Future Language Modeling from Temporal Document History
2404.10297
0
0
Abstract
Predicting the future is of great interest across many aspects of human activity. Businesses are interested in future trends, traders are interested in future stock prices, and companies are highly interested in future technological breakthroughs. While there are many automated systems for predicting future numerical data, such as weather, stock prices, and demand for products, there is relatively little work in automatically predicting textual data. Humans are interested in textual data predictions because it is a natural format for our consumption, and experts routinely make predictions in a textual format (Christensen et al., 2004; Tetlock & Gardner, 2015; Frick, 2015). However, there has been relatively little formalization of this general problem in the machine learning or natural language processing communities. To address this gap, we introduce the task of future language modeling: probabilistic modeling of texts in the future based on a temporal history of texts. To our knowledge, our work is the first work to formalize the task of predicting the future in this way. We show that it is indeed possible to build future language models that improve upon strong non-temporal language model baselines, opening the door to working on this important, and widely applicable problem.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This research paper explores the task of "Future Language Modeling from Temporal Document History," which aims to predict the future language of documents based on their past evolution.
- The authors propose a novel approach that leverages the temporal dynamics of document content to forecast future language.
- The research has implications for applications such as detection of temporality at the discourse level in financial news, predicting the future using language models, and automatic detection of relevant information for predictions and forecasts in financial data.
Plain English Explanation
The paper looks at how we can use the evolution of written documents over time to predict what those documents might say in the future. Imagine you have a collection of news articles or blog posts that have been published over several years. By analyzing how the language and content of these documents has changed and developed over time, the researchers believe they can forecast what future versions of these documents might look like.
This could be useful for all kinds of applications. For example, forecasting future technologies and advancements based on large datasets of scientific literature, or improving real-time pandemic forecasting using large language models. The key idea is that the past can reveal clues about the future, and this paper explores how we can leverage those clues to make predictions about forthcoming text.
Technical Explanation
The authors frame the "Future Language Modeling from Temporal Document History" task as predicting the future language of a document based on its past evolution. They propose a novel approach that models the temporal dynamics of document content, using this information to forecast future language.
The core of their method involves training a language model on a large corpus of documents, where each document is associated with a timestamp. This allows the model to learn patterns in how language evolves over time within individual documents. Then, when presented with a new document, the model can use these learned temporal patterns to predict what the document might say in the future.
The authors evaluate their approach on several benchmark datasets, demonstrating its effectiveness at forecasting future language compared to various baseline models. They analyze the model's performance across different document types and timescales, offering insights into the strengths and limitations of their technique.
Critical Analysis
The paper presents a compelling and technically sound approach to the task of future language modeling. By incorporating the temporal dimension of document evolution, the authors have developed a novel way to leverage historical data to make predictions about forthcoming text.
However, the authors do acknowledge several caveats and areas for further research. For instance, they note that their method may be more effective for certain types of documents, such as news articles or scientific papers, compared to more informal or personal writing. Additionally, the long-term forecasting capabilities of the model remain an open question, as the paper primarily evaluates short-term predictions.
Further research could explore ways to improve the model's robustness and generalization to a wider range of document genres and timescales. Incorporating additional contextual information, such as metadata or external events, may also help enhance the model's predictive power.
Conclusion
This research paper presents a promising approach to the task of "Future Language Modeling from Temporal Document History." By modeling the temporal dynamics of document content, the authors have developed a novel method for forecasting future language based on a document's past evolution.
The implications of this work span numerous applications, from detecting temporality in financial news to improving real-time pandemic forecasting. As language models continue to advance, the ability to predict future text based on historical patterns could unlock new possibilities in areas such as content generation, decision support, and strategic foresight.
While the paper highlights several promising directions, further research will be needed to fully realize the potential of this approach. Nonetheless, this work represents a significant step forward in our understanding of how the temporal dynamics of language can be leveraged to forecast the future.
