Detection of Temporality at Discourse Level on Financial News by Combining Natural Language Processing and Machine Learning
2404.01337
0
0
Abstract
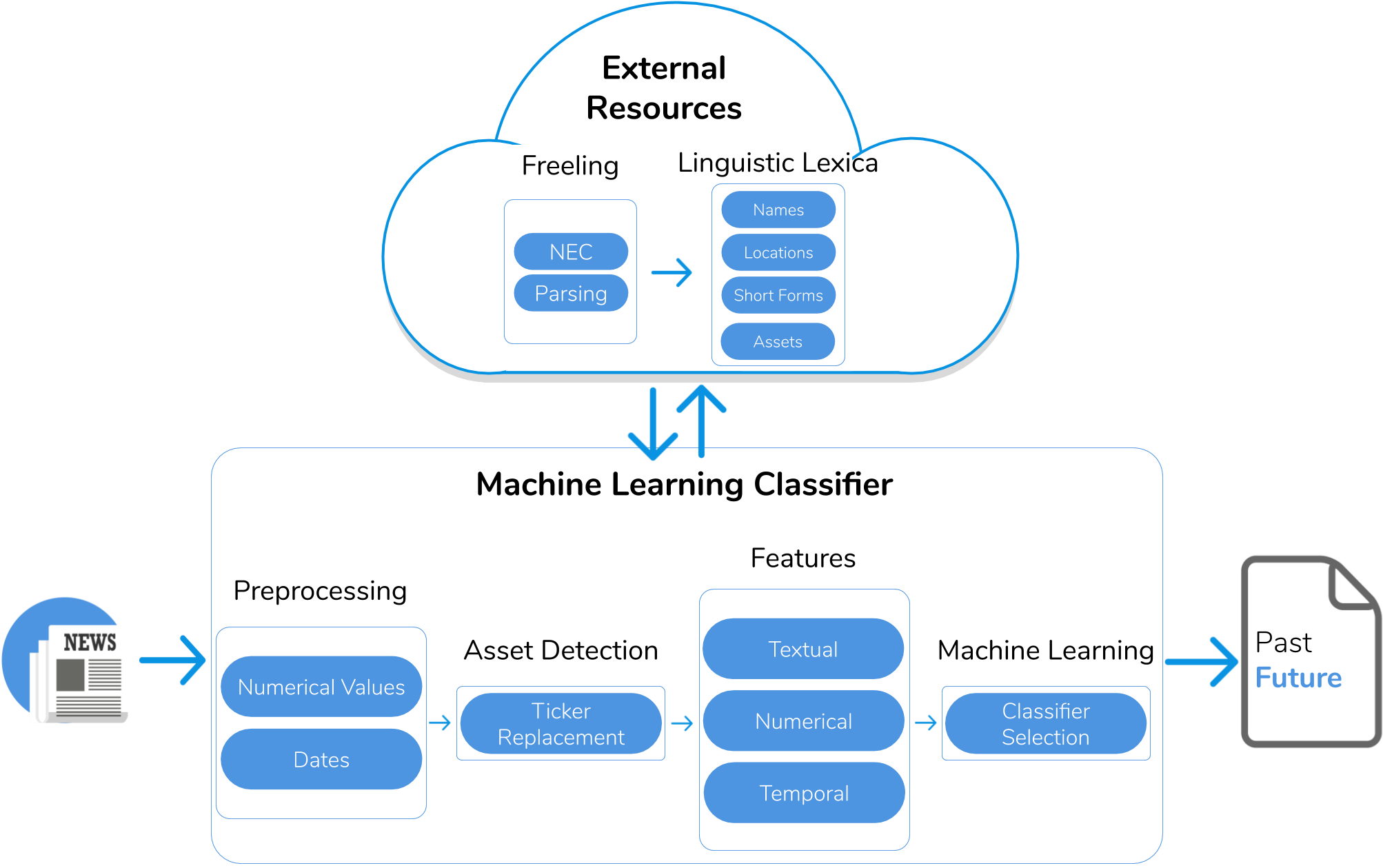
Finance-related news such as Bloomberg News, CNN Business and Forbes are valuable sources of real data for market screening systems. In news, an expert shares opinions beyond plain technical analyses that include context such as political, sociological and cultural factors. In the same text, the expert often discusses the performance of different assets. Some key statements are mere descriptions of past events while others are predictions. Therefore, understanding the temporality of the key statements in a text is essential to separate context information from valuable predictions. We propose a novel system to detect the temporality of finance-related news at discourse level that combines Natural Language Processing and Machine Learning techniques, and exploits sophisticated features such as syntactic and semantic dependencies. More specifically, we seek to extract the dominant tenses of the main statements, which may be either explicit or implicit. We have tested our system on a labelled dataset of finance-related news annotated by researchers with knowledge in the field. Experimental results reveal a high detection precision compared to an alternative rule-based baseline approach. Ultimately, this research contributes to the state-of-the-art of market screening by identifying predictive knowledge for financial decision making.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a system that uses natural language processing and machine learning techniques to detect temporality (references to time) in financial news articles.
