient Attention mechanism represents an important step forward in developing more efficient and effective transformer-based models for understanding complex social dynamics.
Conclusion
The paper presents a novel attention mechanism called Efficient Attention that is designed to improve the performance of transformer models on the task of social group activity recognition. Through extensive experiments, the authors demonstrate that their approach outperforms standard attention-based transformers and other state-of-the-art methods on several benchmark datasets.
The key innovation of Efficient Attention is its ability to more effectively capture the spatial, temporal, and relational aspects of social interactions within group settings. This allows the model to better understand the complex dynamics and dependencies that govern how individuals behave and interact within a social group context.
The successful application of Efficient Attention to social group activity recognition suggests that it could be a useful technique for a broader range of computer vision and multimodal tasks involving the understanding of human behavior and social interactions. Further research exploring the generalizability and efficiency of this approach would be an important next step.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Hierarchical Point Attention for Indoor 3D Object Detection
Manli Shu, Le Xue, Ning Yu, Roberto Mart'in-Mart'in, Caiming Xiong, Tom Goldstein, Juan Carlos Niebles, Ran Xu
0
0
3D object detection is an essential vision technique for various robotic systems, such as augmented reality and domestic robots. Transformers as versatile network architectures have recently seen great success in 3D point cloud object detection. However, the lack of hierarchy in a plain transformer restrains its ability to learn features at different scales. Such limitation makes transformer detectors perform worse on smaller objects and affects their reliability in indoor environments where small objects are the majority. This work proposes two novel attention operations as generic hierarchical designs for point-based transformer detectors. First, we propose Aggregated Multi-Scale Attention (MS-A) that builds multi-scale tokens from a single-scale input feature to enable more fine-grained feature learning. Second, we propose Size-Adaptive Local Attention (Local-A) with adaptive attention regions for localized feature aggregation within bounding box proposals. Both attention operations are model-agnostic network modules that can be plugged into existing point cloud transformers for end-to-end training. We evaluate our method on two widely used indoor detection benchmarks. By plugging our proposed modules into the state-of-the-art transformer-based 3D detectors, we improve the previous best results on both benchmarks, with more significant improvements on smaller objects.
5/10/2024
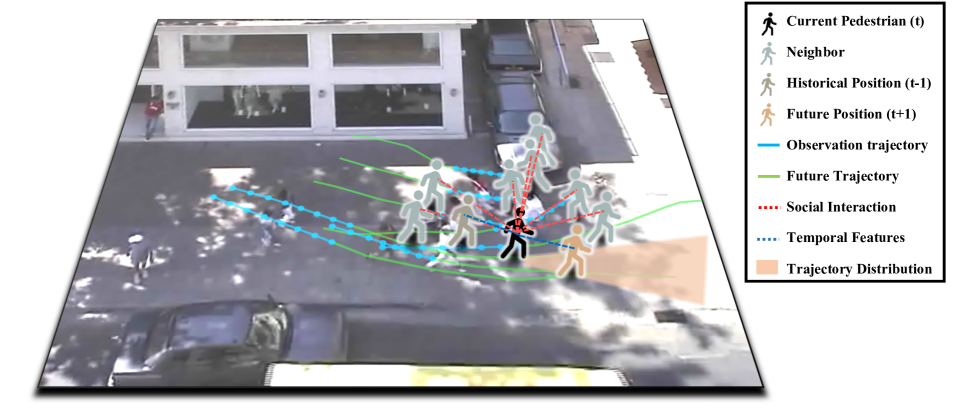
Attention-aware Social Graph Transformer Networks for Stochastic Trajectory Prediction
Yao Liu, Binghao Li, Xianzhi Wang, Claude Sammut, Lina Yao
0
0
Trajectory prediction is fundamental to various intelligent technologies, such as autonomous driving and robotics. The motion prediction of pedestrians and vehicles helps emergency braking, reduces collisions, and improves traffic safety. Current trajectory prediction research faces problems of complex social interactions, high dynamics and multi-modality. Especially, it still has limitations in long-time prediction. We propose Attention-aware Social Graph Transformer Networks for multi-modal trajectory prediction. We combine Graph Convolutional Networks and Transformer Networks by generating stable resolution pseudo-images from Spatio-temporal graphs through a designed stacking and interception method. Furthermore, we design the attention-aware module to handle social interaction information in scenarios involving mixed pedestrian-vehicle traffic. Thus, we maintain the advantages of the Graph and Transformer, i.e., the ability to aggregate information over an arbitrary number of neighbors and the ability to perform complex time-dependent data processing. We conduct experiments on datasets involving pedestrian, vehicle, and mixed trajectories, respectively. Our results demonstrate that our model minimizes displacement errors across various metrics and significantly reduces the likelihood of collisions. It is worth noting that our model effectively reduces the final displacement error, illustrating the ability of our model to predict for a long time.
