JMedBench: A Benchmark for Evaluating Japanese Biomedical Large Language Models

0
Sign in to get full access
Overview
- Introduces JMedBench, a benchmark for evaluating Japanese biomedical large language models
- Covers related works in biomedical language model benchmarks
- Explains the design and development of the JMedBench benchmark
- Presents experimental results using JMedBench to evaluate various Japanese biomedical language models
- Discusses the limitations and future research directions
Plain English Explanation
The paper introduces JMedBench, a new benchmark for assessing the performance of large language models in the Japanese biomedical domain. Large language models, which are AI systems trained on massive amounts of text data, have shown impressive capabilities in various natural language tasks. However, evaluating their performance in specialized domains like biomedicine can be challenging.
The researchers developed JMedBench to provide a standardized and comprehensive evaluation framework for Japanese biomedical language models. The benchmark includes a diverse set of tasks, such as named entity recognition, relation extraction, and question answering, which are crucial for applications in the biomedical field. By using JMedBench, researchers and developers can compare the capabilities of different Japanese biomedical language models and identify areas for improvement.
The paper also reviews related works on biomedical language model benchmarks, highlighting the importance of creating specialized evaluation frameworks that capture the unique characteristics of different languages and domains.
Through the JMedBench benchmark, the researchers aim to foster the development of more robust and reliable Japanese biomedical language models, which can have a significant impact on various healthcare and life science applications, such as drug discovery, clinical decision support, and medical text processing.
Technical Explanation
The paper introduces JMedBench, a comprehensive benchmark for evaluating the performance of Japanese biomedical large language models. The benchmark includes a diverse set of tasks, such as named entity recognition, relation extraction, and question answering, which are designed to capture the unique challenges in the Japanese biomedical domain.
The researchers developed JMedBench by collecting and curating a large corpus of Japanese biomedical text data from various sources, including academic publications, clinical records, and online resources. They then created high-quality annotations for the tasks, ensuring the reliability and consistency of the benchmark.
To demonstrate the utility of JMedBench, the paper presents experimental results using several existing Japanese biomedical language models. The models were evaluated on the JMedBench tasks, and their performance was analyzed to identify strengths, weaknesses, and areas for improvement.
The paper also discusses the limitations of the current JMedBench benchmark and suggests future research directions, such as expanding the benchmark to include additional tasks, incorporating multilingual capabilities, and exploring the generalization of language models across different biomedical subdomains.
Critical Analysis
The JMedBench benchmark presented in the paper is a valuable contribution to the field of biomedical language model evaluation, particularly for the Japanese language. By providing a standardized and comprehensive evaluation framework, the researchers have addressed an important gap in the existing literature, which has primarily focused on English-language biomedical benchmarks.
One strength of the JMedBench benchmark is its diverse set of tasks, which cover a range of essential biomedical language processing capabilities. This diversity allows for a more thorough assessment of language model performance and can help identify specific areas where models excel or struggle.
However, the paper also acknowledges certain limitations of the current JMedBench benchmark. For example, the benchmark is limited to the Japanese language, and the researchers suggest expanding it to include multilingual capabilities or cross-domain generalization. Additionally, the paper highlights the need to continuously update and expand the benchmark as the field of biomedical language processing evolves.
Furthermore, while the paper presents experimental results using several existing Japanese biomedical language models, a more comprehensive evaluation involving a wider range of models, including those developed by different research groups or organizations, would provide a more robust assessment of the benchmark's utility and the state of the field.
Overall, the JMedBench benchmark is a significant step forward in the assessment of Japanese biomedical language models, and the researchers' commitment to improving and expanding the benchmark is commendable. As the field continues to evolve, the development of specialized and reliable evaluation frameworks like JMedBench will be crucial for driving progress and ensuring the real-world impact of biomedical language models.
Conclusion
The paper introduces JMedBench, a benchmark for evaluating the performance of Japanese biomedical large language models. The benchmark includes a diverse set of tasks and is designed to capture the unique challenges in the Japanese biomedical domain. By providing a standardized evaluation framework, the researchers aim to facilitate the development of more robust and reliable Japanese biomedical language models, which can have a significant impact on various healthcare and life science applications.
The paper also reviews related works in the field of biomedical language model benchmarking, highlighting the importance of creating specialized evaluation frameworks for different languages and domains. The experimental results presented in the paper demonstrate the utility of the JMedBench benchmark and identify areas for improvement in existing Japanese biomedical language models.
