MO-YOLO: End-to-End Multiple-Object Tracking Method with YOLO and Decoder
2310.17170
0
0
🏷️
Abstract
Decoder-only models, such as GPT, have demonstrated superior performance in many areas compared to traditional encoder-decoder structure transformer models. Over the years, end-to-end models based on the traditional transformer structure, like MOTR, have achieved remarkable performance in multi-object tracking. However, the significant computational resource consumption of these models leads to less friendly inference speeds and training times. To address these issues, this paper attempts to construct a lightweight Decoder-only model: DecoderTracker for end-to-end multi-object tracking. Specifically, drawing on some real-time detection models, we have developed an image feature extraction network which can efficiently extract features from images to replace the encoder structure. In addition to minor innovations in the network, we analyze the potential reasons for the slow training of MOTR-like models and propose an effective training strategy to mitigate the issue of prolonged training times. On the DanceTrack dataset, without any bells and whistles, DecoderTracker's tracking performance slightly surpasses that of MOTR, with approximately twice the inference speed. Furthermore, DecoderTracker requires significantly less training time compared to MOTR.
Create account to get full access
Overview
- Researchers have developed a new multi-object tracking (MOT) model called MO-YOLO that is efficient and computationally lightweight.
- MO-YOLO combines principles from YOLO (You Only Look Once) and RT-DETR, using a decoder-only approach.
- The model achieves high speed, shorter training times, and strong MOT performance, surpassing the popular MOTR model on the Dancetrack dataset.
Plain English Explanation
Tracking multiple objects in a video is an important computer vision task known as multi-object tracking (MOT). Recent Transformer-based models like MOTR have shown impressive results on datasets like Dancetrack, but they require a lot of computing power to train and run.
The researchers behind MO-YOLO wanted to create an MOT model that was more efficient and easier to use. They drew inspiration from successful models like GPT and the YOLO object detection system.
MO-YOLO uses a "decoder-only" approach, taking the decoder from a model called RT-DETR and combining it with architectural components from the latest version of YOLO, called YOLOv8. This allows MO-YOLO to be fast, efficient, and capable of accurate multi-object tracking.
On the Dancetrack dataset, MO-YOLO not only matches the performance of the MOTR model, but actually outperforms it. MO-YOLO can process over 19 frames per second, more than twice as fast as MOTR's 9.5 FPS. The new model also requires less time and hardware to train compared to MOTR.
Technical Explanation
MO-YOLO builds on successful models like RT-DETR and YOLOv8. It uses a decoder-only architecture, taking the decoder from RT-DETR and integrating components from the YOLOv8 object detection system.
This hybrid approach allows MO-YOLO to achieve high speed and efficient performance on MOT tasks. By leveraging the decoder from RT-DETR and the architectural choices of YOLOv8, the model is able to surpass the popular MOTR Transformer-based model on the Dancetrack dataset.
On Dancetrack, MO-YOLO reaches over 19 frames per second (FPS), more than double the 9.5 FPS of MOTR. The new model also demonstrates significantly reduced training times and lower hardware requirements compared to MOTR.
Critical Analysis
The researchers highlight the computational and training efficiency of MO-YOLO as key advantages over prior Transformer-based MOT models like MOTR. This is an important consideration, as the resource demands of complex models can limit their practical deployment.
However, the paper does not provide a detailed analysis of the model's performance on other MOT benchmarks beyond Dancetrack. Further evaluation across a broader range of datasets would help assess the generalization of MO-YOLO's capabilities.
Additionally, the paper does not delve into potential failure modes or limitations of the approach. Exploring edge cases or scenarios where MO-YOLO may struggle could uncover opportunities for further refinement and improvement.
Conclusion
The MO-YOLO model presents a promising direction for efficient and high-performing end-to-end multi-object tracking. By blending principles from YOLO and RT-DETR, the researchers have created a computationally frugal model that matches or exceeds the accuracy of larger Transformer-based alternatives, while requiring less time and hardware to train and deploy.
This research introduces an intriguing paradigm for future MOT systems, highlighting the potential benefits of hybrid architectures that leverage the strengths of multiple successful approaches. As computer vision models continue to advance, a focus on efficiency and practicality alongside raw performance will be crucial for widespread adoption and real-world impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
DETRs Beat YOLOs on Real-time Object Detection
Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, Jie Chen
0
0
The YOLO series has become the most popular framework for real-time object detection due to its reasonable trade-off between speed and accuracy. However, we observe that the speed and accuracy of YOLOs are negatively affected by the NMS. Recently, end-to-end Transformer-based detectors (DETRs) have provided an alternative to eliminating NMS. Nevertheless, the high computational cost limits their practicality and hinders them from fully exploiting the advantage of excluding NMS. In this paper, we propose the Real-Time DEtection TRansformer (RT-DETR), the first real-time end-to-end object detector to our best knowledge that addresses the above dilemma. We build RT-DETR in two steps, drawing on the advanced DETR: first we focus on maintaining accuracy while improving speed, followed by maintaining speed while improving accuracy. Specifically, we design an efficient hybrid encoder to expeditiously process multi-scale features by decoupling intra-scale interaction and cross-scale fusion to improve speed. Then, we propose the uncertainty-minimal query selection to provide high-quality initial queries to the decoder, thereby improving accuracy. In addition, RT-DETR supports flexible speed tuning by adjusting the number of decoder layers to adapt to various scenarios without retraining. Our RT-DETR-R50 / R101 achieves 53.1% / 54.3% AP on COCO and 108 / 74 FPS on T4 GPU, outperforming previously advanced YOLOs in both speed and accuracy. We also develop scaled RT-DETRs that outperform the lighter YOLO detectors (S and M models). Furthermore, RT-DETR-R50 outperforms DINO-R50 by 2.2% AP in accuracy and about 21 times in FPS. After pre-training with Objects365, RT-DETR-R50 / R101 achieves 55.3% / 56.2% AP. The project page: https://zhao-yian.github.io/RTDETR.
