A Deterministic Information Bottleneck Method for Clustering Mixed-Type Data

0

Sign in to get full access
Overview
- This paper presents a novel approach to noise filtering in information retrieval tasks.
- The authors propose an Information Bottleneck (IB) perspective to effective noise filtering, demonstrating its advantages over existing methods.
- Experiments on artificial data show the effectiveness of the IB-based approach in improving retrieval performance.
Plain English Explanation
The paper focuses on the problem of noise filtering in information retrieval systems. Information retrieval is the process of finding relevant information (e.g., documents, webpages) from a large collection of data in response to a user's query.
One of the key challenges in information retrieval is dealing with noise - irrelevant or misleading information that can negatively impact the quality of the retrieved results. The authors propose using the Information Bottleneck (IB) principle as a way to effectively filter out this noise.
The IB principle suggests that the most relevant information for a given task can be extracted by compressing the input data (in this case, the documents) while preserving as much information as possible about the target variable (the user's query). By applying this principle, the authors show that it is possible to improve the performance of information retrieval systems, allowing them to better identify the most relevant documents for a user's query while filtering out irrelevant noise.
Technical Explanation
The paper introduces an Information Bottleneck (IB) perspective to effective noise filtering in information retrieval tasks. The IB principle suggests that the most relevant information for a given task can be extracted by compressing the input data while preserving as much information as possible about the target variable.
The authors apply this principle to the problem of information retrieval, where the goal is to find the most relevant documents in response to a user's query. They propose an IB-based approach that aims to extract the most informative features from the documents while filtering out irrelevant noise.
To evaluate the effectiveness of their approach, the authors conduct simulations on artificial data. The results show that the IB-based method outperforms existing noise filtering techniques, leading to improved retrieval performance.
Critical Analysis
The paper presents a promising approach to noise filtering in information retrieval, but it is important to consider some potential limitations and areas for further research:
-
The experiments are conducted on artificial data, which may not fully capture the complexities of real-world information retrieval scenarios. Further testing on real-world datasets would be necessary to validate the effectiveness of the IB-based approach in practical applications.
-
The paper does not provide a detailed comparison of the IB-based method with other state-of-the-art noise filtering techniques. A more comprehensive evaluation could help establish the relative strengths and weaknesses of the proposed approach.
-
The theoretical underpinnings of the IB principle and its application to information retrieval could be further explored and explained in more depth to provide a stronger conceptual foundation for the proposed method.
-
The paper does not discuss potential limitations or edge cases of the IB-based approach, such as how it might perform in scenarios with highly complex or diverse types of noise. Acknowledging and addressing these potential issues could strengthen the overall presentation of the research.
Conclusion
This paper presents a novel Information Bottleneck (IB)-based approach to noise filtering in information retrieval tasks. The authors demonstrate the effectiveness of their method through simulations on artificial data, showing that it can outperform existing noise filtering techniques.
While the paper offers a promising solution to a critical problem in information retrieval, further research is needed to validate the approach on real-world datasets and explore its limitations and potential edge cases. Nonetheless, the IB-based perspective introduced in this work provides a compelling framework for effectively extracting relevant information from noisy data, with potential implications for a wide range of applications beyond information retrieval.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Deterministic Information Bottleneck Method for Clustering Mixed-Type Data
Efthymios Costa, Ioanna Papatsouma, Angelos Markos
In this paper, we present an information-theoretic method for clustering mixed-type data, that is, data consisting of both continuous and categorical variables. The method is a variant of the Deterministic Information Bottleneck algorithm which optimally compresses the data while retaining relevant information about the underlying structure. We compare the performance of the proposed method to that of three well-established clustering methods (KAMILA, K-Prototypes, and Partitioning Around Medoids with Gower's dissimilarity) on simulated and real-world datasets. The results demonstrate that the proposed approach represents a competitive alternative to conventional clustering techniques under specific conditions.
Read more7/8/2024
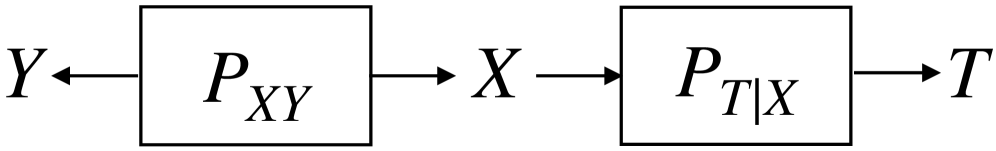
0
Statistically Valid Information Bottleneck via Multiple Hypothesis Testing
Amirmohammad Farzaneh, Osvaldo Simeone
The information bottleneck (IB) problem is a widely studied framework in machine learning for extracting compressed features that are informative for downstream tasks. However, current approaches to solving the IB problem rely on a heuristic tuning of hyperparameters, offering no guarantees that the learned features satisfy information-theoretic constraints. In this work, we introduce a statistically valid solution to this problem, referred to as IB via multiple hypothesis testing (IB-MHT), which ensures that the learned features meet the IB constraints with high probability, regardless of the size of the available dataset. The proposed methodology builds on Pareto testing and learn-then-test (LTT), and it wraps around existing IB solvers to provide statistical guarantees on the IB constraints. We demonstrate the performance of IB-MHT on classical and deterministic IB formulations, validating the effectiveness of IB-MHT in outperforming conventional methods in terms of statistical robustness and reliability.
Read more9/12/2024

