Gradient Coding in Decentralized Learning for Evading Stragglers

0
Sign in to get full access
Overview
- This paper proposes a gradient coding technique for decentralized learning to mitigate the impact of stragglers, which are nodes that take longer to complete their computations.
- The approach aims to improve the robustness and efficiency of decentralized learning systems, which are increasingly important for privacy-preserving and resource-constrained environments.
Plain English Explanation
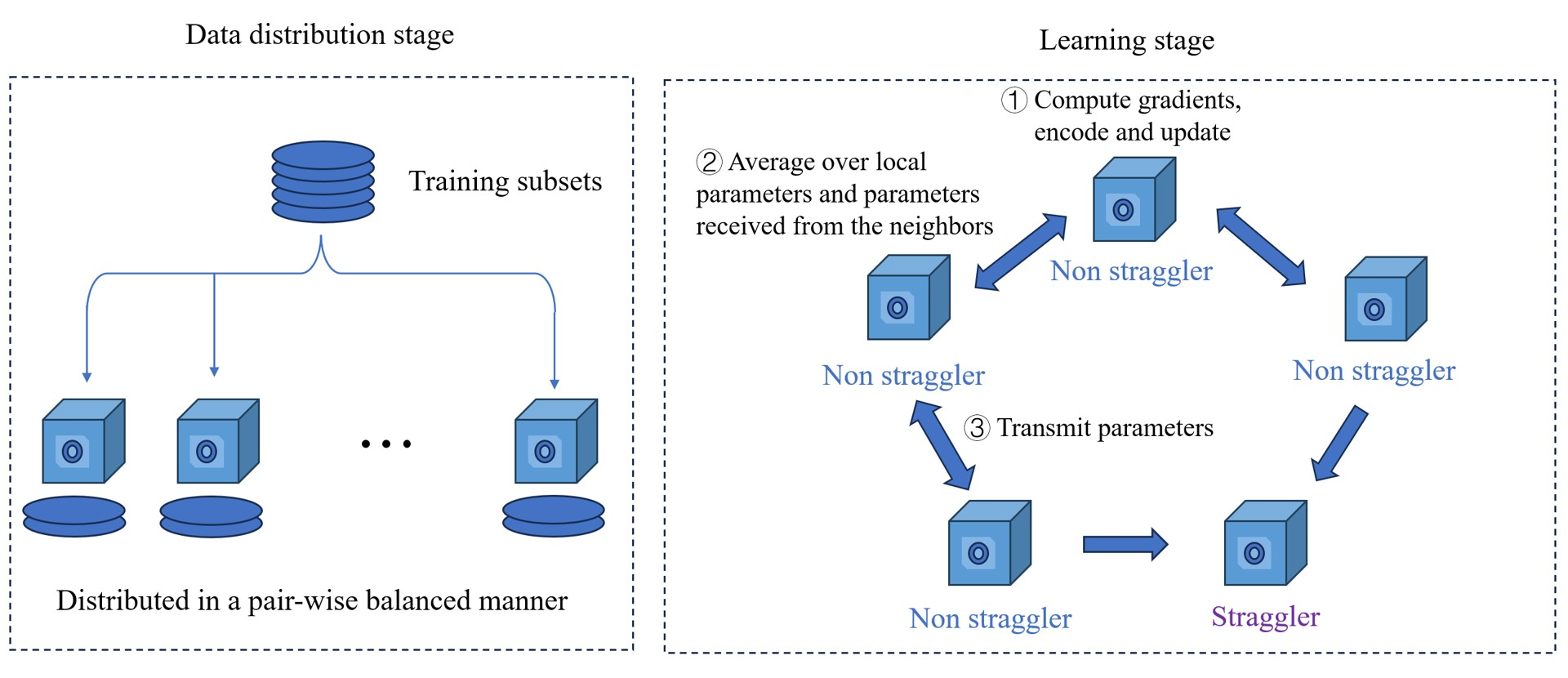
In decentralized learning, multiple devices or nodes work together to train a machine learning model without a central coordinator. This can be more privacy-preserving and efficient than traditional centralized approaches. However, some nodes may take longer than others to complete their computations, causing delays and slowing down the overall training process. These slower nodes are called "stragglers."
