Devil's Advocate: Anticipatory Reflection for LLM Agents

0

Sign in to get full access
Overview
- This paper explores the concept of "Devil's Advocate" - a technique where an AI agent anticipates and reflects on potential counterarguments or alternative perspectives to enhance its problem-solving capabilities.
- The authors propose a framework for implementing this self-reflection mechanism in Large Language Models (LLMs), aiming to improve their understanding of the problem context and generate more robust solutions.
- The paper investigates the effects of this anticipatory reflection on an LLM's problem-solving performance, as well as its ability to identify and mitigate biases or flaws in its own reasoning.
Plain English Explanation
The researchers in this paper are exploring a technique called "Devil's Advocate" that could help improve the problem-solving abilities of AI language models. The basic idea is that the AI model doesn't just come up with a single solution, but instead tries to anticipate and reflect on potential counterarguments or alternative perspectives before proposing a final answer.
For example, let's say the AI is tasked with coming up with a marketing plan for a new product. Instead of just generating one plan, the "Devil's Advocate" approach would have the AI model consider alternative strategies, potential risks, and objections that customers might have. By doing this self-reflection, the AI can develop a more robust and well-rounded solution that's better prepared to handle various challenges.
The researchers believe that this anticipatory reflection can help language models like GPT-3 or ChatGPT to better understand the problem context, identify their own biases or blindspots, and ultimately come up with more reliable and effective solutions. The paper explores how this technique could be implemented in practice and what the potential benefits and limitations might be.
Technical Explanation
The authors propose a framework for incorporating "anticipatory reflection" into Large Language Model (LLM) agents to enhance their problem-solving capabilities. The core idea is to have the LLM generate not just a single solution, but also consider potential counterarguments or alternative perspectives before finalizing its response.
The framework consists of several key components:
- Reflection Triggers: The system identifies specific points in the problem-solving process where the agent should pause and reflect on alternative viewpoints or potential issues with its proposed solution.
- Reflection Generation: The agent then generates a set of reflective prompts that anticipate and address these alternative perspectives, drawing on its knowledge and reasoning abilities.
- Reflection Integration: The agent integrates the insights from its self-reflection into the final solution, resulting in a more comprehensive and robust response.
The authors evaluate this framework through a series of experiments, assessing the LLM's problem-solving performance, its ability to identify and mitigate biases, and the quality of the generated reflective prompts. The results suggest that the anticipatory reflection mechanism can lead to significant improvements in the LLM's problem-solving capabilities, as well as its self-awareness and transparency.
Critical Analysis
The paper presents a compelling approach to enhancing the problem-solving abilities of LLMs through the use of anticipatory reflection. However, there are a few potential limitations and areas for further research:
-
Scalability and Computational Complexity: Implementing the full "Devil's Advocate" framework may pose challenges in terms of computational resources and scalability, especially for large-scale or real-time applications. The authors acknowledge this and suggest the need for further optimization and efficiency improvements.
-
Generalization and Transferability: The paper focuses on the effectiveness of the anticipatory reflection mechanism within a specific problem-solving context. It would be valuable to explore how well these techniques generalize to a broader range of tasks and domains, and whether the benefits can be transferred to other LLM architectures and applications.
-
Ethical Considerations: While the authors discuss the potential for the "Devil's Advocate" approach to improve transparency and mitigate biases, there may be additional ethical considerations around the use of this technique, particularly in decision-making systems with high stakes or societal impact. Further research is needed to assess the ethical implications and develop appropriate safeguards.
-
Human-AI Interaction: The paper primarily focuses on the internal workings of the LLM agent. Exploring how this anticipatory reflection mechanism could be integrated into human-AI collaborative workflows and its impact on user trust and acceptance would be a valuable direction for future work.
Overall, the "Devil's Advocate" framework presented in this paper offers a promising approach to enhancing the problem-solving capabilities of LLMs, with potential implications for a wide range of AI applications. The critical analysis highlights areas for further research and development to address the identified limitations and unlock the full potential of this technique.
Conclusion
This paper introduces the concept of "Devil's Advocate" as a mechanism for Large Language Model (LLM) agents to engage in anticipatory reflection, considering alternative perspectives and potential counterarguments before proposing solutions to complex problems. The proposed framework aims to improve the LLM's understanding of the problem context, identify and mitigate its own biases, and generate more robust and effective solutions.
