HumanRankEval: Automatic Evaluation of LMs as Conversational Assistants
2405.09186
0
0
Abstract
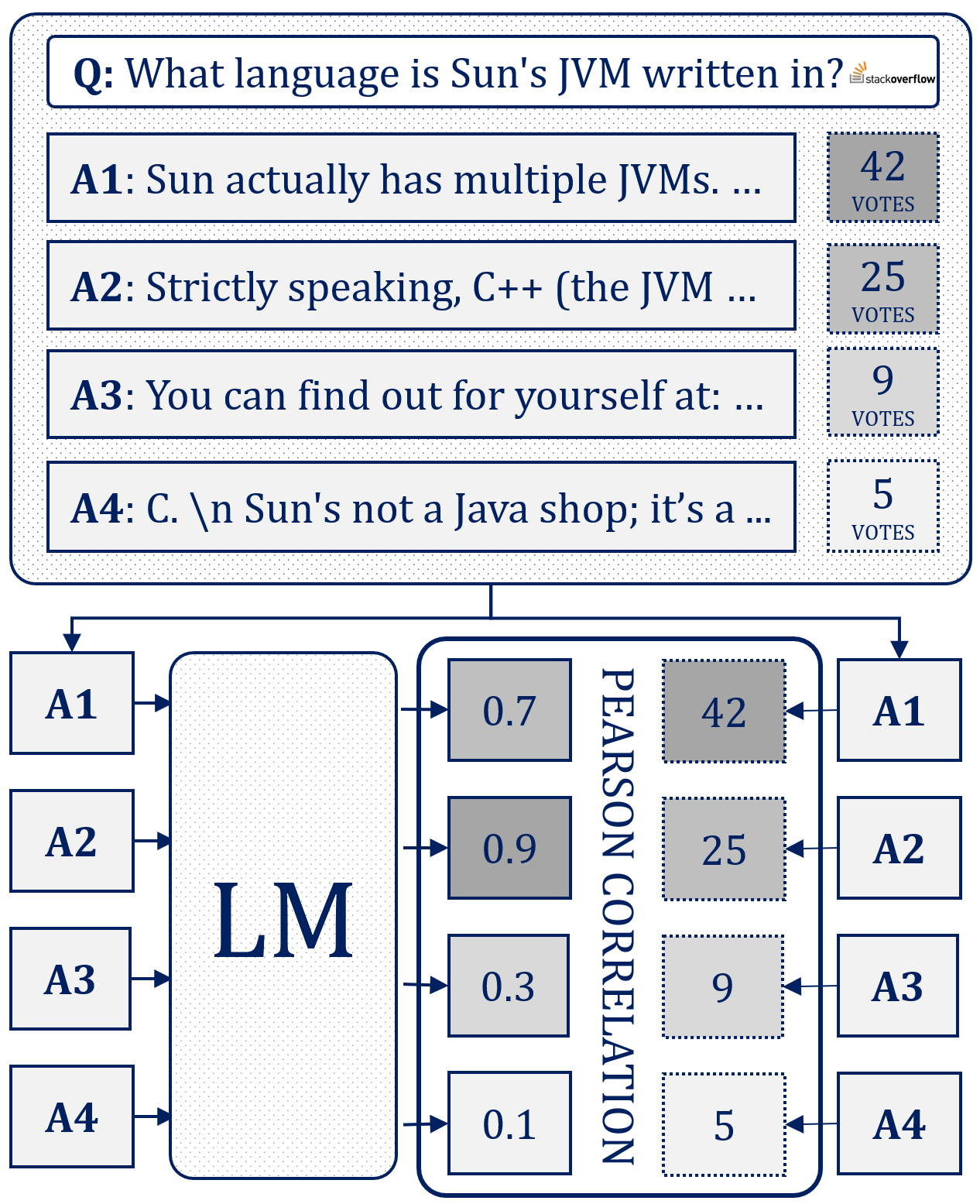
Language models (LMs) as conversational assistants recently became popular tools that help people accomplish a variety of tasks. These typically result from adapting LMs pretrained on general domain text sequences through further instruction-tuning and possibly preference optimisation methods. The evaluation of such LMs would ideally be performed using human judgement, however, this is not scalable. On the other hand, automatic evaluation featuring auxiliary LMs as judges and/or knowledge-based tasks is scalable but struggles with assessing conversational ability and adherence to instructions. To help accelerate the development of LMs as conversational assistants, we propose a novel automatic evaluation task: HumanRankEval (HRE). It consists of a large-scale, diverse and high-quality set of questions, each with several answers authored and scored by humans. To perform evaluation, HRE ranks these answers based on their log-likelihood under the LM's distribution, and subsequently calculates their correlation with the corresponding human rankings. We support HRE's efficacy by investigating how efficiently it separates pretrained and instruction-tuned LMs of various sizes. We show that HRE correlates well with human judgements and is particularly responsive to model changes following instruction-tuning.