- The goal is to better understand the temporal context of events and trends discussed in financial news, which can be valuable for financial analysis and decision-making.
- The system combines various natural language processing methods, such as named entity recognition and temporal expression extraction, along with machine learning models to classify the temporal nature of financial news articles.
Plain English Explanation
The researchers developed a system to analyze financial news articles and identify references to time and temporality. This is important because understanding the timing and context of events and trends discussed in financial news can provide valuable insights for investors, analysts, and decision-makers.
Imagine you're reading an article about a company's earnings report. The article might mention that the company's profits increased compared to the previous quarter or that the CEO announced a new initiative that will be implemented in the coming year. Being able to accurately identify and interpret these temporal references can help you better understand the significance of the information and make more informed decisions.
The researchers used a combination of natural language processing techniques and machine learning models to build their system. Natural language processing is a field of artificial intelligence that focuses on analyzing and understanding human language. In this case, the researchers used techniques like named entity recognition to identify references to time, such as dates, years, or time periods, within the financial news articles.
They then used machine learning models to classify the temporal nature of the articles, determining whether the content is discussing past, present, or future events and trends. This allows the system to provide a more nuanced understanding of the temporal context of the information presented in the financial news.
Technical Explanation
The researchers developed a system that combines natural language processing and machine learning to detect temporality in financial news articles. The system consists of three main components:
-
Named Entity Recognition: This component uses a pre-trained named entity recognition model to identify references to time, such as dates, years, and time periods, within the financial news articles.
-
Temporal Expression Extraction: Building on the named entity recognition, this component extracts and normalizes the temporal expressions identified in the articles, converting them into a standardized format (e.g., "2023-04-01" for April 1, 2023).
-
Temporal Classification: The final component uses a machine learning model, specifically a Bidirectional Encoder Representations from Transformers (BERT) model, to classify the temporal nature of the financial news articles. The model is trained to categorize the articles as discussing past, present, or future events and trends.
The researchers evaluated their system on a dataset of financial news articles, assessing its performance in correctly identifying and classifying the temporal references. The results demonstrate the effectiveness of this combined natural language processing and machine learning approach in understanding the temporal context of financial news.
Critical Analysis
The paper provides a thorough explanation of the researchers' system and the techniques used to detect temporality in financial news. The combination of natural language processing and machine learning appears to be a well-designed approach that can offer valuable insights into the timing and context of events and trends discussed in financial news.
One potential limitation of the research is the reliance on a specific dataset of financial news articles. While the dataset used in the study seems to be representative, it would be beneficial to evaluate the system's performance on a more diverse set of financial news sources to ensure its robustness and generalizability.
Additionally, the paper does not delve deeply into the potential biases or limitations of the machine learning models employed. It would be valuable to understand how the models handle ambiguous or context-dependent temporal references, as well as any challenges in accurately classifying the temporal nature of news articles.
Further research could explore the integration of this temporality detection system into real-world financial analysis and decision-making workflows. Investigating the practical applications and potential impact of this technology on the financial industry could provide valuable insights and drive future advancements in this area.
Conclusion
The researchers have developed a promising system that leverages natural language processing and machine learning to detect temporality in financial news articles. By accurately identifying and classifying the temporal references within financial news, this system can provide valuable insights that can inform financial analysis, decision-making, and risk management.
