Developing Healthcare Language Model Embedding Spaces
2403.19802
0
0
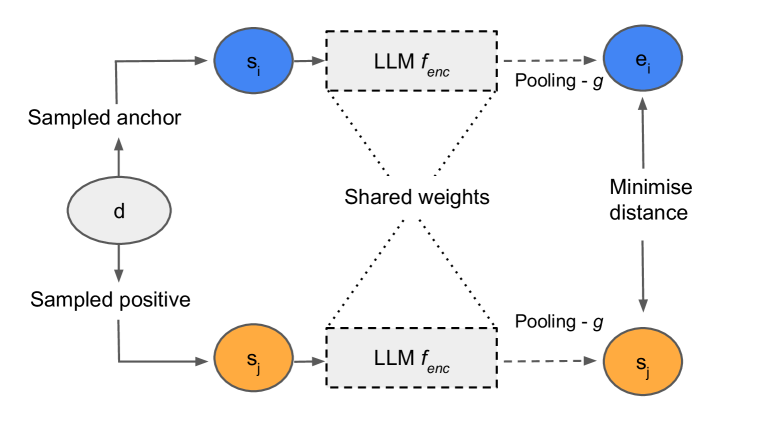
Abstract
Pre-trained Large Language Models (LLMs) often struggle on out-of-domain datasets like healthcare focused text. We explore specialized pre-training to adapt smaller LLMs to different healthcare datasets. Three methods are assessed: traditional masked language modeling, Deep Contrastive Learning for Unsupervised Textual Representations (DeCLUTR), and a novel pre-training objective utilizing metadata categories from the healthcare settings. These schemes are evaluated on downstream document classification tasks for each dataset, with additional analysis of the resultant embedding spaces. Contrastively trained models outperform other approaches on the classification tasks, delivering strong performance from limited labeled data and with fewer model parameter updates required. While metadata-based pre-training does not further improve classifications across the datasets, it yields interesting embedding cluster separability. All domain adapted LLMs outperform their publicly available general base LLM, validating the importance of domain-specialization. This research illustrates efficient approaches to instill healthcare competency in compact LLMs even under tight computational budgets, an essential capability for responsible and sustainable deployment in local healthcare settings. We provide pre-training guidelines for specialized healthcare LLMs, motivate continued inquiry into contrastive objectives, and demonstrates adaptation techniques to align small LLMs with privacy-sensitive medical tasks.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores developing language model embedding spaces for the healthcare domain.
- It focuses on document-level label-free embeddings, which can capture broader semantic relationships without relying on specific labels or annotations.
- The research examines the unique challenges and opportunities in the healthcare text domain compared to general language tasks.
Plain English Explanation
The paper investigates how to create effective language models for processing healthcare-related text data. Language models are AI systems that can understand and generate human language. Typically, these models are trained on broad internet data, which may not fully capture the specialized vocabulary and concepts in the healthcare field.
The researchers wanted to develop language models that can more accurately represent the meaning and relationships between healthcare-related words and documents. Rather than relying on predefined labels or annotations, they explored "label-free" embeddings. These embeddings aim to capture the inherent semantic structure of the healthcare text, without being limited to specific classification tasks.
The healthcare domain presents unique challenges compared to general language processing. Medical texts often contain highly technical terms, complex concepts, and specialized knowledge. Crafting language models that can properly handle this type of content is an important but difficult task.
By focusing on developing healthcare-tailored language model embeddings, the researchers hope to enable better natural language processing for a wide range of healthcare applications, such as clinical decision support, medical information retrieval, and automated text summarization.
Technical Explanation
The paper examines the challenges of building effective language model embedding spaces for the healthcare domain. The authors note that while large language models trained on general internet data have shown impressive performance, they may struggle to fully capture the nuances and specialized knowledge present in healthcare-related text.
To address this, the researchers explored document-level, label-free embeddings as an approach to develop more healthcare-specific language representations. Rather than relying on predefined labels or annotations, these embeddings aim to learn the inherent semantic structure of the healthcare corpus in an unsupervised manner.
The authors highlight several key differences between the healthcare text domain and general language tasks. Healthcare texts often contain highly technical terminology, complex medical concepts, and specialized domain knowledge. Accurately modeling these elements is crucial for enabling effective natural language processing applications in healthcare.
The paper outlines the potential benefits of healthcare-tailored language model embeddings, such as improved performance on clinical decision support, medical information retrieval, and automated text summarization tasks. By focusing on developing these specialized embeddings, the researchers hope to advance the state-of-the-art in healthcare natural language processing.
