DETRs Beat YOLOs on Real-time Object Detection
2304.08069
2
0
🔎
Abstract
The YOLO series has become the most popular framework for real-time object detection due to its reasonable trade-off between speed and accuracy. However, we observe that the speed and accuracy of YOLOs are negatively affected by the NMS. Recently, end-to-end Transformer-based detectors (DETRs) have provided an alternative to eliminating NMS. Nevertheless, the high computational cost limits their practicality and hinders them from fully exploiting the advantage of excluding NMS. In this paper, we propose the Real-Time DEtection TRansformer (RT-DETR), the first real-time end-to-end object detector to our best knowledge that addresses the above dilemma. We build RT-DETR in two steps, drawing on the advanced DETR: first we focus on maintaining accuracy while improving speed, followed by maintaining speed while improving accuracy. Specifically, we design an efficient hybrid encoder to expeditiously process multi-scale features by decoupling intra-scale interaction and cross-scale fusion to improve speed. Then, we propose the uncertainty-minimal query selection to provide high-quality initial queries to the decoder, thereby improving accuracy. In addition, RT-DETR supports flexible speed tuning by adjusting the number of decoder layers to adapt to various scenarios without retraining. Our RT-DETR-R50 / R101 achieves 53.1% / 54.3% AP on COCO and 108 / 74 FPS on T4 GPU, outperforming previously advanced YOLOs in both speed and accuracy. We also develop scaled RT-DETRs that outperform the lighter YOLO detectors (S and M models). Furthermore, RT-DETR-R50 outperforms DINO-R50 by 2.2% AP in accuracy and about 21 times in FPS. After pre-training with Objects365, RT-DETR-R50 / R101 achieves 55.3% / 56.2% AP. The project page: https://zhao-yian.github.io/RTDETR.
Create account to get full access
Overview
- The YOLO series has become a popular framework for real-time object detection, but its speed and accuracy are negatively affected by the non-maximum suppression (NMS) process.
- Transformer-based object detectors (DETRs) provide an alternative by eliminating the need for NMS, but their high computational cost limits their practicality.
- This paper introduces the Real-Time DEtection TRansformer (RT-DETR), which aims to address the speed-accuracy trade-off of existing object detectors.
Plain English Explanation
Object detection is the process of identifying and locating objects within an image or video. It's a crucial task in many applications, such as self-driving cars, security systems, and augmented reality. The YOLO (You Only Look Once) series has become a widely used framework for real-time object detection due to its ability to quickly process images and provide reasonably accurate results.
However, the YOLO framework has a limitation: its performance is negatively affected by the non-maximum suppression (NMS) process. NMS is a step used to remove duplicate detections of the same object, but it can also inadvertently remove some correct detections, leading to a trade-off between speed and accuracy.
Recently, researchers have developed a new type of object detector based on Transformers, called DETR (DEtection TRansformer). DETR eliminates the need for NMS, which could potentially improve both speed and accuracy. But the high computational cost of DETR has made it impractical for real-world applications.
In this paper, the researchers propose a new model called RT-DETR (Real-Time DEtection TRansformer) that aims to combine the advantages of YOLO and DETR. RT-DETR is designed to be both fast and accurate, making it suitable for real-time object detection tasks.
Technical Explanation
The researchers developed RT-DETR in two steps. First, they focused on maintaining accuracy while improving speed by designing an efficient hybrid encoder that separates intra-scale interaction and cross-scale fusion. This allows for faster processing of multi-scale features.
Next, they proposed an "uncertainty-minimal query selection" technique to provide high-quality initial queries to the decoder, which helps improve the overall accuracy of the model. RT-DETR also supports flexible speed tuning by adjusting the number of decoder layers, allowing it to adapt to different scenarios without retraining.
The researchers evaluated RT-DETR on the COCO dataset and found that their RT-DETR-R50 and RT-DETR-R101 models achieve 53.1% and 54.3% AP (average precision), respectively, while running at 108 FPS and 74 FPS on a T4 GPU. This outperforms previous state-of-the-art YOLO models in both speed and accuracy.
The researchers also developed scaled-down versions of RT-DETR that outperform the lighter YOLO models (S and M). Furthermore, RT-DETR-R50 outperforms the DINO-R50 model by 2.2% AP in accuracy and is about 21 times faster.
Critical Analysis
The researchers have made a significant contribution by addressing the speed-accuracy trade-off in object detection models. By combining the strengths of YOLO and DETR, they have created a real-time object detection model that is both fast and accurate.
However, the paper does not discuss potential limitations or areas for further research. For example, it would be interesting to understand how RT-DETR performs on different types of objects or in various environmental conditions. Additionally, the researchers could explore ways to further optimize the model's efficiency, such as by investigating the impact of different architectural choices or leveraging hardware-specific optimizations.
Another aspect that could be explored is the generalizability of RT-DETR. While the researchers show that it outperforms other models on the COCO dataset, it would be valuable to understand how it performs on other object detection benchmarks or in real-world applications.
