Development and bilingual evaluation of Japanese medical large language model within reasonably low computational resources

0
💬
Sign in to get full access
Overview
- Developed and evaluated a large language model for Japanese medical text within limited computational resources
- Assessed the model's performance on various medical tasks, including question answering and text generation
- Compared the model's abilities to a bilingual model trained on both Japanese and English medical data
Plain English Explanation
This research paper describes the development and evaluation of a large language model specifically designed for processing Japanese medical text. Large language models are powerful AI systems that can understand and generate human-like text, and they have become increasingly important in various applications, including healthcare.
The researchers created a large language model for the Japanese medical domain, which means they trained the model on a vast amount of Japanese medical literature and information. This allowed the model to gain a deep understanding of medical terminology, concepts, and the unique writing style used in the Japanese medical field.
To test the model's capabilities, the researchers evaluated it on several medical tasks, such as answering questions about medical information and generating relevant text. They compared the model's performance to a bilingual model that was trained on both Japanese and English medical data.
The key finding was that the Japanese medical language model outperformed the bilingual model on tasks specific to the Japanese medical domain, demonstrating the importance of developing specialized language models for different languages and domains. This research shows how advanced language models can be tailored to specific needs, like the unique requirements of the Japanese medical field, even with limited computational resources.
Technical Explanation
The researchers developed a large language model for the Japanese medical domain using a technique called "Masked Language Modeling" (MLM). This involved training the model on a large corpus of Japanese medical text, which allowed it to learn the nuances of medical terminology and writing style in the Japanese language.
To evaluate the model's performance, the researchers assessed it on several medical tasks, including question answering and text generation. They compared the Japanese medical language model to a bilingual model that was trained on both Japanese and English medical data.
The results showed that the Japanese medical language model outperformed the bilingual model on tasks specific to the Japanese medical domain, such as answering questions about Japanese medical information. This suggests that specialized language models tailored to individual languages and domains can be more effective than more general, multilingual models, even when the computational resources are limited.
The researchers also discussed some limitations of their work, such as the need for further evaluation on a wider range of medical tasks and the potential for bias in the training data. They highlighted the need for continued research in this area to further improve the capabilities of medical language models, particularly in non-English languages.
Critical Analysis
The researchers' approach of developing a specialized language model for the Japanese medical domain is a promising step towards improving the performance of AI systems in healthcare applications. By focusing on a specific language and domain, the researchers were able to create a model that outperformed a more general, bilingual model on relevant tasks.
However, the researchers acknowledged several limitations of their work, such as the need for further evaluation on a broader range of medical tasks and the potential for bias in the training data. These are important considerations that should be addressed in future research.
Additionally, while the researchers demonstrated the effectiveness of their Japanese medical language model, it would be valuable to understand how it compares to other specialized language models, such as those developed for other languages or medical domains. A more comprehensive comparison could provide additional insights into the best approaches for developing effective medical language models.
Overall, this research represents an important step forward in the development of tailored language models for healthcare applications, particularly in non-English languages. The findings suggest that continued investment in specialized language models could lead to significant improvements in the performance of AI systems in the medical field.
Conclusion
This research paper presents the development and evaluation of a large language model specifically designed for processing Japanese medical text. The key findings show that this specialized model outperformed a bilingual model on tasks relevant to the Japanese medical domain, highlighting the importance of tailoring language models to individual languages and domains.
The researchers' approach demonstrates the potential for advanced language models to be adapted to the unique requirements of different healthcare applications, even with limited computational resources. As the use of AI in healthcare continues to grow, this work suggests that developing specialized language models could be a valuable strategy for improving the performance and effectiveness of these systems, particularly in non-English languages.
While the researchers identified some limitations in their work, this research represents an important contribution to the ongoing efforts to leverage the power of large language models in the medical field. By continuing to explore and refine specialized language models, researchers and practitioners may be able to unlock new possibilities for AI-powered healthcare solutions that are tailored to the needs of diverse patient populations and medical domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Development and bilingual evaluation of Japanese medical large language model within reasonably low computational resources
Issey Sukeda
The recent success of large language models (LLMs) and the scaling law has led to a widespread adoption of larger models. Particularly in the healthcare industry, there is an increasing demand for locally operated LLMs due to security concerns. However, the majority of high quality open-source LLMs have a size of 70B parameters, imposing significant financial burdens on users for GPU preparation and operation. To overcome these issues, we present a medical adaptation based on the recent 7B models, which enables the operation in low computational resources. We compare the performance on medical question-answering benchmarks in two languages (Japanese and English), demonstrating that its scores reach parity with or surpass those of currently existing medical LLMs that are ten times larger. We find that fine-tuning an English-centric base model on Japanese medical dataset improves the score in both language, supporting the effect of cross-lingual knowledge transfer. We hope that this study will alleviate financial challenges, serving as a stepping stone for clinical institutions to practically utilize LLMs locally. Our evaluation code is available at https://github.com/stardust-coder/japanese-lm-med-harness.