The researchers in this paper have developed a new technique called "gradient coding" to help address the straggler problem in decentralized learning. The key idea is to split up the gradient computations across the nodes in a strategic way, so that even if some nodes are slow, the central coordinator can still recover the full gradient and continue the training process.
This is like dividing a task among a group of people, but instead of giving each person a complete subtask, you give them smaller pieces that can be combined later. That way, if one person takes longer, you can still finish the overall task by using the work done by the other people.
The paper shows through analysis and experiments that this gradient coding approach can improve the robustness and efficiency of decentralized learning systems, making them more practical for real-world applications that require privacy and resource-constrained environments.
Technical Explanation
The paper proposes a gradient coding technique to address the straggler problem in decentralized learning. In decentralized learning, multiple nodes collaboratively train a machine learning model without a central coordinator, which can improve privacy and efficiency compared to traditional centralized approaches. However, the presence of stragglers, or nodes that take longer to complete their computations, can significantly slow down the overall training process.
The key idea of the gradient coding approach is to strategically partition the gradient computation across the nodes, so that the central coordinator can still recover the full gradient even if some nodes are slow. This is achieved by encoding the gradients using an erasure coding scheme, similar to how data is encoded for fault-tolerant storage systems.
The paper provides a theoretical analysis of the proposed gradient coding scheme, showing that it can provide guaranteed recovery of the full gradient as long as a sufficient number of nodes complete their computations on time. The authors also conduct experiments on both synthetic and real-world datasets, demonstrating the effectiveness of the gradient coding approach in improving the robustness and efficiency of decentralized learning compared to baseline methods.
Critical Analysis
The paper presents a well-designed gradient coding technique to mitigate the impact of stragglers in decentralized learning systems. The theoretical analysis and experimental results provide a strong case for the practical utility of this approach.
One potential limitation mentioned in the paper is the additional communication overhead required to implement the gradient coding scheme. This could be a concern in resource-constrained environments with limited bandwidth or energy. The authors suggest that future work could explore ways to reduce this overhead, for example, by incorporating privacy-preserving mechanisms or using more efficient coding schemes.
Another area for future research could be investigating the robustness of the gradient coding approach to adversarial attacks or Byzantine failures, where some nodes may behave maliciously or provide incorrect updates. Extending the gradient coding scheme to handle such scenarios could further enhance the reliability of decentralized learning systems.
Conclusion
This paper presents a novel gradient coding technique to address the straggler problem in decentralized learning. By strategically partitioning and encoding the gradient computations across nodes, the proposed approach can improve the robustness and efficiency of decentralized learning systems, making them more practical for real-world applications that require privacy and resource-constrained environments.
The theoretical analysis and experimental results demonstrate the effectiveness of the gradient coding approach, and the authors highlight potential areas for future research to further enhance the scalability and security of decentralized learning. Overall, this work represents an important contribution to the field of decentralized machine learning, which is crucial for enabling privacy-preserving and resource-efficient AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Gradient Coding in Decentralized Learning for Evading Stragglers
Chengxi Li, Mikael Skoglund
In this paper, we consider a decentralized learning problem in the presence of stragglers. Although gradient coding techniques have been developed for distributed learning to evade stragglers, where the devices send encoded gradients with redundant training data, it is difficult to apply those techniques directly to decentralized learning scenarios. To deal with this problem, we propose a new gossip-based decentralized learning method with gradient coding (GOCO). In the proposed method, to avoid the negative impact of stragglers, the parameter vectors are updated locally using encoded gradients based on the framework of stochastic gradient coding and then averaged in a gossip-based manner. We analyze the convergence performance of GOCO for strongly convex loss functions. And we also provide simulation results to demonstrate the superiority of the proposed method in terms of learning performance compared with the baseline methods.