Overall, the JMedBench benchmark is a valuable contribution to the field of biomedical language processing, and its continued development and expansion can play a crucial role in advancing the capabilities of Japanese biomedical language models and their real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
JMedBench: A Benchmark for Evaluating Japanese Biomedical Large Language Models
Junfeng Jiang, Jiahao Huang, Akiko Aizawa
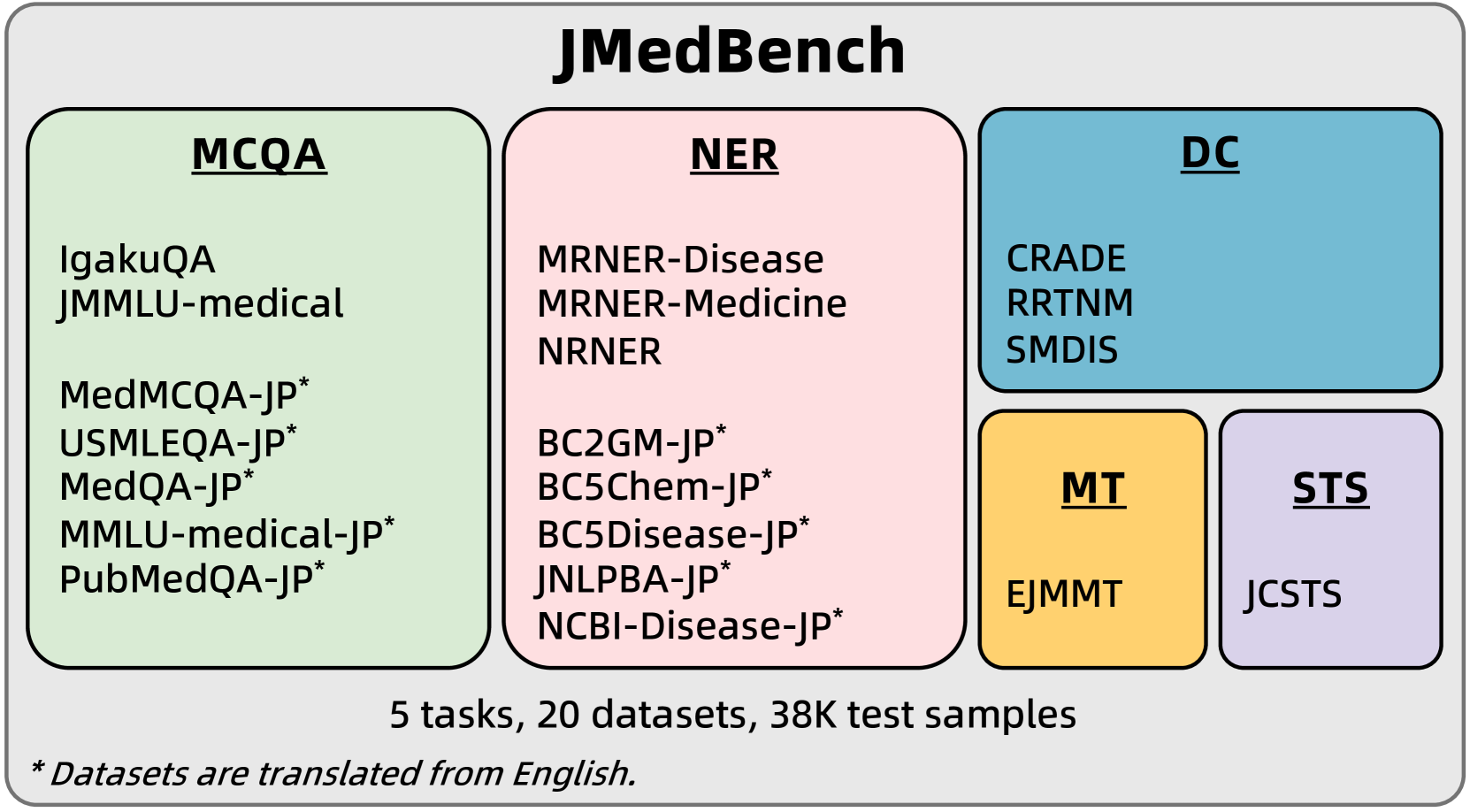
Recent developments in Japanese large language models (LLMs) primarily focus on general domains, with fewer advancements in Japanese biomedical LLMs. One obstacle is the absence of a comprehensive, large-scale benchmark for comparison. Furthermore, the resources for evaluating Japanese biomedical LLMs are insufficient. To advance this field, we propose a new benchmark including eight LLMs across four categories and 20 Japanese biomedical datasets across five tasks. Experimental results indicate that: (1) LLMs with a better understanding of Japanese and richer biomedical knowledge achieve better performance in Japanese biomedical tasks, (2) LLMs that are not mainly designed for Japanese biomedical domains can still perform unexpectedly well, and (3) there is still much room for improving the existing LLMs in certain Japanese biomedical tasks. Moreover, we offer insights that could further enhance development in this field. Our evaluation tools tailored to our benchmark as well as the datasets are publicly available in https://huggingface.co/datasets/Coldog2333/JMedBench to facilitate future research.