4/4/2024
🔎
YOLOv10: Real-Time End-to-End Object Detection
Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han, Guiguang Ding
0
0
Over the past years, YOLOs have emerged as the predominant paradigm in the field of real-time object detection owing to their effective balance between computational cost and detection performance. Researchers have explored the architectural designs, optimization objectives, data augmentation strategies, and others for YOLOs, achieving notable progress. However, the reliance on the non-maximum suppression (NMS) for post-processing hampers the end-to-end deployment of YOLOs and adversely impacts the inference latency. Besides, the design of various components in YOLOs lacks the comprehensive and thorough inspection, resulting in noticeable computational redundancy and limiting the model's capability. It renders the suboptimal efficiency, along with considerable potential for performance improvements. In this work, we aim to further advance the performance-efficiency boundary of YOLOs from both the post-processing and model architecture. To this end, we first present the consistent dual assignments for NMS-free training of YOLOs, which brings competitive performance and low inference latency simultaneously. Moreover, we introduce the holistic efficiency-accuracy driven model design strategy for YOLOs. We comprehensively optimize various components of YOLOs from both efficiency and accuracy perspectives, which greatly reduces the computational overhead and enhances the capability. The outcome of our effort is a new generation of YOLO series for real-time end-to-end object detection, dubbed YOLOv10. Extensive experiments show that YOLOv10 achieves state-of-the-art performance and efficiency across various model scales. For example, our YOLOv10-S is 1.8$times$ faster than RT-DETR-R18 under the similar AP on COCO, meanwhile enjoying 2.8$times$ smaller number of parameters and FLOPs. Compared with YOLOv9-C, YOLOv10-B has 46% less latency and 25% fewer parameters for the same performance.
5/24/2024
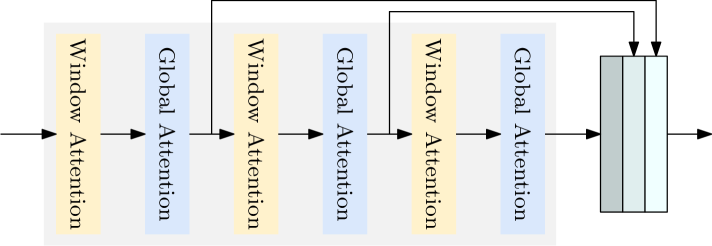
LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection
Qiang Chen, Xiangbo Su, Xinyu Zhang, Jian Wang, Jiahui Chen, Yunpeng Shen, Chuchu Han, Ziliang Chen, Weixiang Xu, Fanrong Li, Shan Zhang, Kun Yao, Errui Ding, Gang Zhang, Jingdong Wang
0
0
In this paper, we present a light-weight detection transformer, LW-DETR, which outperforms YOLOs for real-time object detection. The architecture is a simple stack of a ViT encoder, a projector, and a shallow DETR decoder. Our approach leverages recent advanced techniques, such as training-effective techniques, e.g., improved loss and pretraining, and interleaved window and global attentions for reducing the ViT encoder complexity. We improve the ViT encoder by aggregating multi-level feature maps, and the intermediate and final feature maps in the ViT encoder, forming richer feature maps, and introduce window-major feature map organization for improving the efficiency of interleaved attention computation. Experimental results demonstrate that the proposed approach is superior over existing real-time detectors, e.g., YOLO and its variants, on COCO and other benchmark datasets. Code and models are available at (https://github.com/Atten4Vis/LW-DETR).
6/6/2024

You Only Look at Once for Real-time and Generic Multi-Task
Jiayuan Wang, Q. M. Jonathan Wu, Ning Zhang
0
0
High precision, lightweight, and real-time responsiveness are three essential requirements for implementing autonomous driving. In this study, we incorporate A-YOLOM, an adaptive, real-time, and lightweight multi-task model designed to concurrently address object detection, drivable area segmentation, and lane line segmentation tasks. Specifically, we develop an end-to-end multi-task model with a unified and streamlined segmentation structure. We introduce a learnable parameter that adaptively concatenates features between necks and backbone in segmentation tasks, using the same loss function for all segmentation tasks. This eliminates the need for customizations and enhances the model's generalization capabilities. We also introduce a segmentation head composed only of a series of convolutional layers, which reduces the number of parameters and inference time. We achieve competitive results on the BDD100k dataset, particularly in visualization outcomes. The performance results show a mAP50 of 81.1% for object detection, a mIoU of 91.0% for drivable area segmentation, and an IoU of 28.8% for lane line segmentation. Additionally, we introduce real-world scenarios to evaluate our model's performance in a real scene, which significantly outperforms competitors. This demonstrates that our model not only exhibits competitive performance but is also more flexible and faster than existing multi-task models. The source codes and pre-trained models are released at https://github.com/JiayuanWang-JW/YOLOv8-multi-task
4/26/2024