Read more9/23/2024
0
70B-parameter large language models in Japanese medical question-answering
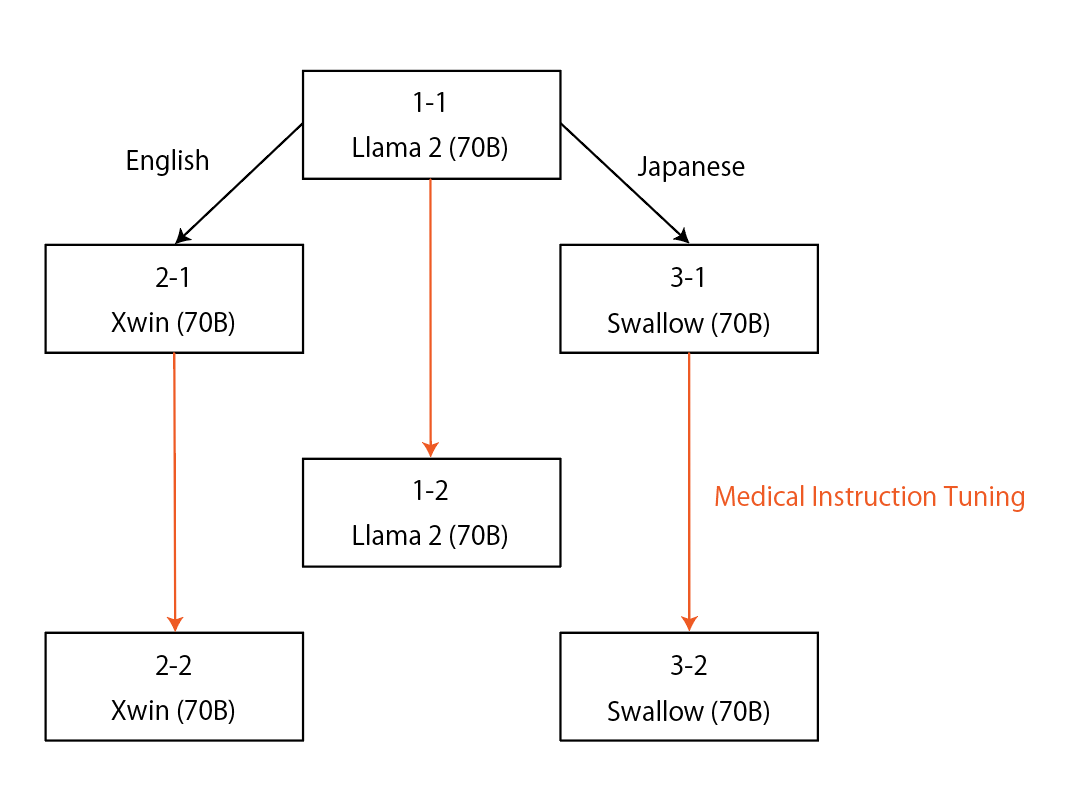
Issey Sukeda, Risa Kishikawa, Satoshi Kodera
Since the rise of large language models (LLMs), the domain adaptation has been one of the hot topics in various domains. Many medical LLMs trained with English medical dataset have made public recently. However, Japanese LLMs in medical domain still lack its research. Here we utilize multiple 70B-parameter LLMs for the first time and show that instruction tuning using Japanese medical question-answering dataset significantly improves the ability of Japanese LLMs to solve Japanese medical license exams, surpassing 50% in accuracy. In particular, the Japanese-centric models exhibit a more significant leap in improvement through instruction tuning compared to their English-centric counterparts. This underscores the importance of continual pretraining and the adjustment of the tokenizer in our local language. We also examine two slightly different prompt formats, resulting in non-negligible performance improvement.
