Diff-IP2D: Diffusion-Based Hand-Object Interaction Prediction on Egocentric Videos

0
🔮
Sign in to get full access
Overview
- This paper proposes a novel diffusion-based method for predicting future hand trajectories and object affordances in human egocentric videos.
- The key innovation is using a denoising diffusion model to forecast future latent interaction features, which are then used to predict hand movements and object interactions.
- The approach aims to address limitations of existing autoregressive methods, which can accumulate errors over time and do not fully account for the effects of camera egomotion.
Plain English Explanation
The paper focuses on understanding how humans interact with objects in the real world, which is important for applications like service robots and virtual/augmented reality. Recent research has tried to predict future hand movements and object interactions by analyzing first-person videos of people's hands.
However, the current methods have some drawbacks. They often use an autoregressive approach, where they predict each step in the sequence one-by-one. This can lead to errors building up over time. The existing work also doesn't fully consider how the camera wearer's own movements can affect the predictions.
To address these issues, the researchers propose a new "diffusion-based" method, called Diff-IP2D. Instead of predicting the future step-by-step, Diff-IP2D generates the entire sequence of future hand-object interactions all at once. It does this by transforming the video frames into a more abstract "latent feature space," and then using a special type of machine learning model called a "denoising diffusion" model to predict the future latent features.
Importantly, Diff-IP2D also incorporates information about the camera wearer's motion to improve the accuracy of the predictions. The experiments show this new approach significantly outperforms previous methods on benchmark tests.
The key advantage of Diff-IP2D is that it can generate more coherent and accurate predictions of future hand-object interactions, which could be very useful for applications like robotics and augmented reality. The researchers plan to release the code for Diff-IP2D to help advance research in this area.
Technical Explanation
The paper proposes a novel "diffusion-based interaction prediction" method called Diff-IP2D to forecast future hand trajectories and object affordances from human egocentric videos.
Unlike previous autoregressive approaches that predict the future sequence one step at a time, Diff-IP2D uses a denoising diffusion model to generate the entire future sequence of latent interaction features in a single, non-autoregressive pass. This denoising diffusion process iteratively refines the latent features, starting from a noisy initialization and progressively removing the noise to obtain the final prediction.
Importantly, Diff-IP2D also integrates motion features from the camera wearer's egomotion to condition the denoising process. This allows the model to better account for how the viewer's own movements affect the observed hand-object interactions.
The experiments demonstrate that Diff-IP2D significantly outperforms state-of-the-art baselines on both standard evaluation metrics and a new protocol proposed by the authors. This highlights the effectiveness of the generative diffusion paradigm for 2D hand-object interaction prediction compared to previous autoregressive methods.
Critical Analysis
The paper makes a compelling case for the advantages of a diffusion-based approach over autoregressive methods for predicting future hand-object interactions. The integration of camera egomotion information is a particularly novel and important contribution, as it addresses a key limitation of prior work.
However, the paper does not discuss certain potential limitations or caveats of the proposed Diff-IP2D method. For example, it is unclear how the method would scale to longer-term predictions or how robust it would be to occlusions or other challenging real-world scenarios. Additionally, the computational efficiency and training requirements of the diffusion model are not extensively explored.
Further research could also investigate the interpretability of the learned latent representations and how they relate to the underlying hand-object interaction mechanisms. Exploring ways to leverage individual information or text guidance could also potentially enhance the predictions.
Overall, the paper presents a novel and promising approach to a challenging problem. However, as with any research, there are avenues for future work to further improve the generalization and robustness of the proposed method.
Conclusion
This paper introduces Diff-IP2D, a novel diffusion-based method for predicting future hand trajectories and object affordances from human egocentric videos. By using a denoising diffusion model to generate the entire future sequence in a non-autoregressive manner, and by incorporating camera egomotion information, Diff-IP2D outperforms previous state-of-the-art approaches.