The authors' experiments demonstrate the potential benefits of this anticipatory reflection approach, including enhanced problem-solving performance and increased transparency. However, the paper also highlights the need for further research to address scalability, generalization, ethical considerations, and human-AI interaction challenges.
Overall, this work represents an important step towards developing more self-aware and adaptive AI agents that can navigate complex problem-solving scenarios with greater nuance and sophistication. As the capabilities of LLMs continue to evolve, techniques like "Devil's Advocate" may play a crucial role in ensuring these powerful systems are aligned with human values and can be trusted to tackle real-world problems effectively.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Devil's Advocate: Anticipatory Reflection for LLM Agents
Haoyu Wang, Tao Li, Zhiwei Deng, Dan Roth, Yang Li
In this work, we introduce a novel approach that equips LLM agents with introspection, enhancing consistency and adaptability in solving complex tasks. Our approach prompts LLM agents to decompose a given task into manageable subtasks (i.e., to make a plan), and to continuously introspect upon the suitability and results of their actions. %; and when necessary, to explore ``the road not taken.'' We implement a three-fold introspective intervention: 1) anticipatory reflection on potential failures and alternative remedy before action execution, 2) post-action alignment with subtask objectives and backtracking with remedy to ensure utmost effort in plan execution, and 3) comprehensive review upon plan completion for future strategy refinement. By deploying and experimenting with this methodology -- a zero-shot approach -- within WebArena for practical tasks in web environments, our agent demonstrates superior performance with a success rate of 23.5% over existing zero-shot methods by 3.5%. The experimental results suggest that our introspection-driven approach not only enhances the agent's ability to navigate unanticipated challenges through a robust mechanism of plan execution, but also improves efficiency by reducing the number of trials and plan revisions by 45% needed to achieve a task.
Read more6/24/2024