Related Papers
Detection of Temporality at Discourse Level on Financial News by Combining Natural Language Processing and Machine Learning
Silvia Garc'ia-M'endez, Francisco de Arriba-P'erez, Ana Barros-Vila, Francisco J. Gonz'alez-Casta~no
0
0
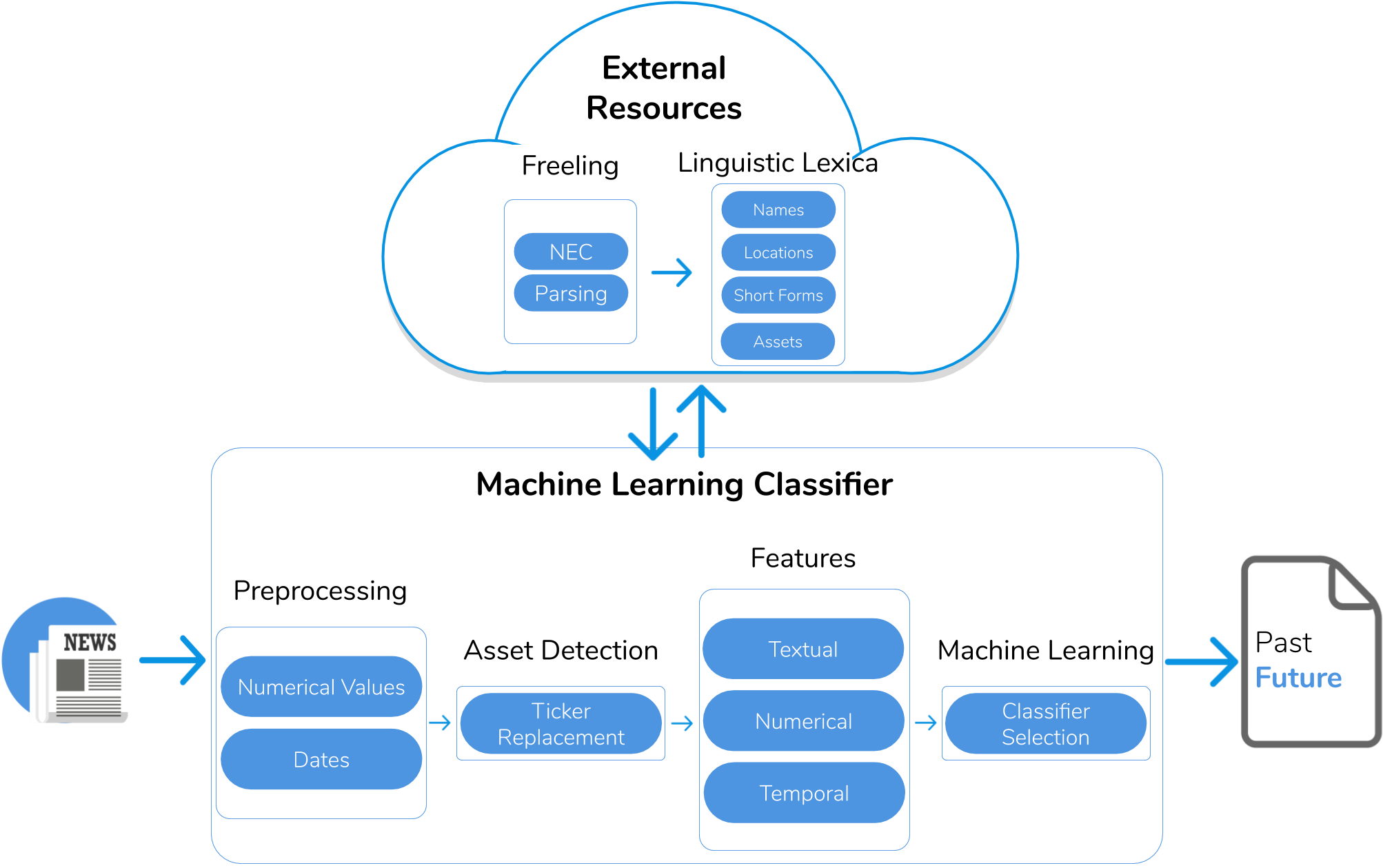
Finance-related news such as Bloomberg News, CNN Business and Forbes are valuable sources of real data for market screening systems. In news, an expert shares opinions beyond plain technical analyses that include context such as political, sociological and cultural factors. In the same text, the expert often discusses the performance of different assets. Some key statements are mere descriptions of past events while others are predictions. Therefore, understanding the temporality of the key statements in a text is essential to separate context information from valuable predictions. We propose a novel system to detect the temporality of finance-related news at discourse level that combines Natural Language Processing and Machine Learning techniques, and exploits sophisticated features such as syntactic and semantic dependencies. More specifically, we seek to extract the dominant tenses of the main statements, which may be either explicit or implicit. We have tested our system on a labelled dataset of finance-related news annotated by researchers with knowledge in the field. Experimental results reveal a high detection precision compared to an alternative rule-based baseline approach. Ultimately, this research contributes to the state-of-the-art of market screening by identifying predictive knowledge for financial decision making.