Critical Analysis
The paper provides a well-motivated and thoughtful exploration of the challenges in developing language model embedding spaces for the healthcare domain. The emphasis on document-level, label-free embeddings is a reasonable approach to capture the inherent semantic structure of healthcare text, without being limited by predefined classification tasks.
However, the paper does not delve into the specific techniques or architectures used to construct the healthcare-focused language models. While the high-level conceptual framework is outlined, more technical details on the model training process and architectural choices would be helpful for understanding the practical implementation.
Additionally, the paper does not present any empirical evaluation of the proposed approach. Quantitative results on relevant healthcare NLP tasks, as well as comparisons to baseline models, would strengthen the claims about the potential benefits of the healthcare language model embeddings.
Further research could also explore the limitations and potential biases of the developed embeddings. Healthcare data can often reflect societal biases and inequities, which could be inadvertently encoded in the language models. Assessing and mitigating such biases should be a key consideration.
Conclusion
This paper sets forth a compelling vision for developing language model embedding spaces tailored to the healthcare domain. By focusing on document-level, label-free embeddings, the researchers aim to capture the inherent semantic structure of healthcare text, which could enable more effective natural language processing applications in the medical field.
The unique challenges and opportunities presented by the healthcare text domain are well-articulated, highlighting the importance of this research area. While the technical details and empirical evaluation are not fully fleshed out in the current work, the overall approach and potential benefits are promising.
Continued advancements in healthcare-focused language models have the potential to significantly impact a wide range of medical applications, from clinical decision support to automated medical record processing. As the field of healthcare NLP continues to evolve, this research represents an important step towards more specialized and effective language representations for the healthcare domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
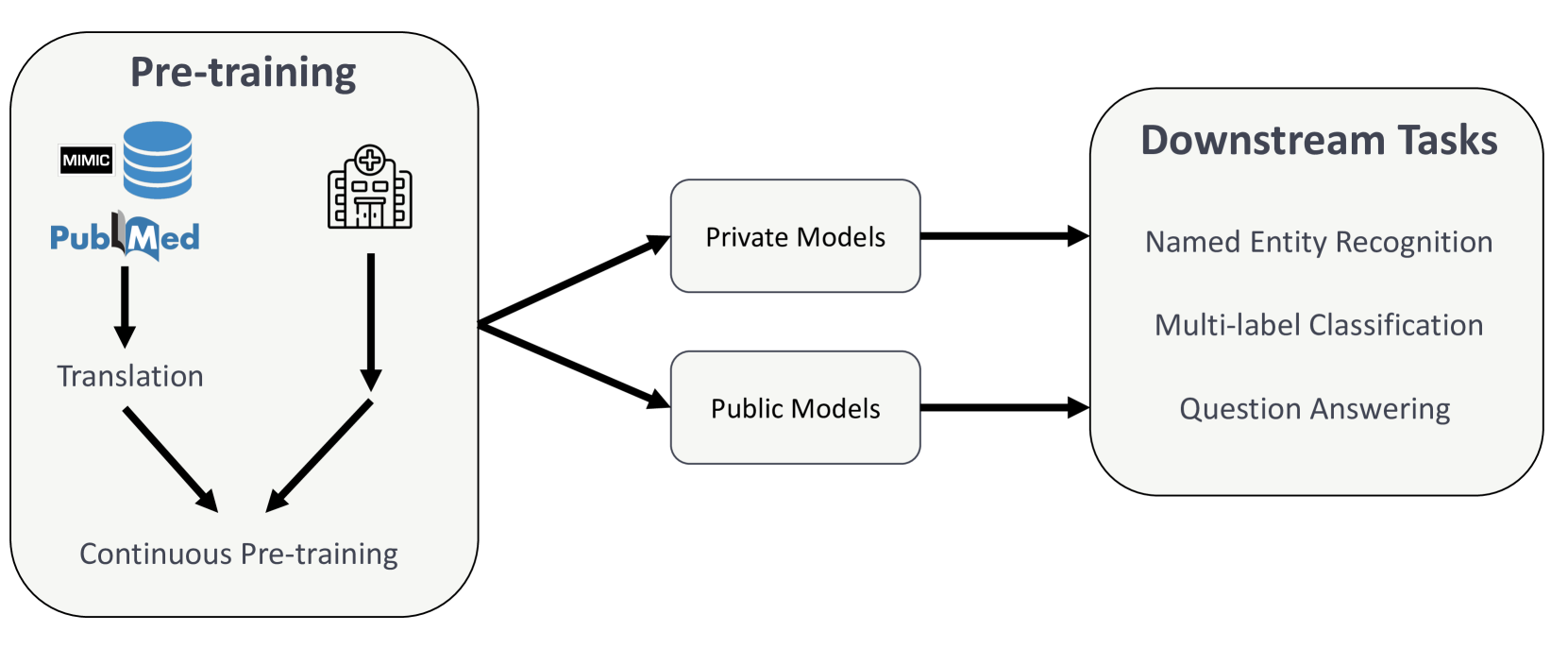
Comprehensive Study on German Language Models for Clinical and Biomedical Text Understanding
Ahmad Idrissi-Yaghir, Amin Dada, Henning Schafer, Kamyar Arzideh, Giulia Baldini, Jan Trienes, Max Hasin, Jeanette Bewersdorff, Cynthia S. Schmidt, Marie Bauer, Kaleb E. Smith, Jiang Bian, Yonghui Wu, Jorg Schlotterer, Torsten Zesch, Peter A. Horn, Christin Seifert, Felix Nensa, Jens Kleesiek, Christoph M. Friedrich
0
0
