DialogBench: Evaluating LLMs as Human-like Dialogue Systems
2311.01677
0
0
📉
Abstract
Large language models (LLMs) have achieved remarkable breakthroughs in new dialogue capabilities by leveraging instruction tuning, which refreshes human impressions of dialogue systems. The long-standing goal of dialogue systems is to be human-like enough to establish long-term connections with users. Therefore, there has been an urgent need to evaluate LLMs as human-like dialogue systems. In this paper, we propose DialogBench, a dialogue evaluation benchmark that contains 12 dialogue tasks to probe the capabilities of LLMs as human-like dialogue systems should have. Specifically, we prompt GPT-4 to generate evaluation instances for each task. We first design the basic prompt based on widely used design principles and further mitigate the existing biases to generate higher-quality evaluation instances. Our extensive tests on English and Chinese DialogBench of 26 LLMs show that instruction tuning improves the human likeness of LLMs to a certain extent, but most LLMs still have much room for improvement as human-like dialogue systems. Interestingly, results also show that the positioning of assistant AI can make instruction tuning weaken the human emotional perception of LLMs and their mastery of information about human daily life.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Large language models (LLMs) have made significant advancements in dialogue capabilities through instruction tuning, which improves how humans perceive these dialogue systems.
- The ultimate goal of dialogue systems is to establish long-term connections with users by being sufficiently human-like.
- There is an urgent need to evaluate LLMs as human-like dialogue systems.
Plain English Explanation
Artificial intelligence (AI) has made remarkable progress in developing language models that can engage in human-like dialogue. These large language models (LLMs) have become increasingly adept at understanding and responding to conversational prompts, thanks to a technique called instruction tuning. This process helps refine the models to better match human impressions and expectations of a helpful, conversational partner.
The researchers behind this study recognize that the ultimate aim of dialogue systems should be to forge genuine, long-lasting connections with users. To achieve this, these AI systems need to be as human-like as possible in their interactions. That's why the team has developed a new evaluation tool, called DialogBench, to rigorously test the human-likeness of various LLMs.
Technical Explanation
The researchers created DialogBench, a benchmark containing 12 distinct dialogue tasks designed to probe the capabilities of LLMs in areas critical for human-like dialogue. These tasks cover a range of conversational scenarios, from emotional support and information-seeking to task planning and small talk.
To generate the evaluation instances for each task, the researchers prompted the powerful GPT-4 model. They first designed a basic prompt based on established design principles, and then further refined the prompts to mitigate existing biases and produce higher-quality examples.
The team then put 26 different LLMs, including GPT-4, through the DialogBench evaluation. The results showed that while instruction tuning does improve the human-likeness of these models to some degree, most LLMs still have significant room for improvement when it comes to achieving truly human-like dialogue capabilities.
Interestingly, the researchers also found that the positioning of the AI assistant - whether it is presented as a helpful tool or a more personal conversational partner - can impact the effectiveness of instruction tuning. In some cases, this positioning can weaken the human emotional perception of the LLM and its grasp of everyday human knowledge.
Critical Analysis
The DialogBench evaluation framework represents a valuable contribution to the field of dialogue system development, as it provides a standardized way to assess the human-likeness of LLMs. By testing across a diverse set of conversational scenarios, the researchers have unveiled important insights into the current limitations of these models.
However, it's worth noting that the evaluation is still limited to English and Chinese language models. Expanding the benchmark to include a wider range of languages and cultural contexts could yield additional insights.
Additionally, the researchers acknowledge that the prompting process used to generate the evaluation instances, while carefully designed, may still contain inherent biases. Exploring alternative approaches to prompt engineering could help address this limitation.
Conclusion
This research highlights the significant progress made in developing human-like dialogue capabilities through instruction tuning, but also underscores the ongoing challenges in creating AI systems that can truly connect with users on a deep, emotional level. The DialogBench framework provides a valuable tool for driving further advancements in this critical area of AI research and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Designing and Evaluating Dialogue LLMs for Co-Creative Improvised Theatre
Boyd Branch, Piotr Mirowski, Kory Mathewson, Sophia Ppali, Alexandra Covaci
0
0
Social robotics researchers are increasingly interested in multi-party trained conversational agents. With a growing demand for real-world evaluations, our study presents Large Language Models (LLMs) deployed in a month-long live show at the Edinburgh Festival Fringe. This case study investigates human improvisers co-creating with conversational agents in a professional theatre setting. We explore the technical capabilities and constraints of on-the-spot multi-party dialogue, providing comprehensive insights from both audience and performer experiences with AI on stage. Our human-in-the-loop methodology underlines the challenges of these LLMs in generating context-relevant responses, stressing the user interface's crucial role. Audience feedback indicates an evolving interest for AI-driven live entertainment, direct human-AI interaction, and a diverse range of expectations about AI's conversational competence and utility as a creativity support tool. Human performers express immense enthusiasm, varied satisfaction, and the evolving public opinion highlights mixed emotions about AI's role in arts.