4/3/2024
Language Models Still Struggle to Zero-shot Reason about Time Series
Mike A. Merrill, Mingtian Tan, Vinayak Gupta, Tom Hartvigsen, Tim Althoff
0
0
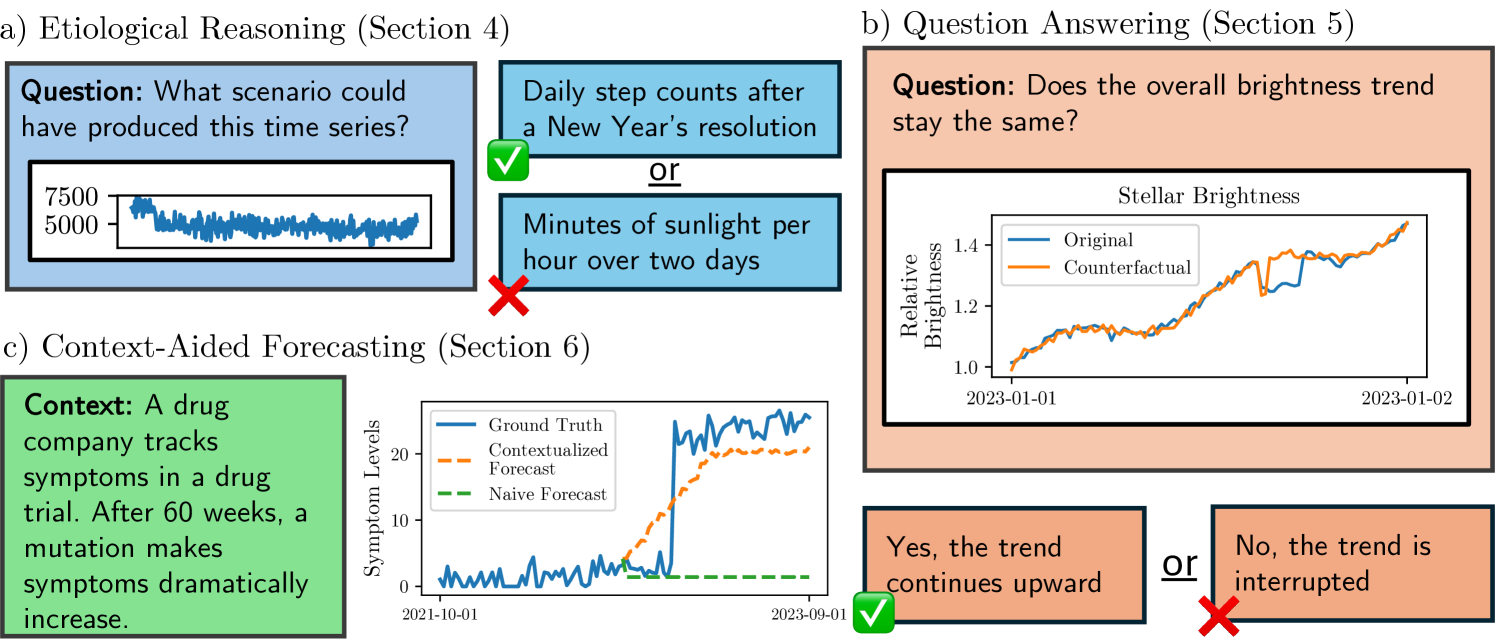
Time series are critical for decision-making in fields like finance and healthcare. Their importance has driven a recent influx of works passing time series into language models, leading to non-trivial forecasting on some datasets. But it remains unknown whether non-trivial forecasting implies that language models can reason about time series. To address this gap, we generate a first-of-its-kind evaluation framework for time series reasoning, including formal tasks and a corresponding dataset of multi-scale time series paired with text captions across ten domains. Using these data, we probe whether language models achieve three forms of reasoning: (1) Etiological Reasoning - given an input time series, can the language model identify the scenario that most likely created it? (2) Question Answering - can a language model answer factual questions about time series? (3) Context-Aided Forecasting - does highly relevant textual context improve a language model's time series forecasts? We find that otherwise highly-capable language models demonstrate surprisingly limited time series reasoning: they score marginally above random on etiological and question answering tasks (up to 30 percentage points worse than humans) and show modest success in using context to improve forecasting. These weakness showcase that time series reasoning is an impactful, yet deeply underdeveloped direction for language model research. We also make our datasets and code public at to support further research in this direction at https://github.com/behavioral-data/TSandLanguage
4/19/2024
ChatGPT Can Predict the Future when it Tells Stories Set in the Future About the Past