Recent advances in natural language processing (NLP) can be largely attributed to the advent of pre-trained language models such as BERT and RoBERTa. While these models demonstrate remarkable performance on general datasets, they can struggle in specialized domains such as medicine, where unique domain-specific terminologies, domain-specific abbreviations, and varying document structures are common. This paper explores strategies for adapting these models to domain-specific requirements, primarily through continuous pre-training on domain-specific data. We pre-trained several German medical language models on 2.4B tokens derived from translated public English medical data and 3B tokens of German clinical data. The resulting models were evaluated on various German downstream tasks, including named entity recognition (NER), multi-label classification, and extractive question answering. Our results suggest that models augmented by clinical and translation-based pre-training typically outperform general domain models in medical contexts. We conclude that continuous pre-training has demonstrated the ability to match or even exceed the performance of clinical models trained from scratch. Furthermore, pre-training on clinical data or leveraging translated texts have proven to be reliable methods for domain adaptation in medical NLP tasks.
5/9/2024
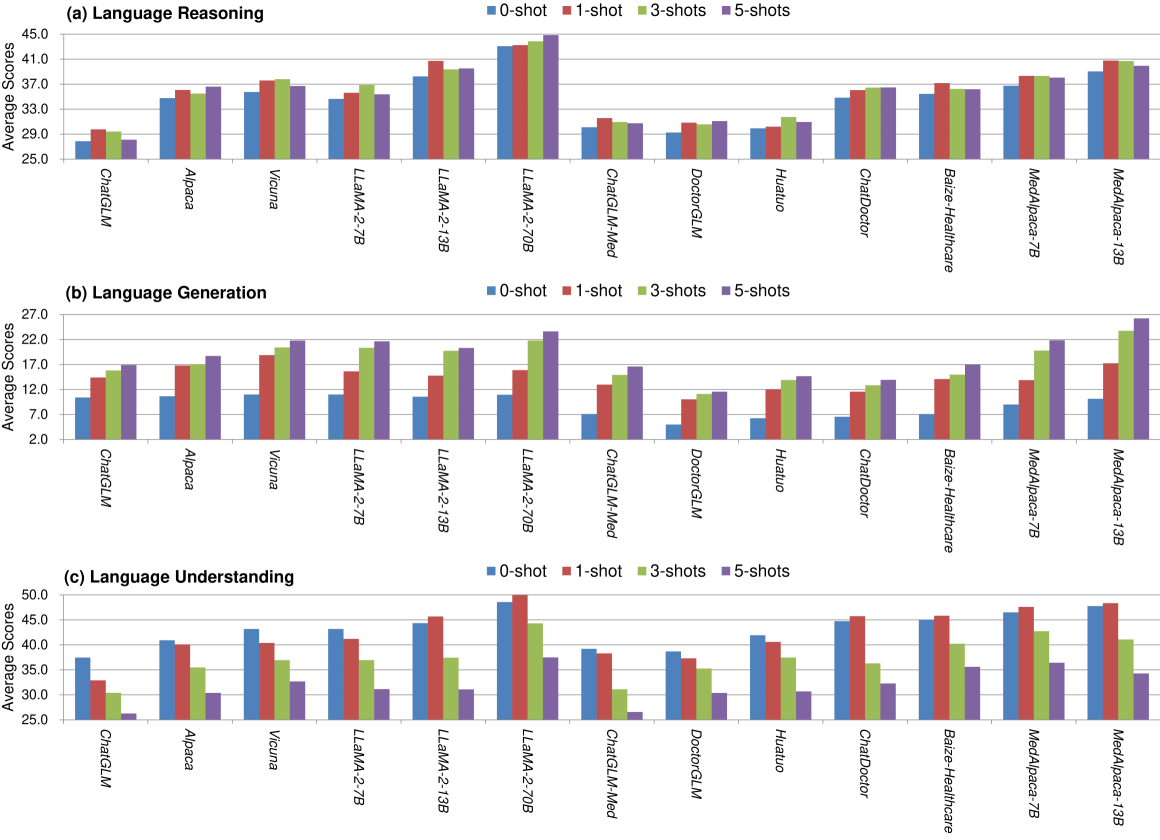
Large Language Models in Healthcare: A Comprehensive Benchmark
Andrew Liu, Hongjian Zhou, Yining Hua, Omid Rohanian, Lei Clifton, David A. Clifton
0
0
The adoption of large language models (LLMs) to assist clinicians has attracted remarkable attention. Existing works mainly adopt the close-ended question-answering task with answer options for evaluation. However, in real clinical settings, many clinical decisions, such as treatment recommendations, involve answering open-ended questions without pre-set options. Meanwhile, existing studies mainly use accuracy to assess model performance. In this paper, we comprehensively benchmark diverse LLMs in healthcare, to clearly understand their strengths and weaknesses. Our benchmark contains seven tasks and thirteen datasets across medical language generation, understanding, and reasoning. We conduct a detailed evaluation of the existing sixteen LLMs in healthcare under both zero-shot and few-shot (i.e., 1,3,5-shot) learning settings. We report the results on five metrics (i.e. matching, faithfulness, comprehensiveness, generalizability, and robustness) that are critical in achieving trust from clinical users. We further invite medical experts to conduct human evaluation.
5/3/2024
📈
XAI4LLM. Let Machine Learning Models and LLMs Collaborate for Enhanced In-Context Learning in Healthcare
Fatemeh Nazary, Yashar Deldjoo, Tommaso Di Noia, Eugenio di Sciascio
0
0
