Design and Optimization of Hierarchical Gradient Coding for Distributed Learning at Edge Devices

0

Sign in to get full access
Overview
- Distributed learning at edge devices
- Hierarchical gradient coding to improve tolerance for slow or "straggler" devices
- Optimization of the hierarchical coding scheme for efficiency
Plain English Explanation
Design and Optimization of Hierarchical Gradient Coding for Distributed Learning at Edge Devices explores a technique called hierarchical gradient coding to make distributed learning at the network edge more robust and efficient.
In distributed learning, multiple devices work together to train a shared machine learning model. However, the process can be slowed down if some devices (known as "stragglers") take longer to complete their work. Hierarchical gradient coding aims to minimize the impact of these stragglers by encoding the gradients (the steps used to update the model) in a way that allows the system to recover the full gradient even if some devices are slow.
The researchers optimized this hierarchical coding scheme to balance factors like communication overhead, storage requirements, and resilience to stragglers. This allows the distributed learning system to operate more efficiently and effectively, even when dealing with unreliable or inconsistent devices at the network edge.
Technical Explanation
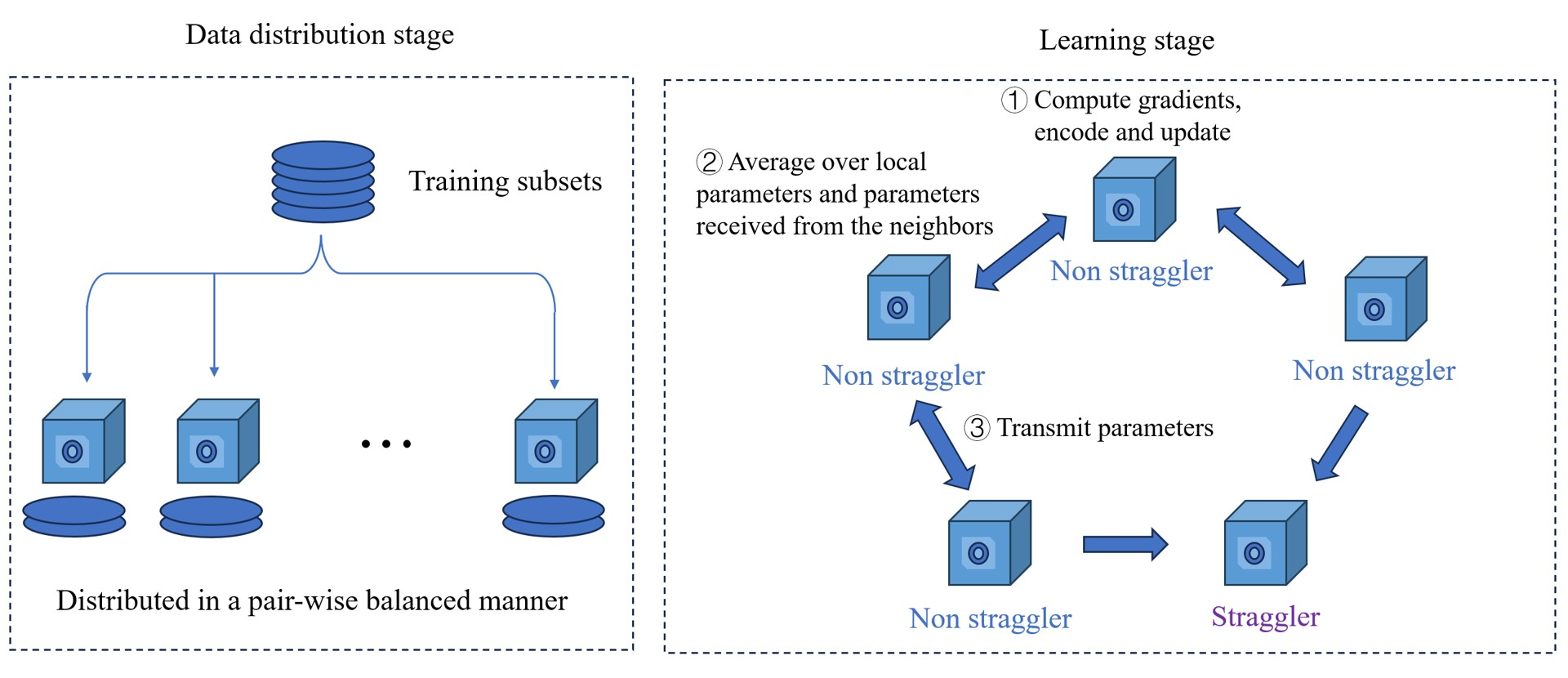
Design and Optimization of Hierarchical Gradient Coding for Distributed Learning at Edge Devices proposes a hierarchical gradient coding approach to improve the tolerance for stragglers in distributed learning at the edge.
The key technical elements include:
-
Hierarchical Coding Architecture: The gradients are encoded in a hierarchical manner, allowing the full gradient to be recovered even if some devices are slow or unavailable.
-
Optimization Framework: The researchers developed an optimization framework to tune the hierarchical coding scheme, balancing factors like communication overhead, storage requirements, and resilience to stragglers.
-
Experiments: The team evaluated their approach on various machine learning tasks and simulated scenarios with different straggler patterns. The results showed significant improvements in convergence speed and model accuracy compared to baseline methods.
This work builds upon previous research in coded computing, communication-efficient distributed learning, and approximate gradient coding, aiming to make distributed learning at the edge more robust and efficient in the face of straggling and delay.
Critical Analysis
The paper presents a well-designed and thorough approach to hierarchical gradient coding for distributed learning at the edge. The optimization framework and experimental evaluations provide a strong foundation for the proposed technique.
However, the authors acknowledge that the hierarchical coding scheme may introduce additional communication and storage overhead compared to simpler approaches. Additionally, the paper does not address potential issues related to data privacy and security in the distributed learning context.
Further research could explore ways to minimize the overhead of the hierarchical coding, perhaps by integrating it with other communication-efficient techniques. Investigating the interplay between hierarchical coding and privacy-preserving mechanisms, such as differential privacy or secure multi-party computation, could also be an interesting avenue for future work.
Conclusion
Design and Optimization of Hierarchical Gradient Coding for Distributed Learning at Edge Devices presents a promising approach to making distributed learning at the edge more robust and efficient. By using a hierarchical gradient coding scheme, the system can better tolerate slow or unreliable devices, leading to faster convergence and higher model accuracy.
The optimization framework and experimental results demonstrate the potential of this technique to advance the state of the art in distributed learning, particularly in the context of edge computing where device heterogeneity and unreliability are common challenges. While the approach has some inherent overhead, the benefits in terms of straggler tolerance and learning performance could make it a valuable tool for a wide range of applications.
Overall, this research contributes to the ongoing efforts to enable efficient and reliable distributed learning, paving the way for more advanced and practical applications of machine learning at the network edge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Design and Optimization of Hierarchical Gradient Coding for Distributed Learning at Edge Devices
Weiheng Tang, Jingyi Li, Lin Chen, Xu Chen
Edge computing has recently emerged as a promising paradigm to boost the performance of distributed learning by leveraging the distributed resources at edge nodes. Architecturally, the introduction of edge nodes adds an additional intermediate layer between the master and workers in the original distributed learning systems, potentially leading to more severe straggler effect. Recently, coding theory-based approaches have been proposed for stragglers mitigation in distributed learning, but the majority focus on the conventional workers-master architecture. In this paper, along a different line, we investigate the problem of mitigating the straggler effect in hierarchical distributed learning systems with an additional layer composed of edge nodes. Technically, we first derive the fundamental trade-off between the computational loads of workers and the stragglers tolerance. Then, we propose a hierarchical gradient coding framework, which provides better stragglers mitigation, to achieve the derived computational trade-off. To further improve the performance of our framework in heterogeneous scenarios, we formulate an optimization problem with the objective of minimizing the expected execution time for each iteration in the learning process. We develop an efficient algorithm to mathematically solve the problem by outputting the optimum strategy. Extensive simulation results demonstrate the superiority of our schemes compared with conventional solutions.
Read more6/18/2024
0
Gradient Coding in Decentralized Learning for Evading Stragglers
Chengxi Li, Mikael Skoglund
In this paper, we consider a decentralized learning problem in the presence of stragglers. Although gradient coding techniques have been developed for distributed learning to evade stragglers, where the devices send encoded gradients with redundant training data, it is difficult to apply those techniques directly to decentralized learning scenarios. To deal with this problem, we propose a new gossip-based decentralized learning method with gradient coding (GOCO). In the proposed method, to avoid the negative impact of stragglers, the parameter vectors are updated locally using encoded gradients based on the framework of stochastic gradient coding and then averaged in a gossip-based manner. We analyze the convergence performance of GOCO for strongly convex loss functions. And we also provide simulation results to demonstrate the superiority of the proposed method in terms of learning performance compared with the baseline methods.
Read more6/17/2024