Van Pham, Scott Cunningham
0
0
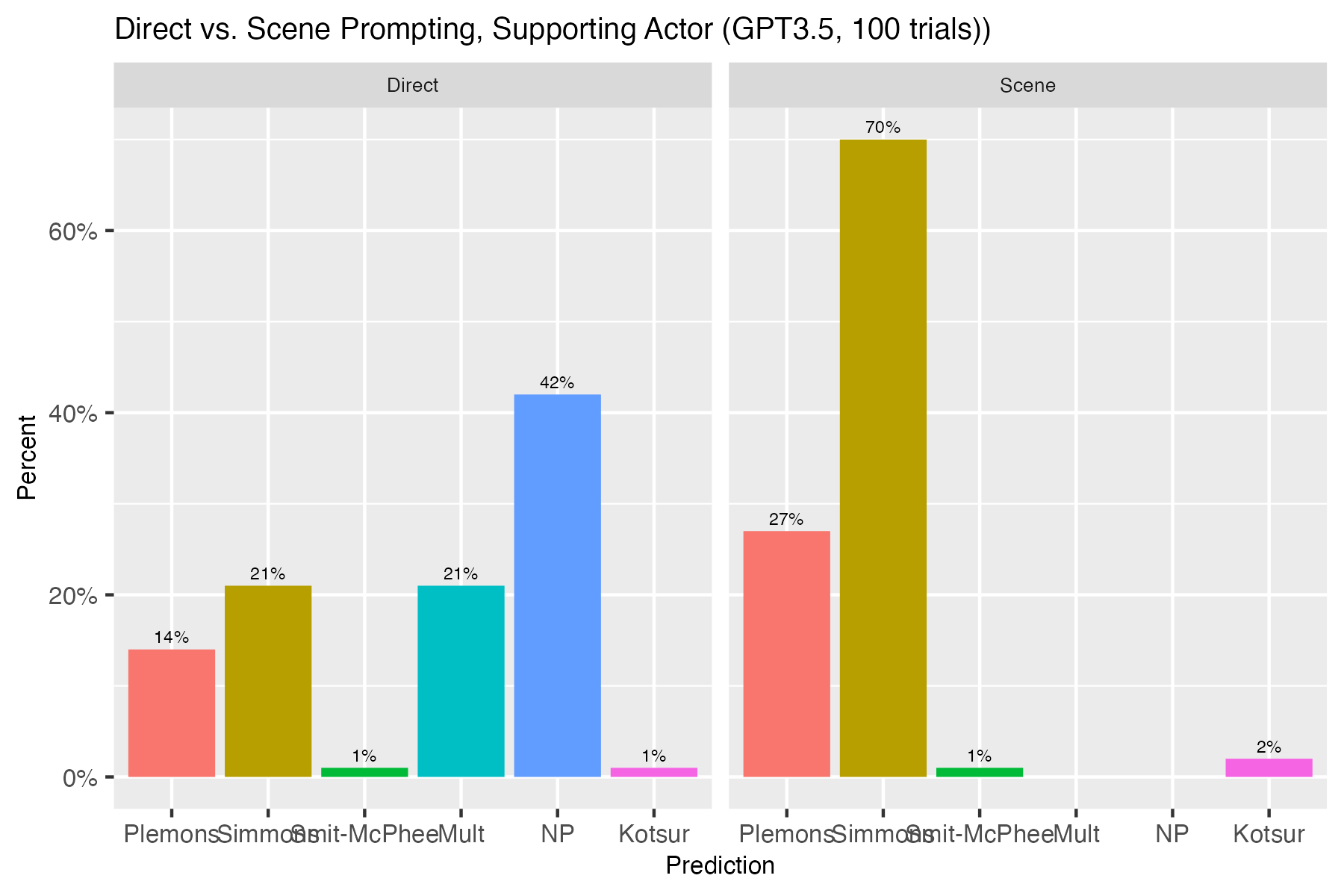
This study investigates whether OpenAI's ChatGPT-3.5 and ChatGPT-4 can accurately forecast future events using two distinct prompting strategies. To evaluate the accuracy of the predictions, we take advantage of the fact that the training data at the time of experiment stopped at September 2021, and ask about events that happened in 2022 using ChatGPT-3.5 and ChatGPT-4. We employed two prompting strategies: direct prediction and what we call future narratives which ask ChatGPT to tell fictional stories set in the future with characters that share events that have happened to them, but after ChatGPT's training data had been collected. Concentrating on events in 2022, we prompted ChatGPT to engage in storytelling, particularly within economic contexts. After analyzing 100 prompts, we discovered that future narrative prompts significantly enhanced ChatGPT-4's forecasting accuracy. This was especially evident in its predictions of major Academy Award winners as well as economic trends, the latter inferred from scenarios where the model impersonated public figures like the Federal Reserve Chair, Jerome Powell. These findings indicate that narrative prompts leverage the models' capacity for hallucinatory narrative construction, facilitating more effective data synthesis and extrapolation than straightforward predictions. Our research reveals new aspects of LLMs' predictive capabilities and suggests potential future applications in analytical contexts.
4/16/2024
🔎
Automatic detection of relevant information, predictions and forecasts in financial news through topic modelling with Latent Dirichlet Allocation
Silvia Garc'ia-M'endez, Francisco de Arriba-P'erez, Ana Barros-Vila, Francisco J. Gonz'alez-Casta~no, Enrique Costa-Montenegro
0
0
