LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection
2406.03459
0
0
Abstract
In this paper, we present a light-weight detection transformer, LW-DETR, which outperforms YOLOs for real-time object detection. The architecture is a simple stack of a ViT encoder, a projector, and a shallow DETR decoder. Our approach leverages recent advanced techniques, such as training-effective techniques, e.g., improved loss and pretraining, and interleaved window and global attentions for reducing the ViT encoder complexity. We improve the ViT encoder by aggregating multi-level feature maps, and the intermediate and final feature maps in the ViT encoder, forming richer feature maps, and introduce window-major feature map organization for improving the efficiency of interleaved attention computation. Experimental results demonstrate that the proposed approach is superior over existing real-time detectors, e.g., YOLO and its variants, on COCO and other benchmark datasets. Code and models are available at (https://github.com/Atten4Vis/LW-DETR).
Create account to get full access
Overview
- This paper introduces LW-DETR, a new object detection model that aims to outperform the popular YOLO (You Only Look Once) model in real-time detection tasks.
- LW-DETR is a transformer-based model that the authors claim can achieve comparable accuracy to YOLO while being significantly more efficient and faster.
- The key idea is to replace the computationally expensive components of YOLO with a more lightweight transformer-based architecture.
Plain English Explanation
LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection is a new object detection model that the authors believe can outperform the popular YOLO model, especially for real-time applications.
The key innovation is that LW-DETR uses a transformer-based architecture instead of the complex components in YOLO. Transformers are a type of machine learning model that can efficiently process and understand sequential data, like images. The authors argue that by using a transformer, they can achieve similar detection accuracy to YOLO but with much faster processing speeds, making it more suitable for real-time applications like self-driving cars or security cameras.
The paper demonstrates that LW-DETR can match the performance of YOLO on common object detection benchmarks while running significantly faster, especially on lower-power hardware like edge devices. This could make transformer-based models like LW-DETR more practical for deploying real-time object detection in a wider range of applications compared to the current state-of-the-art.
Technical Explanation
LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection proposes a new object detection model that aims to match the accuracy of YOLO while being significantly more efficient and faster, especially for real-time applications.
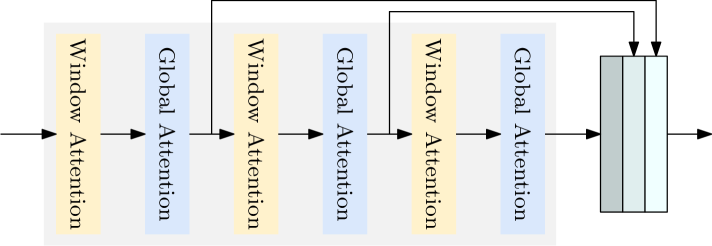
The key technical innovation is the use of a transformer-based architecture to replace the computationally expensive components of YOLO. Specifically, the authors design a lightweight transformer-based encoder-decoder that takes in an image and outputs object bounding boxes and class predictions.
The encoder uses a series of transformer layers to extract visual features from the input image. The decoder then uses another set of transformer layers to generate the final object detections. Crucially, the authors make several design choices to reduce the computational complexity of the transformer components, such as using a smaller number of layers and attention heads.
The authors evaluate LW-DETR on standard object detection benchmarks like COCO and find that it can match the accuracy of YOLO models, while running up to 4x faster on low-power hardware. They also demonstrate the model's effectiveness for real-time applications like vehicle and pedestrian detection on street scenes.
Critical Analysis
The paper makes a compelling case for LW-DETR as a viable alternative to YOLO for real-time object detection tasks. The authors' innovations in designing a lightweight transformer-based architecture appear to pay off in terms of improved efficiency without sacrificing accuracy.
However, the paper does not address some potential limitations or areas for further research. For example, it is unclear how LW-DETR would scale to detecting a larger number of object classes or handle more complex scenes. The authors also do not explore the model's robustness to noisy or occluded inputs, which is an important consideration for real-world deployment.
Additionally, while the paper compares LW-DETR to YOLO, it would be informative to see how it fares against other recent transformer-based object detection models, such as DQ-DETR or Decoder-Tracker, to better understand its relative strengths and weaknesses.
Overall, the LW-DETR model represents an interesting and promising direction for improving the efficiency of real-time object detection, but further research and evaluation would be needed to fully assess its capabilities and limitations.
Conclusion
LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection introduces a new transformer-based object detection model that aims to outperform the popular YOLO model, especially for real-time applications.
The key innovation is the use of a lightweight transformer architecture to replace the computationally expensive components of YOLO, allowing LW-DETR to achieve similar accuracy while running significantly faster, particularly on lower-power hardware. The authors demonstrate the model's effectiveness on standard object detection benchmarks as well as in real-world scenarios like vehicle and pedestrian detection.