0
Sparsity-Preserving Encodings for Straggler-Optimal Distributed Matrix Computations at the Edge
Anindya Bijoy Das, Aditya Ramamoorthy, David J. Love, Christopher G. Brinton
Matrix computations are a fundamental building-block of edge computing systems, with a major recent uptick in demand due to their use in AI/ML training and inference procedures. Existing approaches for distributing matrix computations involve allocating coded combinations of submatrices to worker nodes, to build resilience to slower nodes, called stragglers. In the edge learning context, however, these approaches will compromise sparsity properties that are often present in the original matrices found at the edge server. In this study, we consider the challenge of augmenting such approaches to preserve input sparsity when distributing the task across edge devices, thereby retaining the associated computational efficiency enhancements. First, we find a lower bound on the weight of coding, i.e., the number of submatrices to be combined to obtain coded submatrices, to provide the resilience to the maximum possible number of straggler devices (for given number of devices and their storage constraints). Next we propose distributed matrix computation schemes which meet the exact lower bound on the weight of the coding. Numerical experiments conducted in Amazon Web Services (AWS) validate our assertions regarding straggler mitigation and computation speed for sparse matrices.
Read more8/12/2024
🤿
0
New!A Dynamic Weighting Strategy to Mitigate Worker Node Failure in Distributed Deep Learning
Yuesheng Xu, Arielle Carr
The increasing complexity of deep learning models and the demand for processing vast amounts of data make the utilization of large-scale distributed systems for efficient training essential. These systems, however, face significant challenges such as communication overhead, hardware limitations, and node failure. This paper investigates various optimization techniques in distributed deep learning, including Elastic Averaging SGD (EASGD) and the second-order method AdaHessian. We propose a dynamic weighting strategy to mitigate the problem of straggler nodes due to failure, enhancing the performance and efficiency of the overall training process. We conduct experiments with different numbers of workers and communication periods to demonstrate improved convergence rates and test performance using our strategy.
Read more9/17/2024