The integration of Large Language Models (LLMs) into healthcare diagnostics offers a promising avenue for clinical decision-making. This study outlines the development of a novel method for zero-shot/few-shot in-context learning (ICL) by integrating medical domain knowledge using a multi-layered structured prompt. We also explore the efficacy of two communication styles between the user and LLMs: the Numerical Conversational (NC) style, which processes data incrementally, and the Natural Language Single-Turn (NL-ST) style, which employs long narrative prompts. Our study systematically evaluates the diagnostic accuracy and risk factors, including gender bias and false negative rates, using a dataset of 920 patient records in various few-shot scenarios. Results indicate that traditional clinical machine learning (ML) models generally outperform LLMs in zero-shot and few-shot settings. However, the performance gap narrows significantly when employing few-shot examples alongside effective explainable AI (XAI) methods as sources of domain knowledge. Moreover, with sufficient time and an increased number of examples, the conversational style (NC) nearly matches the performance of ML models. Most notably, LLMs demonstrate comparable or superior cost-sensitive accuracy relative to ML models. This research confirms that, with appropriate domain knowledge and tailored communication strategies, LLMs can significantly enhance diagnostic processes. The findings highlight the importance of optimizing the number of training examples and communication styles to improve accuracy and reduce biases in LLM applications.
5/16/2024
🌀
Bias patterns in the application of LLMs for clinical decision support: A comprehensive study
Raphael Poulain, Hamed Fayyaz, Rahmatollah Beheshti
0
0
Large Language Models (LLMs) have emerged as powerful candidates to inform clinical decision-making processes. While these models play an increasingly prominent role in shaping the digital landscape, two growing concerns emerge in healthcare applications: 1) to what extent do LLMs exhibit social bias based on patients' protected attributes (like race), and 2) how do design choices (like architecture design and prompting strategies) influence the observed biases? To answer these questions rigorously, we evaluated eight popular LLMs across three question-answering (QA) datasets using clinical vignettes (patient descriptions) standardized for bias evaluations. We employ red-teaming strategies to analyze how demographics affect LLM outputs, comparing both general-purpose and clinically-trained models. Our extensive experiments reveal various disparities (some significant) across protected groups. We also observe several counter-intuitive patterns such as larger models not being necessarily less biased and fined-tuned models on medical data not being necessarily better than the general-purpose models. Furthermore, our study demonstrates the impact of prompt design on bias patterns and shows that specific phrasing can influence bias patterns and reflection-type approaches (like Chain of Thought) can reduce biased outcomes effectively. Consistent with prior studies, we call on additional evaluations, scrutiny, and enhancement of LLMs used in clinical decision support applications.
4/24/2024