0
Introspective Planning: Aligning Robots' Uncertainty with Inherent Task Ambiguity
Kaiqu Liang, Zixu Zhang, Jaime Fern'andez Fisac
Large language models (LLMs) exhibit advanced reasoning skills, enabling robots to comprehend natural language instructions and strategically plan high-level actions through proper grounding. However, LLM hallucination may result in robots confidently executing plans that are misaligned with user goals or, in extreme cases, unsafe. Additionally, inherent ambiguity in natural language instructions can induce task uncertainty, particularly in situations where multiple valid options exist. To address this issue, LLMs must identify such uncertainty and proactively seek clarification. This paper explores the concept of introspective planning as a systematic method for guiding LLMs in forming uncertainty--aware plans for robotic task execution without the need for fine-tuning. We investigate uncertainty quantification in task-level robot planning and demonstrate that introspection significantly improves both success rates and safety compared to state-of-the-art LLM-based planning approaches. Furthermore, we assess the effectiveness of introspective planning in conjunction with conformal prediction, revealing that this combination yields tighter confidence bounds, thereby maintaining statistical success guarantees with fewer superfluous user clarification queries. Code is available at https://github.com/kevinliang888/IntroPlan.
Read more6/5/2024
0
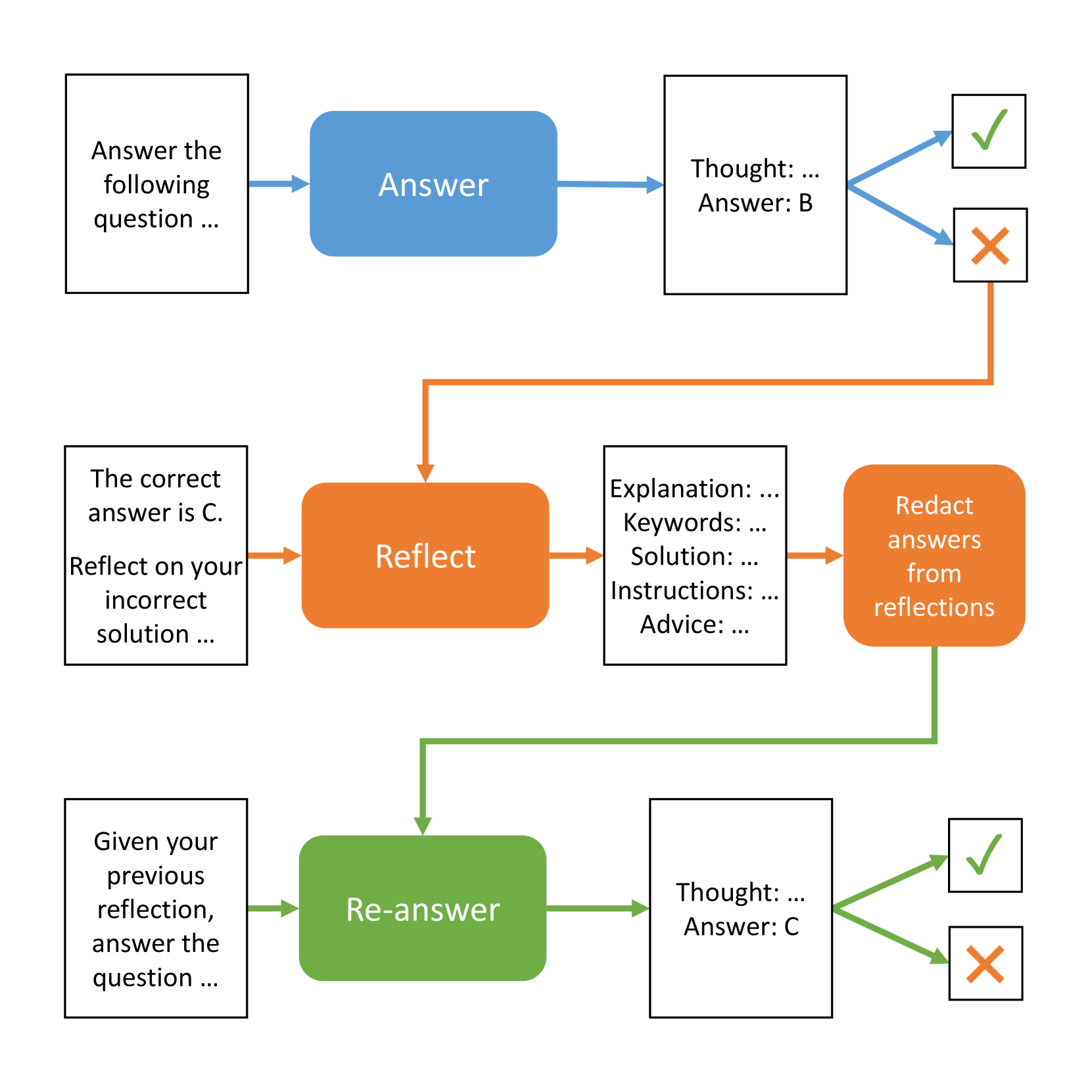
Self-Reflection in LLM Agents: Effects on Problem-Solving Performance
Matthew Renze, Erhan Guven
In this study, we investigated the effects of self-reflection in large language models (LLMs) on problem-solving performance. We instructed nine popular LLMs to answer a series of multiple-choice questions to provide a performance baseline. For each incorrectly answered question, we instructed eight types of self-reflecting LLM agents to reflect on their mistakes and provide themselves with guidance to improve problem-solving. Then, using this guidance, each self-reflecting agent attempted to re-answer the same questions. Our results indicate that LLM agents are able to significantly improve their problem-solving performance through self-reflection ($p < 0.001$). In addition, we compared the various types of self-reflection to determine their individual contribution to performance. All code and data are available on GitHub at https://github.com/matthewrenze/self-reflection