Financial news items are unstructured sources of information that can be mined to extract knowledge for market screening applications. Manual extraction of relevant information from the continuous stream of finance-related news is cumbersome and beyond the skills of many investors, who, at most, can follow a few sources and authors. Accordingly, we focus on the analysis of financial news to identify relevant text and, within that text, forecasts and predictions. We propose a novel Natural Language Processing (NLP) system to assist investors in the detection of relevant financial events in unstructured textual sources by considering both relevance and temporality at the discursive level. Firstly, we segment the text to group together closely related text. Secondly, we apply co-reference resolution to discover internal dependencies within segments. Finally, we perform relevant topic modelling with Latent Dirichlet Allocation (LDA) to separate relevant from less relevant text and then analyse the relevant text using a Machine Learning-oriented temporal approach to identify predictions and speculative statements. We created an experimental data set composed of 2,158 financial news items that were manually labelled by NLP researchers to evaluate our solution. The ROUGE-L values for the identification of relevant text and predictions/forecasts were 0.662 and 0.982, respectively. To our knowledge, this is the first work to jointly consider relevance and temporality at the discursive level. It contributes to the transfer of human associative discourse capabilities to expert systems through the combination of multi-paragraph topic segmentation and co-reference resolution to separate author expression patterns, topic modelling with LDA to detect relevant text, and discursive temporality analysis to identify forecasts and predictions within this text.
4/3/2024