Read more6/24/2024
0
JMedBench: A Benchmark for Evaluating Japanese Biomedical Large Language Models
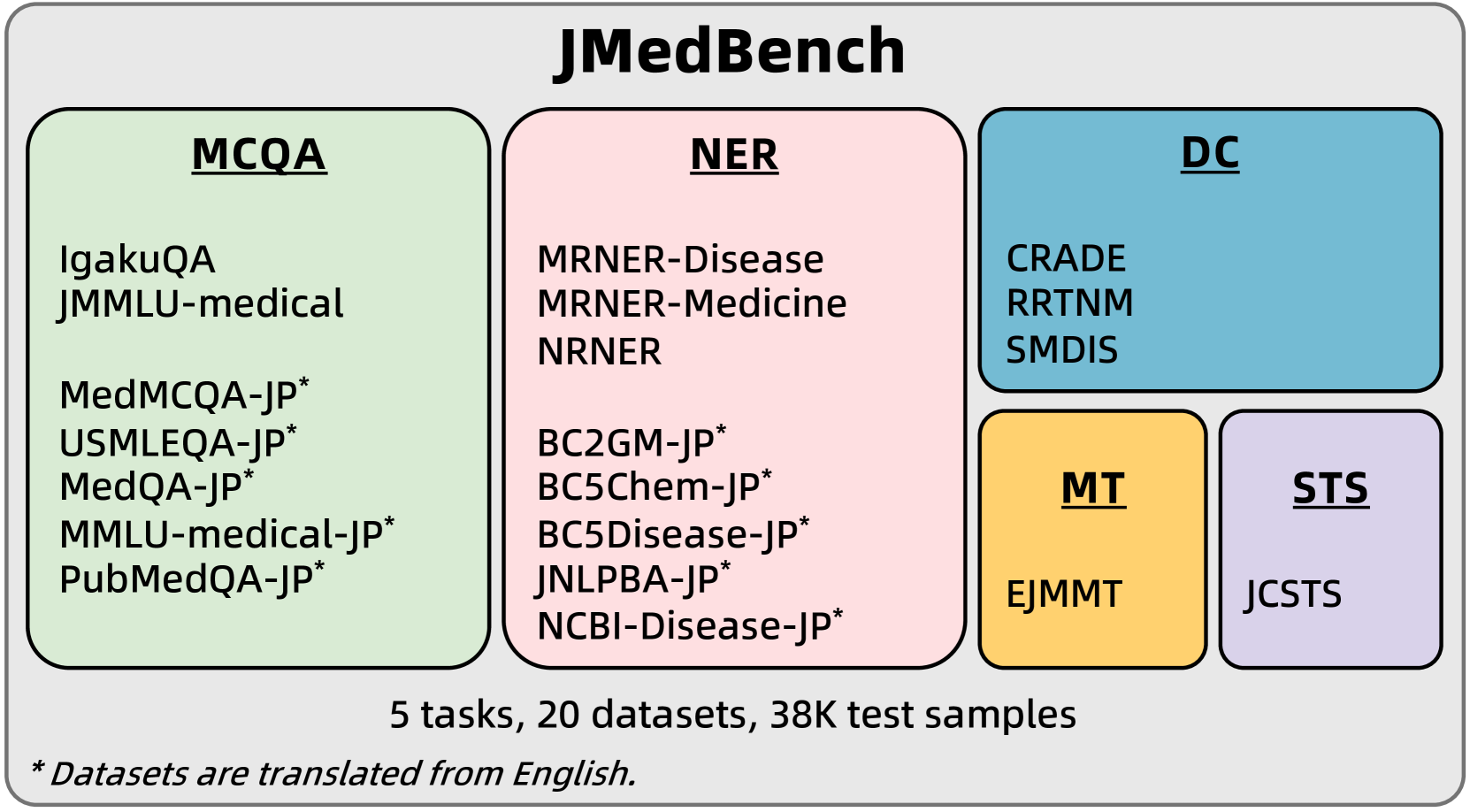
Junfeng Jiang, Jiahao Huang, Akiko Aizawa
Recent developments in Japanese large language models (LLMs) primarily focus on general domains, with fewer advancements in Japanese biomedical LLMs. One obstacle is the absence of a comprehensive, large-scale benchmark for comparison. Furthermore, the resources for evaluating Japanese biomedical LLMs are insufficient. To advance this field, we propose a new benchmark including eight LLMs across four categories and 20 Japanese biomedical datasets across five tasks. Experimental results indicate that: (1) LLMs with a better understanding of Japanese and richer biomedical knowledge achieve better performance in Japanese biomedical tasks, (2) LLMs that are not mainly designed for Japanese biomedical domains can still perform unexpectedly well, and (3) there is still much room for improving the existing LLMs in certain Japanese biomedical tasks. Moreover, we offer insights that could further enhance development in this field. Our evaluation tools tailored to our benchmark as well as the datasets are publicly available in https://huggingface.co/datasets/Coldog2333/JMedBench to facilitate future research.