The key contribution of this work is demonstrating the effectiveness of generative diffusion models for this type of interaction prediction task. This could have important implications for applications in service robotics, extended reality, and other domains that require understanding and anticipating human hand-object interactions. The researchers plan to release the Diff-IP2D code to further advance research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
0
Diff-IP2D: Diffusion-Based Hand-Object Interaction Prediction on Egocentric Videos
Junyi Ma, Jingyi Xu, Xieyuanli Chen, Hesheng Wang
Understanding how humans would behave during hand-object interaction is vital for applications in service robot manipulation and extended reality. To achieve this, some recent works have been proposed to simultaneously forecast hand trajectories and object affordances on human egocentric videos. The joint prediction serves as a comprehensive representation of future hand-object interactions in 2D space, indicating potential human motion and motivation. However, the existing approaches mostly adopt the autoregressive paradigm for unidirectional prediction, which lacks mutual constraints within the holistic future sequence, and accumulates errors along the time axis. Meanwhile, these works basically overlook the effect of camera egomotion on first-person view predictions. To address these limitations, we propose a novel diffusion-based interaction prediction method, namely Diff-IP2D, to forecast future hand trajectories and object affordances concurrently in an iterative non-autoregressive manner. We transform the sequential 2D images into latent feature space and design a denoising diffusion model to predict future latent interaction features conditioned on past ones. Motion features are further integrated into the conditional denoising process to enable Diff-IP2D aware of the camera wearer's dynamics for more accurate interaction prediction. Extensive experiments demonstrate that our method significantly outperforms the state-of-the-art baselines on both the off-the-shelf metrics and our newly proposed evaluation protocol. This highlights the efficacy of leveraging a generative paradigm for 2D hand-object interaction prediction. The code of Diff-IP2D will be released at https://github.com/IRMVLab/Diff-IP2D.
Read more9/6/2024

0
MADiff: Motion-Aware Mamba Diffusion Models for Hand Trajectory Prediction on Egocentric Videos
Junyi Ma, Xieyuanli Chen, Wentao Bao, Jingyi Xu, Hesheng Wang
Understanding human intentions and actions through egocentric videos is important on the path to embodied artificial intelligence. As a branch of egocentric vision techniques, hand trajectory prediction plays a vital role in comprehending human motion patterns, benefiting downstream tasks in extended reality and robot manipulation. However, capturing high-level human intentions consistent with reasonable temporal causality is challenging when only egocentric videos are available. This difficulty is exacerbated under camera egomotion interference and the absence of affordance labels to explicitly guide the optimization of hand waypoint distribution. In this work, we propose a novel hand trajectory prediction method dubbed MADiff, which forecasts future hand waypoints with diffusion models. The devised denoising operation in the latent space is achieved by our proposed motion-aware Mamba, where the camera wearer's egomotion is integrated to achieve motion-driven selective scan (MDSS). To discern the relationship between hands and scenarios without explicit affordance supervision, we leverage a foundation model that fuses visual and language features to capture high-level semantics from video clips. Comprehensive experiments conducted on five public datasets with the existing and our proposed new evaluation metrics demonstrate that MADiff predicts comparably reasonable hand trajectories compared to the state-of-the-art baselines, and achieves real-time performance. We will release our code and pretrained models of MADiff at the project page: https://irmvlab.github.io/madiff.github.io.
Read more9/5/2024

0
ManiDext: Hand-Object Manipulation Synthesis via Continuous Correspondence Embeddings and Residual-Guided Diffusion
Jiajun Zhang, Yuxiang Zhang, Liang An, Mengcheng Li, Hongwen Zhang, Zonghai Hu, Yebin Liu
Dynamic and dexterous manipulation of objects presents a complex challenge, requiring the synchronization of hand motions with the trajectories of objects to achieve seamless and physically plausible interactions. In this work, we introduce ManiDext, a unified hierarchical diffusion-based framework for generating hand manipulation and grasp poses based on 3D object trajectories. Our key insight is that accurately modeling the contact correspondences between objects and hands during interactions is crucial. Therefore, we propose a continuous correspondence embedding representation that specifies detailed hand correspondences at the vertex level between the object and the hand. This embedding is optimized directly on the hand mesh in a self-supervised manner, with the distance between embeddings reflecting the geodesic distance. Our framework first generates contact maps and correspondence embeddings on the object's surface. Based on these fine-grained correspondences, we introduce a novel approach that integrates the iterative refinement process into the diffusion process during the second stage of hand pose generation. At each step of the denoising process, we incorporate the current hand pose residual as a refinement target into the network, guiding the network to correct inaccurate hand poses. Introducing residuals into each denoising step inherently aligns with traditional optimization process, effectively merging generation and refinement into a single unified framework. Extensive experiments demonstrate that our approach can generate physically plausible and highly realistic motions for various tasks, including single and bimanual hand grasping as well as manipulating both rigid and articulated objects. Code will be available for research purposes.
