Enhancing Efficiency in Vision Transformer Networks: Design Techniques and Insights
2403.19882
0
0
👀
Abstract
Intrigued by the inherent ability of the human visual system to identify salient regions in complex scenes, attention mechanisms have been seamlessly integrated into various Computer Vision (CV) tasks. Building upon this paradigm, Vision Transformer (ViT) networks exploit attention mechanisms for improved efficiency. This review navigates the landscape of redesigned attention mechanisms within ViTs, aiming to enhance their performance. This paper provides a comprehensive exploration of techniques and insights for designing attention mechanisms, systematically reviewing recent literature in the field of CV. This survey begins with an introduction to the theoretical foundations and fundamental concepts underlying attention mechanisms. We then present a systematic taxonomy of various attention mechanisms within ViTs, employing redesigned approaches. A multi-perspective categorization is proposed based on their application, objectives, and the type of attention applied. The analysis includes an exploration of the novelty, strengths, weaknesses, and an in-depth evaluation of the different proposed strategies. This culminates in the development of taxonomies that highlight key properties and contributions. Finally, we gather the reviewed studies along with their available open-source implementations at our href{https://github.com/mindflow-institue/Awesome-Attention-Mechanism-in-Medical-Imaging}{GitHub}footnote{url{https://github.com/xmindflow/Awesome-Attention-Mechanism-in-Medical-Imaging}}. We aim to regularly update it with the most recent relevant papers.
Get summaries of the top AI research delivered straight to your inbox:
The paper provides a comprehensive review of redesigned attention mechanisms within Vision Transformer (ViT) networks. It explores various techniques and insights for designing attention mechanisms to enhance the performance of ViTs in computer vision tasks.
The review begins by introducing the theoretical foundations and fundamental concepts underlying attention mechanisms. It then presents a systematic taxonomy of various attention mechanisms within ViTs, categorizing them based on their application, objectives, and the type of attention applied.
The analysis includes an evaluation of the novelty, strengths, weaknesses, and an in-depth assessment of different proposed strategies. The paper aims to develop taxonomies that highlight the key properties and contributions of these attention mechanisms.
Furthermore, the authors have compiled the reviewed studies along with their available open-source implementations and made them available on a GitHub repository. They intend to regularly update the repository with the most recent relevant papers in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Visual Attention Methods in Deep Learning: An In-Depth Survey
Mohammed Hassanin, Saeed Anwar, Ibrahim Radwan, Fahad S Khan, Ajmal Mian
0
0
Inspired by the human cognitive system, attention is a mechanism that imitates the human cognitive awareness about specific information, amplifying critical details to focus more on the essential aspects of data. Deep learning has employed attention to boost performance for many applications. Interestingly, the same attention design can suit processing different data modalities and can easily be incorporated into large networks. Furthermore, multiple complementary attention mechanisms can be incorporated into one network. Hence, attention techniques have become extremely attractive. However, the literature lacks a comprehensive survey on attention techniques to guide researchers in employing attention in their deep models. Note that, besides being demanding in terms of training data and computational resources, transformers only cover a single category in self-attention out of the many categories available. We fill this gap and provide an in-depth survey of 50 attention techniques, categorizing them by their most prominent features. We initiate our discussion by introducing the fundamental concepts behind the success of the attention mechanism. Next, we furnish some essentials such as the strengths and limitations of each attention category, describe their fundamental building blocks, basic formulations with primary usage, and applications specifically for computer vision. We also discuss the challenges and general open questions related to attention mechanisms. Finally, we recommend possible future research directions for deep attention. All the information about visual attention methods in deep learning is provided at href{https://github.com/saeed-anwar/VisualAttention}{https://github.com/saeed-anwar/VisualAttention}