The combination of robust natural language processing techniques and advanced machine learning models demonstrates the potential of this approach to enhance our understanding of the temporal context of events and trends discussed in financial news. As the financial industry continues to grapple with the increasing volume and complexity of information, tools like this can play a crucial role in helping professionals navigate the financial landscape more effectively.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Automatic detection of relevant information, predictions and forecasts in financial news through topic modelling with Latent Dirichlet Allocation
Silvia Garc'ia-M'endez, Francisco de Arriba-P'erez, Ana Barros-Vila, Francisco J. Gonz'alez-Casta~no, Enrique Costa-Montenegro
0
0
Financial news items are unstructured sources of information that can be mined to extract knowledge for market screening applications. Manual extraction of relevant information from the continuous stream of finance-related news is cumbersome and beyond the skills of many investors, who, at most, can follow a few sources and authors. Accordingly, we focus on the analysis of financial news to identify relevant text and, within that text, forecasts and predictions. We propose a novel Natural Language Processing (NLP) system to assist investors in the detection of relevant financial events in unstructured textual sources by considering both relevance and temporality at the discursive level. Firstly, we segment the text to group together closely related text. Secondly, we apply co-reference resolution to discover internal dependencies within segments. Finally, we perform relevant topic modelling with Latent Dirichlet Allocation (LDA) to separate relevant from less relevant text and then analyse the relevant text using a Machine Learning-oriented temporal approach to identify predictions and speculative statements. We created an experimental data set composed of 2,158 financial news items that were manually labelled by NLP researchers to evaluate our solution. The ROUGE-L values for the identification of relevant text and predictions/forecasts were 0.662 and 0.982, respectively. To our knowledge, this is the first work to jointly consider relevance and temporality at the discursive level. It contributes to the transfer of human associative discourse capabilities to expert systems through the combination of multi-paragraph topic segmentation and co-reference resolution to separate author expression patterns, topic modelling with LDA to detect relevant text, and discursive temporality analysis to identify forecasts and predictions within this text.
4/3/2024
Future Language Modeling from Temporal Document History
Changmao Li, Jeffrey Flanigan
0
0
Predicting the future is of great interest across many aspects of human activity. Businesses are interested in future trends, traders are interested in future stock prices, and companies are highly interested in future technological breakthroughs. While there are many automated systems for predicting future numerical data, such as weather, stock prices, and demand for products, there is relatively little work in automatically predicting textual data. Humans are interested in textual data predictions because it is a natural format for our consumption, and experts routinely make predictions in a textual format (Christensen et al., 2004; Tetlock & Gardner, 2015; Frick, 2015). However, there has been relatively little formalization of this general problem in the machine learning or natural language processing communities. To address this gap, we introduce the task of future language modeling: probabilistic modeling of texts in the future based on a temporal history of texts. To our knowledge, our work is the first work to formalize the task of predicting the future in this way. We show that it is indeed possible to build future language models that improve upon strong non-temporal language model baselines, opening the door to working on this important, and widely applicable problem.
4/17/2024
New!Timeline-based Sentence Decomposition with In-Context Learning for Temporal Fact Extraction
Jianhao Chen, Haoyuan Ouyang, Junyang Ren, Wentao Ding, Wei Hu, Yuzhong Qu
0
0
Facts extraction is pivotal for constructing knowledge graphs. Recently, the increasing demand for temporal facts in downstream tasks has led to the emergence of the task of temporal fact extraction. In this paper, we specifically address the extraction of temporal facts from natural language text. Previous studies fail to handle the challenge of establishing time-to-fact correspondences in complex sentences. To overcome this hurdle, we propose a timeline-based sentence decomposition strategy using large language models (LLMs) with in-context learning, ensuring a fine-grained understanding of the timeline associated with various facts. In addition, we evaluate the performance of LLMs for direct temporal fact extraction and get unsatisfactory results. To this end, we introduce TSDRE, a method that incorporates the decomposition capabilities of LLMs into the traditional fine-tuning of smaller pre-trained language models (PLMs). To support the evaluation, we construct ComplexTRED, a complex temporal fact extraction dataset. Our experiments show that TSDRE achieves state-of-the-art results on both HyperRED-Temporal and ComplexTRED datasets.
5/17/2024
BERTopic-Driven Stock Market Predictions: Unraveling Sentiment Insights
Enmin Zhu, Jerome Yen
0
0
This paper explores the intersection of Natural Language Processing (NLP) and financial analysis, focusing on the impact of sentiment analysis in stock price prediction. We employ BERTopic, an advanced NLP technique, to analyze the sentiment of topics derived from stock market comments. Our methodology integrates this sentiment analysis with various deep learning models, renowned for their effectiveness in time series and stock prediction tasks. Through comprehensive experiments, we demonstrate that incorporating topic sentiment notably enhances the performance of these models. The results indicate that topics in stock market comments provide implicit, valuable insights into stock market volatility and price trends. This study contributes to the field by showcasing the potential of NLP in enriching financial analysis and opens up avenues for further research into real-time sentiment analysis and the exploration of emotional and contextual aspects of market sentiment. The integration of advanced NLP techniques like BERTopic with traditional financial analysis methods marks a step forward in developing more sophisticated tools for understanding and predicting market behaviors.
4/5/2024