Read more9/17/2024
0
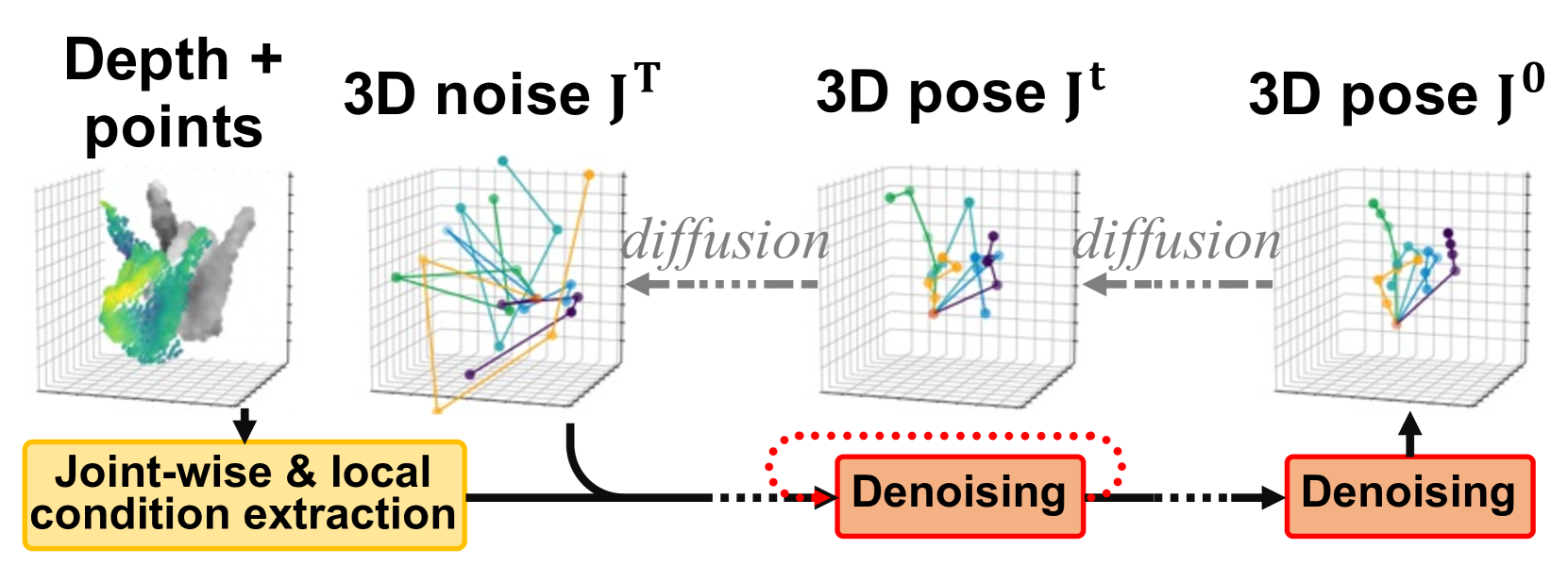
HandDiff: 3D Hand Pose Estimation with Diffusion on Image-Point Cloud
Wencan Cheng, Hao Tang, Luc Van Gool, Jong Hwan Ko
Extracting keypoint locations from input hand frames, known as 3D hand pose estimation, is a critical task in various human-computer interaction applications. Essentially, the 3D hand pose estimation can be regarded as a 3D point subset generative problem conditioned on input frames. Thanks to the recent significant progress on diffusion-based generative models, hand pose estimation can also benefit from the diffusion model to estimate keypoint locations with high quality. However, directly deploying the existing diffusion models to solve hand pose estimation is non-trivial, since they cannot achieve the complex permutation mapping and precise localization. Based on this motivation, this paper proposes HandDiff, a diffusion-based hand pose estimation model that iteratively denoises accurate hand pose conditioned on hand-shaped image-point clouds. In order to recover keypoint permutation and accurate location, we further introduce joint-wise condition and local detail condition. Experimental results demonstrate that the proposed HandDiff significantly outperforms the existing approaches on four challenging hand pose benchmark datasets. Codes and pre-trained models are publicly available at https://github.com/cwc1260/HandDiff.
Read more4/5/2024