Read more6/17/2024

0
Design and Optimization of Hierarchical Gradient Coding for Distributed Learning at Edge Devices
Weiheng Tang, Jingyi Li, Lin Chen, Xu Chen
Edge computing has recently emerged as a promising paradigm to boost the performance of distributed learning by leveraging the distributed resources at edge nodes. Architecturally, the introduction of edge nodes adds an additional intermediate layer between the master and workers in the original distributed learning systems, potentially leading to more severe straggler effect. Recently, coding theory-based approaches have been proposed for stragglers mitigation in distributed learning, but the majority focus on the conventional workers-master architecture. In this paper, along a different line, we investigate the problem of mitigating the straggler effect in hierarchical distributed learning systems with an additional layer composed of edge nodes. Technically, we first derive the fundamental trade-off between the computational loads of workers and the stragglers tolerance. Then, we propose a hierarchical gradient coding framework, which provides better stragglers mitigation, to achieve the derived computational trade-off. To further improve the performance of our framework in heterogeneous scenarios, we formulate an optimization problem with the objective of minimizing the expected execution time for each iteration in the learning process. We develop an efficient algorithm to mathematically solve the problem by outputting the optimum strategy. Extensive simulation results demonstrate the superiority of our schemes compared with conventional solutions.
Read more6/18/2024

0
Approximate Gradient Coding for Privacy-Flexible Federated Learning with Non-IID Data
Okko Makkonen, Sampo Niemela, Camilla Hollanti, Serge Kas Hanna
This work focuses on the challenges of non-IID data and stragglers/dropouts in federated learning. We introduce and explore a privacy-flexible paradigm that models parts of the clients' local data as non-private, offering a more versatile and business-oriented perspective on privacy. Within this framework, we propose a data-driven strategy for mitigating the effects of label heterogeneity and client straggling on federated learning. Our solution combines both offline data sharing and approximate gradient coding techniques. Through numerical simulations using the MNIST dataset, we demonstrate that our approach enables achieving a deliberate trade-off between privacy and utility, leading to improved model convergence and accuracy while using an adaptable portion of non-private data.
Read more4/5/2024
⛏️
0
Non-Coherent Over-the-Air Decentralized Gradient Descent
Nicolo' Michelusi
Implementing Decentralized Gradient Descent (DGD) in wireless systems is challenging due to noise, fading, and limited bandwidth, necessitating topology awareness, transmission scheduling, and the acquisition of channel state information (CSI) to mitigate interference and maintain reliable communications. These operations may result in substantial signaling overhead and scalability challenges in large networks lacking central coordination. This paper introduces a scalable DGD algorithm that eliminates the need for scheduling, topology information, or CSI (both average and instantaneous). At its core is a Non-Coherent Over-The-Air (NCOTA) consensus scheme that exploits a noisy energy superposition property of wireless channels. Nodes encode their local optimization signals into energy levels within an OFDM frame and transmit simultaneously, without coordination. The key insight is that the received energy equals, on average, the sum of the energies of the transmitted signals, scaled by their respective average channel gains, akin to a consensus step. This property enables unbiased consensus estimation, utilizing average channel gains as mixing weights, thereby removing the need for their explicit design or for CSI. Introducing a consensus stepsize mitigates consensus estimation errors due to energy fluctuations around their expected values. For strongly-convex problems, it is shown that the expected squared distance between the local and globally optimum models vanishes at a rate of O(1/sqrt{k}) after k iterations, with suitable decreasing learning and consensus stepsizes. Extensions accommodate a broad class of fading models and frequency-selective channels. Numerical experiments on image classification demonstrate faster convergence in terms of running time compared to state-of-the-art schemes, especially in dense network scenarios.
Read more9/14/2024