5/14/2024
👁️
Human Activity Recognition from Wearable Sensor Data Using Self-Attention
Saif Mahmud, M Tanjid Hasan Tonmoy, Kishor Kumar Bhaumik, A K M Mahbubur Rahman, M Ashraful Amin, Mohammad Shoyaib, Muhammad Asif Hossain Khan, Amin Ahsan Ali
0
0
Human Activity Recognition from body-worn sensor data poses an inherent challenge in capturing spatial and temporal dependencies of time-series signals. In this regard, the existing recurrent or convolutional or their hybrid models for activity recognition struggle to capture spatio-temporal context from the feature space of sensor reading sequence. To address this complex problem, we propose a self-attention based neural network model that foregoes recurrent architectures and utilizes different types of attention mechanisms to generate higher dimensional feature representation used for classification. We performed extensive experiments on four popular publicly available HAR datasets: PAMAP2, Opportunity, Skoda and USC-HAD. Our model achieve significant performance improvement over recent state-of-the-art models in both benchmark test subjects and Leave-one-subject-out evaluation. We also observe that the sensor attention maps produced by our model is able capture the importance of the modality and placement of the sensors in predicting the different activity classes.
4/23/2024
👀
Enhancing Efficiency in Vision Transformer Networks: Design Techniques and Insights
Moein Heidari, Reza Azad, Sina Ghorbani Kolahi, Ren'e Arimond, Leon Niggemeier, Alaa Sulaiman, Afshin Bozorgpour, Ehsan Khodapanah Aghdam, Amirhossein Kazerouni, Ilker Hacihaliloglu, Dorit Merhof
0
0
Intrigued by the inherent ability of the human visual system to identify salient regions in complex scenes, attention mechanisms have been seamlessly integrated into various Computer Vision (CV) tasks. Building upon this paradigm, Vision Transformer (ViT) networks exploit attention mechanisms for improved efficiency. This review navigates the landscape of redesigned attention mechanisms within ViTs, aiming to enhance their performance. This paper provides a comprehensive exploration of techniques and insights for designing attention mechanisms, systematically reviewing recent literature in the field of CV. This survey begins with an introduction to the theoretical foundations and fundamental concepts underlying attention mechanisms. We then present a systematic taxonomy of various attention mechanisms within ViTs, employing redesigned approaches. A multi-perspective categorization is proposed based on their application, objectives, and the type of attention applied. The analysis includes an exploration of the novelty, strengths, weaknesses, and an in-depth evaluation of the different proposed strategies. This culminates in the development of taxonomies that highlight key properties and contributions. Finally, we gather the reviewed studies along with their available open-source implementations at our href{https://github.com/mindflow-institue/Awesome-Attention-Mechanism-in-Medical-Imaging}{GitHub}footnote{url{https://github.com/xmindflow/Awesome-Attention-Mechanism-in-Medical-Imaging}}. We aim to regularly update it with the most recent relevant papers.
4/1/2024