5/7/2024
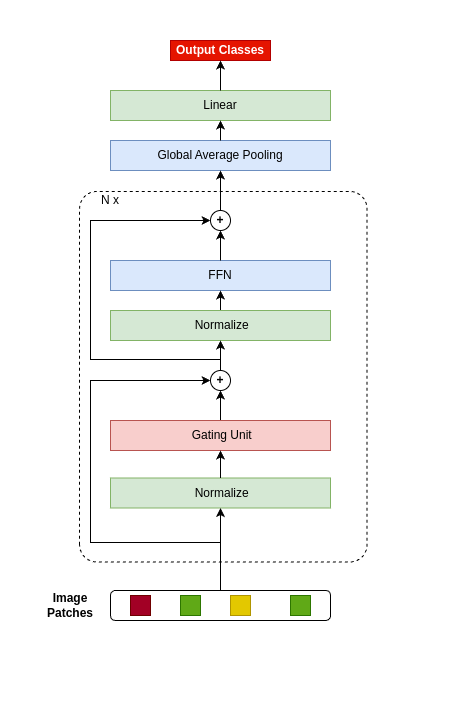
NiNformer: A Network in Network Transformer with Token Mixing Generated Gating Function
Abdullah Nazhat Abdullah, Tarkan Aydin
0
0
The Attention mechanism is the main component of the Transformer architecture, and since its introduction, it has led to significant advancements in Deep Learning that span many domains and multiple tasks. The Attention Mechanism was utilized in Computer Vision as the Vision Transformer ViT, and its usage has expanded into many tasks in the vision domain, such as classification, segmentation, object detection, and image generation. While this mechanism is very expressive and capable, it comes with the drawback of being computationally expensive and requiring datasets of considerable size for effective optimization. To address these shortcomings, many designs have been proposed in the literature to reduce the computational burden and alleviate the data size requirements. Examples of such attempts in the vision domain are the MLP-Mixer, the Conv-Mixer, the Perciver-IO, and many more. This paper introduces a new computational block as an alternative to the standard ViT block that reduces the compute burdens by replacing the normal Attention layers with a Network in Network structure that enhances the static approach of the MLP Mixer with a dynamic system of learning an element-wise gating function by a token mixing process. Extensive experimentation shows that the proposed design provides better performance than the baseline architectures on multiple datasets applied in the image classification task of the vision domain.
4/26/2024
👀
Masked Attention as a Mechanism for Improving Interpretability of Vision Transformers
Cl'ement Grisi, Geert Litjens, Jeroen van der Laak
0
0
Vision Transformers are at the heart of the current surge of interest in foundation models for histopathology. They process images by breaking them into smaller patches following a regular grid, regardless of their content. Yet, not all parts of an image are equally relevant for its understanding. This is particularly true in computational pathology where background is completely non-informative and may introduce artefacts that could mislead predictions. To address this issue, we propose a novel method that explicitly masks background in Vision Transformers' attention mechanism. This ensures tokens corresponding to background patches do not contribute to the final image representation, thereby improving model robustness and interpretability. We validate our approach using prostate cancer grading from whole-slide images as a case study. Our results demonstrate that it achieves comparable performance with plain self-attention while providing more accurate and clinically meaningful attention heatmaps.
4/30/2024
👀
Which Transformer to Favor: A Comparative Analysis of Efficiency in Vision Transformers
Tobias Christian Nauen, Sebastian Palacio, Andreas Dengel
0
0
Transformers come with a high computational cost, yet their effectiveness in addressing problems in language and vision has sparked extensive research aimed at enhancing their efficiency. However, diverse experimental conditions, spanning multiple input domains, prevent a fair comparison based solely on reported results, posing challenges for model selection. To address this gap in comparability, we design a comprehensive benchmark of more than 30 models for image classification, evaluating key efficiency aspects, including accuracy, speed, and memory usage. This benchmark provides a standardized baseline across the landscape of efficiency-oriented transformers and our framework of analysis, based on Pareto optimality, reveals surprising insights. Despite claims of other models being more efficient, ViT remains Pareto optimal across multiple metrics. We observe that hybrid attention-CNN models exhibit remarkable inference memory- and parameter-efficiency. Moreover, our benchmark shows that using a larger model in general is more efficient than using higher resolution images. Thanks to our holistic evaluation, we provide a centralized resource for practitioners and researchers, facilitating informed decisions when selecting transformers or measuring progress of the development of efficient transformers.
4/15/2024