Create account to get full access
Overview
- This paper presents HumanRankEval, a new framework for automatically evaluating large language models (LLMs) as conversational assistants.
- The authors argue that existing evaluation methods do not adequately capture the full range of capabilities required for a conversational AI, such as contextual understanding, coherence, and empathy.
- HumanRankEval aims to address this gap by introducing a more comprehensive set of metrics that better reflect human preferences for conversational partners.
Plain English Explanation
The paper introduces a new way to automatically evaluate how good large language models (like ChatGPT) are at being helpful, friendly, and human-like conversation partners. Existing evaluation methods focus mainly on things like factual knowledge or language fluency, but the authors argue that being a good conversational AI requires a broader set of skills, including understanding context, staying coherent, and showing empathy.
HumanRankEval is designed to capture these more nuanced conversational abilities. Instead of just looking at things like grammatical accuracy, the evaluation framework considers factors like how natural and engaging the AI's responses feel to human judges. The goal is to better mimic how humans would actually evaluate a potential conversation partner, not just their raw language abilities.
By using this more holistic approach, the researchers hope to drive the development of LLMs that can engage in more natural, human-like dialogue, going beyond just factual question-answering or simple chatbots. This could lead to AI assistants that feel more personable, empathetic, and truly helpful in a wide range of conversational scenarios.
Technical Explanation
The core of the HumanRankEval framework is a set of metrics that capture different aspects of conversational ability, including contextual understanding, coherence, personality, and empathy. These metrics are designed to better reflect human preferences for conversational partners compared to existing evaluation approaches focused on more narrow language tasks.
To assess these capabilities, the authors collect a dataset of human-AI dialogues, where human judges rate the AI's responses on a scale from 1-5 across the different metrics. This allows them to train models to predict human rankings of conversational quality based on the dialogue context and AI outputs.
The paper then demonstrates the utility of the HumanRankEval framework by applying it to evaluate several prominent LLMs, including GPT-3 and Delphi. The results show that the models exhibit varying strengths and weaknesses across the different conversational dimensions, highlighting the need for more holistic evaluation to guide future model development.
Critical Analysis
The HumanRankEval framework represents an important step forward in evaluating LLMs as conversational AI assistants. By moving beyond narrow language tasks to more holistic measures of conversational ability, the authors have highlighted key areas for improvement, such as contextual understanding and empathetic response generation.
However, the paper acknowledges several limitations of the current approach. For one, the dataset of human-rated dialogues is still relatively small, and may not capture the full diversity of conversational scenarios. There are also open questions around how well the model-based predictions of human rankings correlate with actual human preferences in real-world settings.
Additionally, while the evaluation metrics cover important aspects of conversation, there may be other relevant factors, such as the ability to engage in extended, multi-turn dialogues or handle more complex reasoning tasks. Further research is needed to expand the scope of HumanRankEval and ensure it comprehensively assesses the full range of conversational skills.
Overall, this work represents a valuable contribution to the field of conversational AI evaluation. By highlighting the limitations of existing approaches and introducing a more holistic framework, the authors have laid the groundwork for developing LLMs that can engage in more natural, human-like dialogue.
Conclusion
The HumanRankEval framework proposed in this paper offers a more comprehensive approach to evaluating large language models as conversational AI assistants. By focusing on measures of contextual understanding, coherence, personality, and empathy, the authors aim to better capture the full range of skills required for natural, engaging dialogue.
The results of applying HumanRankEval to prominent LLMs suggest that current models still have room for improvement in certain conversational dimensions. This highlights the importance of holistic evaluation approaches to drive the development of more human-like, helpful AI assistants.