Read more9/23/2024
0
Towards Building Multilingual Language Model for Medicine
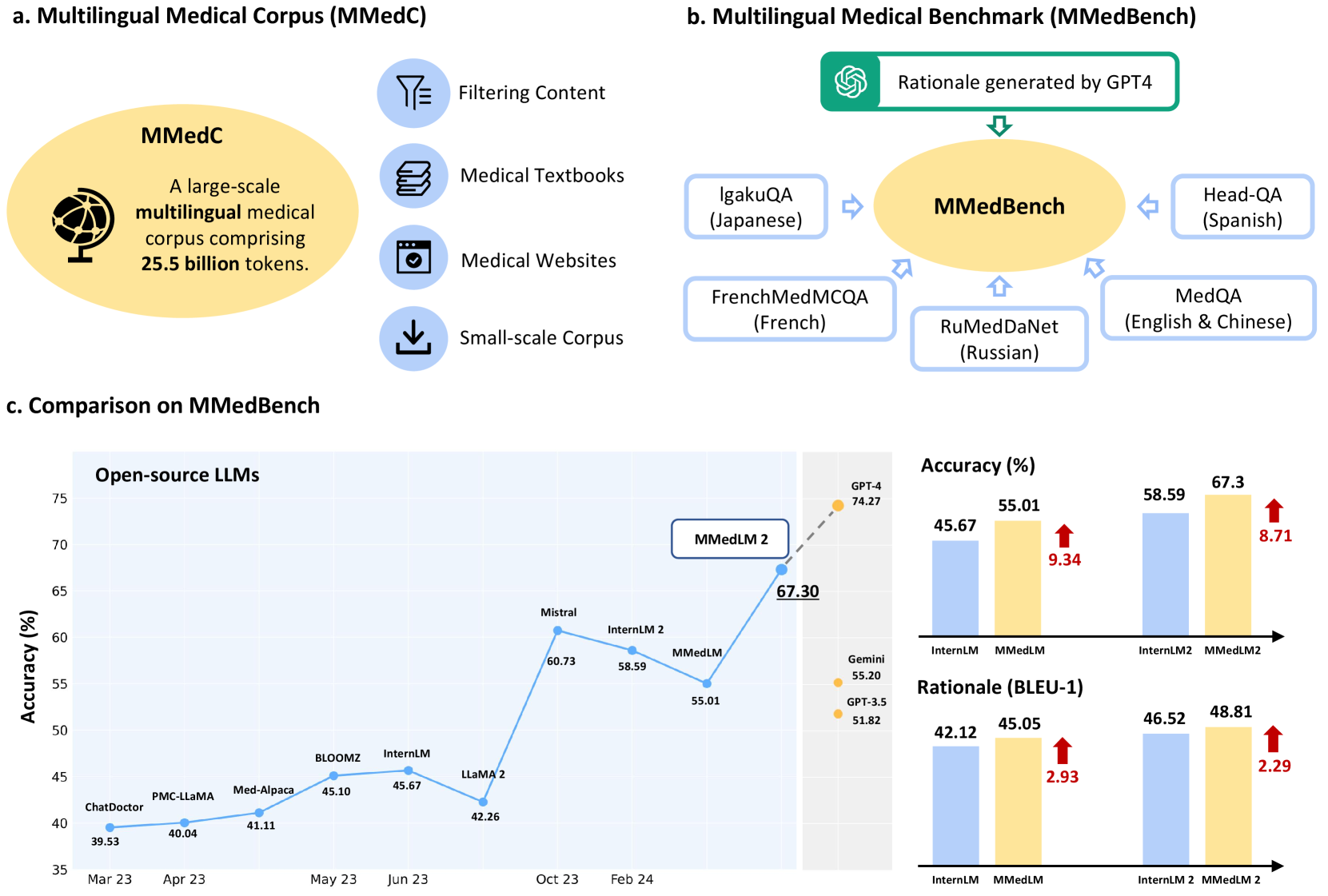
Pengcheng Qiu, Chaoyi Wu, Xiaoman Zhang, Weixiong Lin, Haicheng Wang, Ya Zhang, Yanfeng Wang, Weidi Xie
The development of open-source, multilingual medical language models can benefit a wide, linguistically diverse audience from different regions. To promote this domain, we present contributions from the following: First, we construct a multilingual medical corpus, containing approximately 25.5B tokens encompassing 6 main languages, termed as MMedC, enabling auto-regressive domain adaptation for general LLMs; Second, to monitor the development of multilingual medical LLMs, we propose a multilingual medical multi-choice question-answering benchmark with rationale, termed as MMedBench; Third, we have assessed a number of open-source large language models (LLMs) on our benchmark, along with those further auto-regressive trained on MMedC. Our final model, MMed-Llama 3, with only 8B parameters, achieves superior performance compared to all other open-source models on both MMedBench and English benchmarks, even rivaling GPT-4. In conclusion, in this work, we present a large-scale corpus, a benchmark and a series of models to support the development of multilingual medical LLMs.
Read more6/4/2024