5/14/2024

How Well Can LLMs Echo Us? Evaluating AI Chatbots' Role-Play Ability with ECHO
Man Tik Ng, Hui Tung Tse, Jen-tse Huang, Jingjing Li, Wenxuan Wang, Michael R. Lyu
0
0
The role-play ability of Large Language Models (LLMs) has emerged as a popular research direction. However, existing studies focus on imitating well-known public figures or fictional characters, overlooking the potential for simulating ordinary individuals. Such an oversight limits the potential for advancements in digital human clones and non-player characters in video games. To bridge this gap, we introduce ECHO, an evaluative framework inspired by the Turing test. This framework engages the acquaintances of the target individuals to distinguish between human and machine-generated responses. Notably, our framework focuses on emulating average individuals rather than historical or fictional figures, presenting a unique advantage to apply the Turing Test. We evaluated three role-playing LLMs using ECHO, with GPT-3.5 and GPT-4 serving as foundational models, alongside the online application GPTs from OpenAI. Our results demonstrate that GPT-4 more effectively deceives human evaluators, and GPTs achieves a leading success rate of 48.3%. Furthermore, we investigated whether LLMs could discern between human-generated and machine-generated texts. While GPT-4 can identify differences, it could not determine which texts were human-produced. Our code and results of reproducing the role-playing LLMs are made publicly available via https://github.com/CUHK-ARISE/ECHO.
4/23/2024
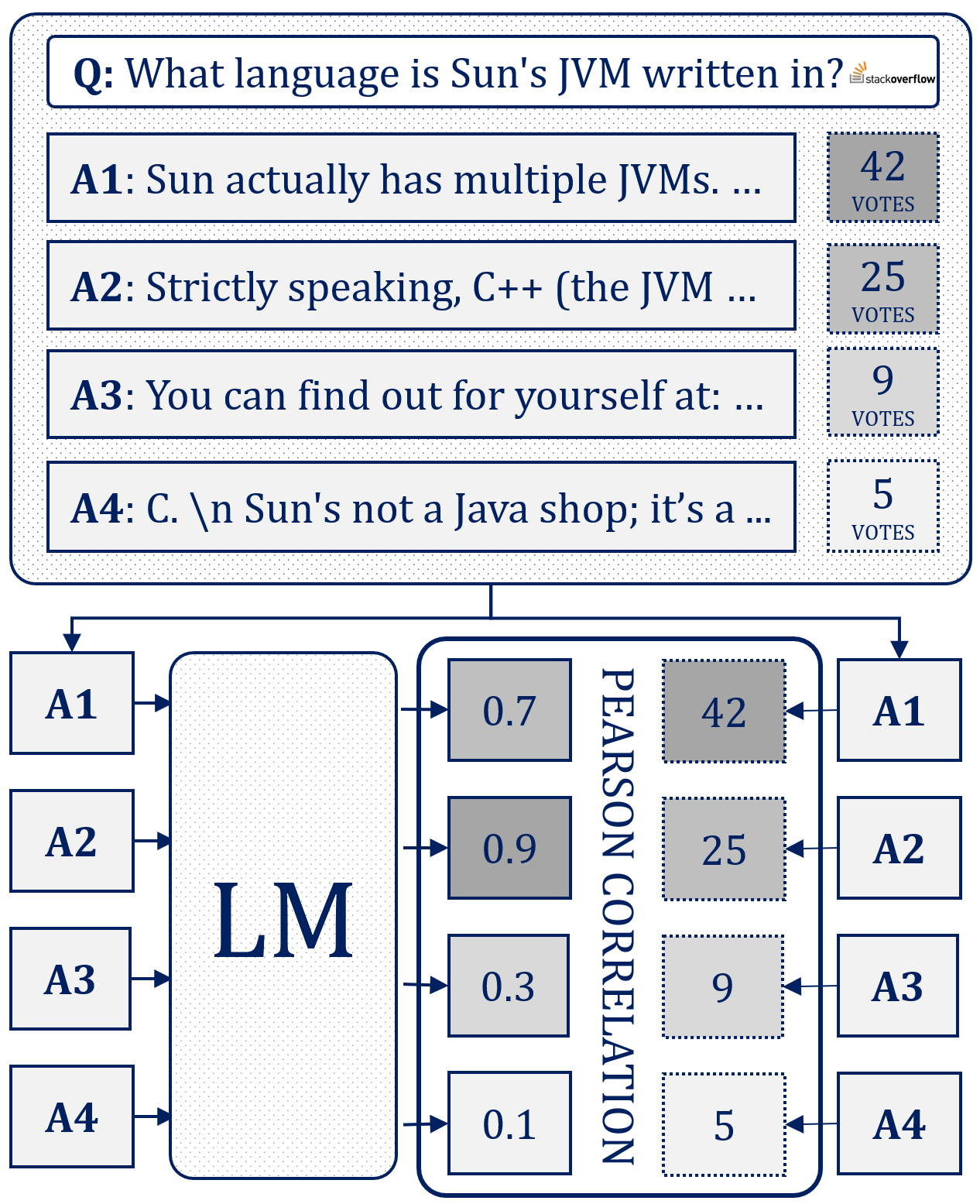
HumanRankEval: Automatic Evaluation of LMs as Conversational Assistants
Milan Gritta, Gerasimos Lampouras, Ignacio Iacobacci
0
0
Language models (LMs) as conversational assistants recently became popular tools that help people accomplish a variety of tasks. These typically result from adapting LMs pretrained on general domain text sequences through further instruction-tuning and possibly preference optimisation methods. The evaluation of such LMs would ideally