0
An Information Bottleneck Perspective for Effective Noise Filtering on Retrieval-Augmented Generation
Kun Zhu, Xiaocheng Feng, Xiyuan Du, Yuxuan Gu, Weijiang Yu, Haotian Wang, Qianglong Chen, Zheng Chu, Jingchang Chen, Bing Qin
Retrieval-augmented generation integrates the capabilities of large language models with relevant information retrieved from an extensive corpus, yet encounters challenges when confronted with real-world noisy data. One recent solution is to train a filter module to find relevant content but only achieve suboptimal noise compression. In this paper, we propose to introduce the information bottleneck theory into retrieval-augmented generation. Our approach involves the filtration of noise by simultaneously maximizing the mutual information between compression and ground output, while minimizing the mutual information between compression and retrieved passage. In addition, we derive the formula of information bottleneck to facilitate its application in novel comprehensive evaluations, the selection of supervised fine-tuning data, and the construction of reinforcement learning rewards. Experimental results demonstrate that our approach achieves significant improvements across various question answering datasets, not only in terms of the correctness of answer generation but also in the conciseness with $2.5%$ compression rate.
Read more7/8/2024
🤿
0
Information Bottleneck Analysis of Deep Neural Networks via Lossy Compression
Ivan Butakov, Alexander Tolmachev, Sofia Malanchuk, Anna Neopryatnaya, Alexey Frolov, Kirill Andreev
The Information Bottleneck (IB) principle offers an information-theoretic framework for analyzing the training process of deep neural networks (DNNs). Its essence lies in tracking the dynamics of two mutual information (MI) values: between the hidden layer output and the DNN input/target. According to the hypothesis put forth by Shwartz-Ziv & Tishby (2017), the training process consists of two distinct phases: fitting and compression. The latter phase is believed to account for the good generalization performance exhibited by DNNs. Due to the challenging nature of estimating MI between high-dimensional random vectors, this hypothesis was only partially verified for NNs of tiny sizes or specific types, such as quantized NNs. In this paper, we introduce a framework for conducting IB analysis of general NNs. Our approach leverages the stochastic NN method proposed by Goldfeld et al. (2019) and incorporates a compression step to overcome the obstacles associated with high dimensionality. In other words, we estimate the MI between the compressed representations of high-dimensional random vectors. The proposed method is supported by both theoretical and practical justifications. Notably, we demonstrate the accuracy of our estimator through synthetic experiments featuring predefined MI values and comparison with MINE (Belghazi et al., 2018). Finally, we perform IB analysis on a close-to-real-scale convolutional DNN, which reveals new features of the MI dynamics.
Read more5/10/2024