If the performance and efficiency advantages of LW-DETR hold up in further research and real-world deployment, it could pave the way for more widespread adoption of transformer-based models for a variety of real-time computer vision applications, from autonomous driving to smart surveillance systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
DETRs Beat YOLOs on Real-time Object Detection
Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, Jie Chen
0
0
The YOLO series has become the most popular framework for real-time object detection due to its reasonable trade-off between speed and accuracy. However, we observe that the speed and accuracy of YOLOs are negatively affected by the NMS. Recently, end-to-end Transformer-based detectors (DETRs) have provided an alternative to eliminating NMS. Nevertheless, the high computational cost limits their practicality and hinders them from fully exploiting the advantage of excluding NMS. In this paper, we propose the Real-Time DEtection TRansformer (RT-DETR), the first real-time end-to-end object detector to our best knowledge that addresses the above dilemma. We build RT-DETR in two steps, drawing on the advanced DETR: first we focus on maintaining accuracy while improving speed, followed by maintaining speed while improving accuracy. Specifically, we design an efficient hybrid encoder to expeditiously process multi-scale features by decoupling intra-scale interaction and cross-scale fusion to improve speed. Then, we propose the uncertainty-minimal query selection to provide high-quality initial queries to the decoder, thereby improving accuracy. In addition, RT-DETR supports flexible speed tuning by adjusting the number of decoder layers to adapt to various scenarios without retraining. Our RT-DETR-R50 / R101 achieves 53.1% / 54.3% AP on COCO and 108 / 74 FPS on T4 GPU, outperforming previously advanced YOLOs in both speed and accuracy. We also develop scaled RT-DETRs that outperform the lighter YOLO detectors (S and M models). Furthermore, RT-DETR-R50 outperforms DINO-R50 by 2.2% AP in accuracy and about 21 times in FPS. After pre-training with Objects365, RT-DETR-R50 / R101 achieves 55.3% / 56.2% AP. The project page: https://zhao-yian.github.io/RTDETR.
4/4/2024
🔎
YOLOv10: Real-Time End-to-End Object Detection
Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han, Guiguang Ding
0
0
Over the past years, YOLOs have emerged as the predominant paradigm in the field of real-time object detection owing to their effective balance between computational cost and detection performance. Researchers have explored the architectural designs, optimization objectives, data augmentation strategies, and others for YOLOs, achieving notable progress. However, the reliance on the non-maximum suppression (NMS) for post-processing hampers the end-to-end deployment of YOLOs and adversely impacts the inference latency. Besides, the design of various components in YOLOs lacks the comprehensive and thorough inspection, resulting in noticeable computational redundancy and limiting the model's capability. It renders the suboptimal efficiency, along with considerable potential for performance improvements. In this work, we aim to further advance the performance-efficiency boundary of YOLOs from both the post-processing and model architecture. To this end, we first present the consistent dual assignments for NMS-free training of YOLOs, which brings competitive performance and low inference latency simultaneously. Moreover, we introduce the holistic efficiency-accuracy driven model design strategy for YOLOs. We comprehensively optimize various components of YOLOs from both efficiency and accuracy perspectives, which greatly reduces the computational overhead and enhances the capability. The outcome of our effort is a new generation of YOLO series for real-time end-to-end object detection, dubbed YOLOv10. Extensive experiments show that YOLOv10 achieves state-of-the-art performance and efficiency across various model scales. For example, our YOLOv10-S is 1.8$times$ faster than RT-DETR-R18 under the similar AP on COCO, meanwhile enjoying 2.8$times$ smaller number of parameters and FLOPs. Compared with YOLOv9-C, YOLOv10-B has 46% less latency and 25% fewer parameters for the same performance.
5/24/2024

DQ-DETR: DETR with Dynamic Query for Tiny Object Detection
Yi-Xin Huang, Hou-I Liu, Hong-Han Shuai, Wen-Huang Cheng
0
0
Despite previous DETR-like methods having performed successfully in generic object detection, tiny object detection is still a challenging task for them since the positional information of object queries is not customized for detecting tiny objects, whose scale is extraordinarily smaller than general objects. Also, DETR-like methods using a fixed number of queries make them unsuitable for aerial datasets, which only contain tiny objects, and the numbers of instances are imbalanced between different images. Thus, we present a simple yet effective model, named DQ-DETR, which consists of three different components: categorical counting module, counting-guided feature enhancement, and dynamic query selection to solve the above-mentioned problems. DQ-DETR uses the prediction and density maps from the categorical counting module to dynamically adjust the number of object queries and improve the positional information of queries. Our model DQ-DETR outperforms previous CNN-based and DETR-like methods, achieving state-of-the-art mAP 30.2% on the AI-TOD-V2 dataset, which mostly consists of tiny objects.
4/15/2024

Real-Time Detection and Analysis of Vehicles and Pedestrians using Deep Learning
Md Nahid Sadik, Tahmim Hossain, Faisal Sayeed
0
0
Computer vision, particularly vehicle and pedestrian identification is critical to the evolution of autonomous driving, artificial intelligence, and video surveillance. Current traffic monitoring systems confront major difficulty in recognizing small objects and pedestrians effectively in real-time, posing a serious risk to public safety and contributing to traffic inefficiency. Recognizing these difficulties, our project focuses on the creation and validation of an advanced deep-learning framework capable of processing complex visual input for precise, real-time recognition of cars and people in a variety of environmental situations. On a dataset representing complicated urban settings, we trained and evaluated different versions of the YOLOv8 and RT-DETR models. The YOLOv8 Large version proved to be the most effective, especially in pedestrian recognition, with great precision and robustness. The results, which include Mean Average Precision and recall rates, demonstrate the model's ability to dramatically improve traffic monitoring and safety. This study makes an important addition to real-time, reliable detection in computer vision, establishing new benchmarks for traffic management systems.
4/15/2024