While the current HumanRankEval framework has some limitations, it represents an important step forward in the field of conversational AI evaluation. Continued research to expand the scope and robustness of this approach could lead to significant advances in the quality and capabilities of large language models as interactive, empathetic conversational partners.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
The RealHumanEval: Evaluating Large Language Models' Abilities to Support Programmers
Hussein Mozannar, Valerie Chen, Mohammed Alsobay, Subhro Das, Sebastian Zhao, Dennis Wei, Manish Nagireddy, Prasanna Sattigeri, Ameet Talwalkar, David Sontag
0
0
Evaluation of large language models (LLMs) for code has primarily relied on static benchmarks, including HumanEval (Chen et al., 2021), which measure the ability of LLMs to generate complete code that passes unit tests. As LLMs are increasingly used as programmer assistants, we study whether gains on existing benchmarks translate to gains in programmer productivity when coding with LLMs, including time spent coding. In addition to static benchmarks, we investigate the utility of preference metrics that might be used as proxies to measure LLM helpfulness, such as code acceptance or copy rates. To do so, we introduce RealHumanEval, a web interface to measure the ability of LLMs to assist programmers, through either autocomplete or chat support. We conducted a user study (N=213) using RealHumanEval in which users interacted with six LLMs of varying base model performance. Despite static benchmarks not incorporating humans-in-the-loop, we find that improvements in benchmark performance lead to increased programmer productivity; however gaps in benchmark versus human performance are not proportional -- a trend that holds across both forms of LLM support. In contrast, we find that programmer preferences do not correlate with their actual performance, motivating the need for better, human-centric proxy signals. We also open-source RealHumanEval to enable human-centric evaluation of new models and the study data to facilitate efforts to improve code models.
4/4/2024
📉
DialogBench: Evaluating LLMs as Human-like Dialogue Systems
Jiao Ou, Junda Lu, Che Liu, Yihong Tang, Fuzheng Zhang, Di Zhang, Kun Gai
0
0
Large language models (LLMs) have achieved remarkable breakthroughs in new dialogue capabilities by leveraging instruction tuning, which refreshes human impressions of dialogue systems. The long-standing goal of dialogue systems is to be human-like enough to establish long-term connections with users. Therefore, there has been an urgent need to evaluate LLMs as human-like dialogue systems. In this paper, we propose DialogBench, a dialogue evaluation benchmark that contains 12 dialogue tasks to probe the capabilities of LLMs as human-like dialogue systems should have. Specifically, we prompt GPT-4 to generate evaluation instances for each task. We first design the basic prompt based on widely used design principles and further mitigate the existing biases to generate higher-quality evaluation instances. Our extensive tests on English and Chinese DialogBench of 26 LLMs show that instruction tuning improves the human likeness of LLMs to a certain extent, but most LLMs still have much room for improvement as human-like dialogue systems. Interestingly, results also show that the positioning of assistant AI can make instruction tuning weaken the human emotional perception of LLMs and their mastery of information about human daily life.
4/1/2024
🛠️
Fusion-Eval: Integrating Assistant Evaluators with LLMs
Lei Shu, Nevan Wichers, Liangchen Luo, Yun Zhu, Yinxiao Liu, Jindong Chen, Lei Meng
0
0
Evaluating natural language systems poses significant challenges, particularly in the realms of natural language understanding and high-level reasoning. In this paper, we introduce 'Fusion-Eval', an innovative approach that leverages Large Language Models (LLMs) to integrate insights from various assistant evaluators. The LLM is given the example to evaluate along with scores from the assistant evaluators. Each of these evaluators specializes in assessing distinct aspects of responses. Fusion-Eval achieves a 0.962 system-level Kendall-Tau correlation with humans on SummEval and a 0.744 turn-level Spearman correlation on TopicalChat, which is significantly higher than baseline methods. These results highlight Fusion-Eval's significant potential in the realm of natural language system evaluation.
6/10/2024
The Challenges of Evaluating LLM Applications: An Analysis of Automated, Human, and LLM-Based Approaches
Bhashithe Abeysinghe, Ruhan Circi
0
0
Chatbots have been an interesting application of natural language generation since its inception. With novel transformer based Generative AI methods, building chatbots have become trivial. Chatbots which are targeted at specific domains for example medicine and psychology are implemented rapidly. This however, should not distract from the need to evaluate the chatbot responses. Especially because the natural language generation community does not entirely agree upon how to effectively evaluate such applications. With this work we discuss the issue further with the increasingly popular LLM based evaluations and how they correlate with human evaluations. Additionally, we introduce a comprehensive factored evaluation mechanism that can be utilized in conjunction with both human and LLM-based evaluations. We present the results of an experimental evaluation conducted using this scheme in one of our chatbot implementations which consumed educational reports, and subsequently compare automated, traditional human evaluation, factored human evaluation, and factored LLM evaluation. Results show that factor based evaluation produces better insights on which aspects need to be improved in LLM applications and further strengthens the argument to use human evaluation in critical spaces where main functionality is not direct retrieval.
6/14/2024