be performed using human judgement, however, this is not scalable. On the other hand, automatic evaluation featuring auxiliary LMs as judges and/or knowledge-based tasks is scalable but struggles with assessing conversational ability and adherence to instructions. To help accelerate the development of LMs as conversational assistants, we propose a novel automatic evaluation task: HumanRankEval (HRE). It consists of a large-scale, diverse and high-quality set of questions, each with several answers authored and scored by humans. To perform evaluation, HRE ranks these answers based on their log-likelihood under the LM's distribution, and subsequently calculates their correlation with the corresponding human rankings. We support HRE's efficacy by investigating how efficiently it separates pretrained and instruction-tuned LMs of various sizes. We show that HRE correlates well with human judgements and is particularly responsive to model changes following instruction-tuning.
5/16/2024
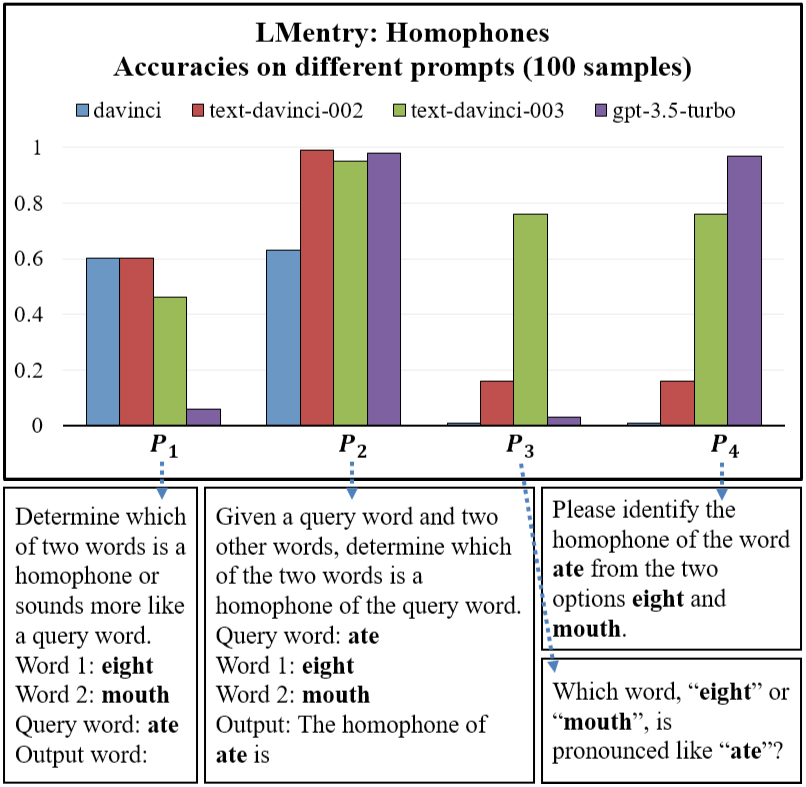
State of What Art? A Call for Multi-Prompt LLM Evaluation
Moran Mizrahi, Guy Kaplan, Dan Malkin, Rotem Dror, Dafna Shahaf, Gabriel Stanovsky
0
0
Recent advances in large language models (LLMs) have led to the development of various evaluation benchmarks. These benchmarks typically rely on a single instruction template for evaluating all LLMs on a specific task. In this paper, we comprehensively analyze the brittleness of results obtained via single-prompt evaluations across 6.5M instances, involving 20 different LLMs and 39 tasks from 3 benchmarks. To improve robustness of the analysis, we propose to evaluate LLMs with a set of diverse prompts instead. We discuss tailored evaluation metrics for specific use cases (e.g., LLM developers vs. developers interested in a specific downstream task), ensuring a more reliable and meaningful assessment of LLM capabilities. We then implement these criteria and conduct evaluations of multiple models, providing insights into the true strengths and limitations of current LLMs.
5/7/2024