Conclusion
The RT-DETR model proposed in this paper represents a significant advancement in real-time object detection. By addressing the limitations of existing frameworks, the researchers have created a model that can deliver high-speed and high-accuracy object detection, making it a promising solution for a wide range of applications. As the field of computer vision continues to evolve, models like RT-DETR could play a crucial role in enabling more robust and efficient object detection capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
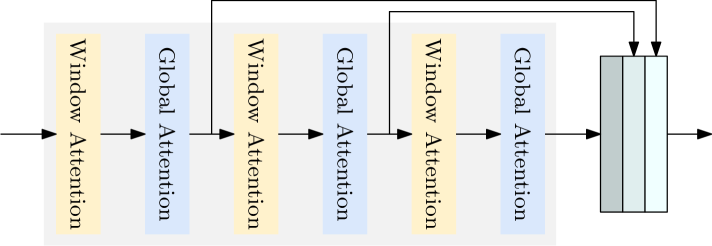
LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection
Qiang Chen, Xiangbo Su, Xinyu Zhang, Jian Wang, Jiahui Chen, Yunpeng Shen, Chuchu Han, Ziliang Chen, Weixiang Xu, Fanrong Li, Shan Zhang, Kun Yao, Errui Ding, Gang Zhang, Jingdong Wang
0
0
In this paper, we present a light-weight detection transformer, LW-DETR, which outperforms YOLOs for real-time object detection. The architecture is a simple stack of a ViT encoder, a projector, and a shallow DETR decoder. Our approach leverages recent advanced techniques, such as training-effective techniques, e.g., improved loss and pretraining, and interleaved window and global attentions for reducing the ViT encoder complexity. We improve the ViT encoder by aggregating multi-level feature maps, and the intermediate and final feature maps in the ViT encoder, forming richer feature maps, and introduce window-major feature map organization for improving the efficiency of interleaved attention computation. Experimental results demonstrate that the proposed approach is superior over existing real-time detectors, e.g., YOLO and its variants, on COCO and other benchmark datasets. Code and models are available at (https://github.com/Atten4Vis/LW-DETR).
6/6/2024
🔎
YOLOv10: Real-Time End-to-End Object Detection
Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han, Guiguang Ding
0
0
Over the past years, YOLOs have emerged as the predominant paradigm in the field of real-time object detection owing to their effective balance between computational cost and detection performance. Researchers have explored the architectural designs, optimization objectives, data augmentation strategies, and others for YOLOs, achieving notable progress. However, the reliance on the non-maximum suppression (NMS) for post-processing hampers the end-to-end deployment of YOLOs and adversely impacts the inference latency. Besides, the design of various components in YOLOs lacks the comprehensive and thorough inspection, resulting in noticeable computational redundancy and limiting the model's capability. It renders the suboptimal efficiency, along with considerable potential for performance improvements. In this work, we aim to further advance the performance-efficiency boundary of YOLOs from both the post-processing and model architecture. To this end, we first present the consistent dual assignments for NMS-free training of YOLOs, which brings competitive performance and low inference latency simultaneously. Moreover, we introduce the holistic efficiency-accuracy driven model design strategy for YOLOs. We comprehensively optimize various components of YOLOs from both efficiency and accuracy perspectives, which greatly reduces the computational overhead and enhances the capability. The outcome of our effort is a new generation of YOLO series for real-time end-to-end object detection, dubbed YOLOv10. Extensive experiments show that YOLOv10 achieves state-of-the-art performance and efficiency across various model scales. For example, our YOLOv10-S is 1.8$times$ faster than RT-DETR-R18 under the similar AP on COCO, meanwhile enjoying 2.8$times$ smaller number of parameters and FLOPs. Compared with YOLOv9-C, YOLOv10-B has 46% less latency and 25% fewer parameters for the same performance.
5/24/2024
🏷️
MO-YOLO: End-to-End Multiple-Object Tracking Method with YOLO and Decoder
Liao Pan, Yang Feng, Wu Di, Liu Bo, Zhang Xingle
0
0
Decoder-only models, such as GPT, have demonstrated superior performance in many areas compared to traditional encoder-decoder structure transformer models. Over the years, end-to-end models based on the traditional transformer structure, like MOTR, have achieved remarkable performance in multi-object tracking. However, the significant computational resource consumption of these models leads to less friendly inference speeds and training times. To address these issues, this paper attempts to construct a lightweight Decoder-only model: DecoderTracker for end-to-end multi-object tracking. Specifically, drawing on some real-time detection models, we have developed an image feature extraction network which can efficiently extract features from images to replace the encoder structure. In addition to minor innovations in the network, we analyze the potential reasons for the slow training of MOTR-like models and propose an effective training strategy to mitigate the issue of prolonged training times. On the DanceTrack dataset, without any bells and whistles, DecoderTracker's tracking performance slightly surpasses that of MOTR, with approximately twice the inference speed. Furthermore, DecoderTracker requires significantly less training time compared to MOTR.
5/27/2024
🔎
Replication Study and Benchmarking of Real-Time Object Detection Models
Pierre-Luc Asselin, Vincent Coulombe, William Guimont-Martin, William Larriv'ee-Hardy
0
0
This work examines the reproducibility and benchmarking of state-of-the-art real-time object detection models. As object detection models are often used in real-world contexts, such as robotics, where inference time is paramount, simply measuring models' accuracy is not enough to compare them. We thus compare a large variety of object detection models' accuracy and inference speed on multiple graphics cards. In addition to this large benchmarking attempt, we also reproduce the following models from scratch using PyTorch on the MS COCO 2017 dataset: DETR, RTMDet, ViTDet and YOLOv7. More importantly, we propose a unified training and evaluation pipeline, based on MMDetection's features, to better compare models. Our implementation of DETR and ViTDet could not achieve accuracy or speed performances comparable to what is declared in the original papers. On the other hand, reproduced RTMDet and YOLOv7 could match such performances. Studied papers are also found to be generally lacking for reproducibility purposes. As for MMDetection pretrained models, speed performances are severely reduced with limited computing resources (larger, more accurate models even more so). Moreover, results exhibit a strong trade-off between accuracy and speed, prevailed by anchor-free models - notably RTMDet or YOLOx models. The code used is this paper and all the experiments is available in the repository at https://github.com/Don767/segdet_mlcr2024.
5/14/2024