Read more9/10/2024
0
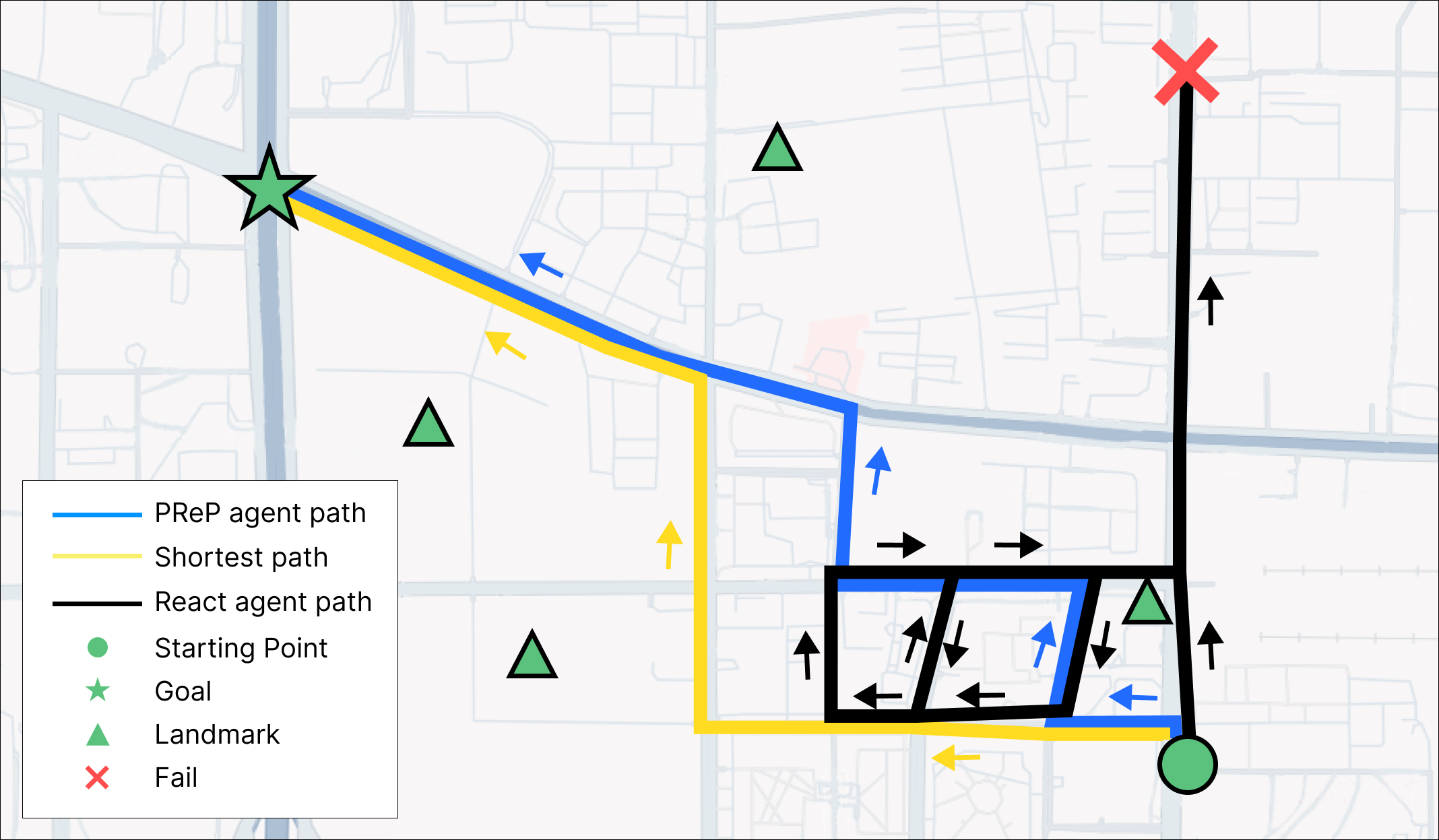
Perceive, Reflect, and Plan: Designing LLM Agent for Goal-Directed City Navigation without Instructions
Qingbin Zeng, Qinglong Yang, Shunan Dong, Heming Du, Liang Zheng, Fengli Xu, Yong Li
This paper considers a scenario in city navigation: an AI agent is provided with language descriptions of the goal location with respect to some well-known landmarks; By only observing the scene around, including recognizing landmarks and road network connections, the agent has to make decisions to navigate to the goal location without instructions. This problem is very challenging, because it requires agent to establish self-position and acquire spatial representation of complex urban environment, where landmarks are often invisible. In the absence of navigation instructions, such abilities are vital for the agent to make high-quality decisions in long-range city navigation. With the emergent reasoning ability of large language models (LLMs), a tempting baseline is to prompt LLMs to react on each observation and make decisions accordingly. However, this baseline has very poor performance that the agent often repeatedly visits same locations and make short-sighted, inconsistent decisions. To address these issues, this paper introduces a novel agentic workflow featured by its abilities to perceive, reflect and plan. Specifically, we find LLaVA-7B can be fine-tuned to perceive the direction and distance of landmarks with sufficient accuracy for city navigation. Moreover, reflection is achieved through a memory mechanism, where past experiences are stored and can be retrieved with current perception for effective decision argumentation. Planning uses reflection results to produce long-term plans, which can avoid short-sighted decisions in long-range navigation. We show the designed workflow significantly improves navigation ability of the LLM agent compared with the state-of-the-art baselines.
Read more9/6/2024