Read more9/23/2024
💬
0
Development and bilingual evaluation of Japanese medical large language model within reasonably low computational resources
Issey Sukeda
The recent success of large language models (LLMs) and the scaling law has led to a widespread adoption of larger models. Particularly in the healthcare industry, there is an increasing demand for locally operated LLMs due to security concerns. However, the majority of high quality open-source LLMs have a size of 70B parameters, imposing significant financial burdens on users for GPU preparation and operation. To overcome these issues, we present a medical adaptation based on the recent 7B models, which enables the operation in low computational resources. We compare the performance on medical question-answering benchmarks in two languages (Japanese and English), demonstrating that its scores reach parity with or surpass those of currently existing medical LLMs that are ten times larger. We find that fine-tuning an English-centric base model on Japanese medical dataset improves the score in both language, supporting the effect of cross-lingual knowledge transfer. We hope that this study will alleviate financial challenges, serving as a stepping stone for clinical institutions to practically utilize LLMs locally. Our evaluation code is available at https://github.com/stardust-coder/japanese-lm-med-harness.
Read more9/23/2024
💬
0
MedBench: A Comprehensive, Standardized, and Reliable Benchmarking System for Evaluating Chinese Medical Large Language Models
Mianxin Liu, Jinru Ding, Jie Xu, Weiguo Hu, Xiaoyang Li, Lifeng Zhu, Zhian Bai, Xiaoming Shi, Benyou Wang, Haitao Song, Pengfei Liu, Xiaofan Zhang, Shanshan Wang, Kang Li, Haofen Wang, Tong Ruan, Xuanjing Huang, Xin Sun, Shaoting Zhang
Ensuring the general efficacy and goodness for human beings from medical large language models (LLM) before real-world deployment is crucial. However, a widely accepted and accessible evaluation process for medical LLM, especially in the Chinese context, remains to be established. In this work, we introduce MedBench, a comprehensive, standardized, and reliable benchmarking system for Chinese medical LLM. First, MedBench assembles the currently largest evaluation dataset (300,901 questions) to cover 43 clinical specialties and performs multi-facet evaluation on medical LLM. Second, MedBench provides a standardized and fully automatic cloud-based evaluation infrastructure, with physical separations for question and ground truth. Third, MedBench implements dynamic evaluation mechanisms to prevent shortcut learning and answer remembering. Applying MedBench to popular general and medical LLMs, we observe unbiased, reproducible evaluation results largely aligning with medical professionals' perspectives. This study establishes a significant foundation for preparing the practical applications of Chinese medical LLMs. MedBench is publicly accessible at https://medbench.opencompass.org.cn.
Read more7/17/2024

0
Towards Evaluating and Building Versatile Large Language Models for Medicine
Chaoyi Wu, Pengcheng Qiu, Jinxin Liu, Hongfei Gu, Na Li, Ya Zhang, Yanfeng Wang, Weidi Xie
In this study, we present MedS-Bench, a comprehensive benchmark designed to evaluate the performance of large language models (LLMs) in clinical contexts. Unlike existing benchmarks that focus on multiple-choice question answering, MedS-Bench spans 11 high-level clinical tasks, including clinical report summarization, treatment recommendations, diagnosis, named entity recognition, and medical concept explanation, among others. We evaluated six leading LLMs, e.g., MEDITRON, Mistral, InternLM 2, Llama 3, GPT-4, and Claude-3.5 using few-shot prompting, and found that even the most sophisticated models struggle with these complex tasks. To address these limitations, we developed MedS-Ins, a large-scale instruction tuning dataset for medicine. MedS-Ins comprises 58 medically oriented language corpora, totaling 13.5 million samples across 122 tasks. To demonstrate the dataset's utility, we conducted a proof-of-concept experiment by performing instruction tuning on a lightweight, open-source medical language model. The resulting model, MMedIns-Llama 3, significantly outperformed existing models across nearly all clinical tasks. To promote further advancements in the application of LLMs to clinical challenges, we have made the MedS-Ins dataset fully accessible and invite the research community to contribute to its expansion.Additionally, we have launched a dynamic leaderboard for MedS-Bench, which we plan to regularly update the test set to track progress and enhance the adaptation of general LLMs to the medical domain. Leaderboard: https://henrychur.github.io/MedS-Bench/. Github: https://github.com/MAGIC-AI4Med/MedS-Ins.
Read more9/6/2024