Diff-Reg v1: Diffusion Matching Model for Registration Problem
2403.19919
0
0

Abstract
Establishing reliable correspondences is essential for registration tasks such as 3D and 2D3D registration. Existing methods commonly leverage geometric or semantic point features to generate potential correspondences. However, these features may face challenges such as large deformation, scale inconsistency, and ambiguous matching problems (e.g., symmetry). Additionally, many previous methods, which rely on single-pass prediction, may struggle with local minima in complex scenarios. To mitigate these challenges, we introduce a diffusion matching model for robust correspondence construction. Our approach treats correspondence estimation as a denoising diffusion process within the doubly stochastic matrix space, which gradually denoises (refines) a doubly stochastic matching matrix to the ground-truth one for high-quality correspondence estimation. It involves a forward diffusion process that gradually introduces Gaussian noise into the ground truth matching matrix and a reverse denoising process that iteratively refines the noisy matching matrix. In particular, the feature extraction from the backbone occurs only once during the inference phase. Our lightweight denoising module utilizes the same feature at each reverse sampling step. Evaluation of our method on both 3D and 2D3D registration tasks confirms its effectiveness.
Create account to get full access
Overview
- This paper proposes a new diffusion-based model called Diff-Reg v1 for solving image registration problems, such as aligning 2D and 3D medical scans.
- The model uses a diffusion process to learn an optimal matching between input images, allowing for flexible and robust registration.
- Key contributions include a novel diffusion-based objective function and an efficient training and inference procedure.
Plain English Explanation
The core idea behind Diff-Reg v1 is to treat image registration as a "diffusion" process. Imagine you have two images that you want to perfectly align with each other. Rather than trying to directly find the best alignment, the Diff-Reg model starts by "diffusing" or blurring the images. This makes the details less sharp but also makes it easier to find a rough alignment between the two.
The model then gradually refines this alignment, slowly "un-diffusing" the images until they are perfectly aligned. This diffusion-based approach has several advantages. First, it is more robust to noise and variations in the input images compared to traditional registration methods. Second, it can handle complex transformations like 3D-to-2D alignment, which are challenging for other techniques.
The paper introduces a new mathematical formulation to enable this diffusion-based registration. The key innovation is modeling the alignment as a flow through a special "doubly stochastic matrix space." This allows the model to efficiently learn the optimal diffusion path between the input images.
Overall, Diff-Reg v1 provides a flexible and powerful framework for aligning images, with potential applications in medical imaging, computer vision, and beyond.
Technical Explanation
Diff-Reg v1 frames the image registration problem as learning an optimal transport plan between the input images, modeled as probability distributions. The core innovation is to parameterize this transport plan using a diffusion process in a doubly stochastic matrix space.
Specifically, the model defines a diffusion operator that gradually transforms one input image into the other. This diffusion is governed by a learned transition matrix that satisfies the doubly stochastic property - each row and column sums to 1. This ensures the diffusion preserves the total mass (i.e., the images remain properly normalized) throughout the process.
The model is trained end-to-end to minimize a diffusion-based objective function that encourages the learned diffusion to align the input images. This objective balances semantic similarity (e.g., ensuring corresponding anatomical structures are aligned) and spatial regularity (e.g., penalizing excessive deformations).
Experimental results on 2D-3D and 3D-3D registration tasks demonstrate the effectiveness of Diff-Reg v1 compared to prior art. The diffusion-based approach enables robust alignment even with significant initial misalignment or modality differences between the input images.
Critical Analysis
A key strength of Diff-Reg v1 is its flexibility in handling complex registration tasks, such as aligning 2D and 3D medical images. The diffusion-based formulation provides a principled way to learn the optimal alignment, going beyond traditional approaches that may struggle with large deformations or cross-modality inputs.
That said, the paper does not provide a thorough analysis of the model's limitations. For example, it is unclear how Diff-Reg v1 would perform on highly deformable or non-rigid registration problems, where the underlying assumption of a doubly stochastic transformation may not hold.
Additionally, the training and inference procedures, while efficient, could potentially be made more scalable. The paper mentions that the current implementation may struggle with very high-resolution 3D inputs, an important consideration for real-world deployment.
Further research could also explore ways to incorporate additional domain knowledge or constraints into the diffusion process, perhaps by learning richer parameterizations of the doubly stochastic transition matrix. This could lead to even more accurate and interpretable registration results.
Conclusion
Diff-Reg v1 presents a novel diffusion-based framework for image registration that offers several advantages over traditional techniques. By modeling the alignment as an optimal transport problem in a doubly stochastic matrix space, the model can handle complex transformations and cross-modality inputs with impressive robustness.
While the paper demonstrates strong empirical performance, further research is needed to fully explore the model's capabilities and limitations. Expanding the scope of the diffusion process and improving scalability could unlock even broader applications in medical imaging, computer vision, and beyond.
Overall, Diff-Reg v1 represents an intriguing and promising approach to the long-standing problem of image registration, with the potential to drive new advances in this important field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
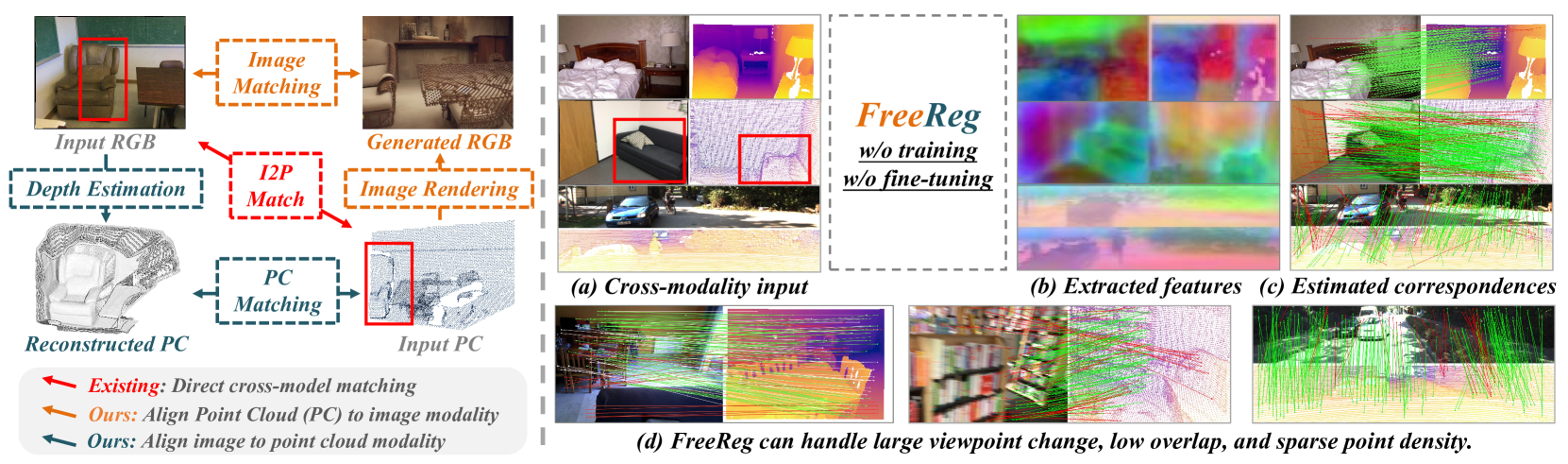
FreeReg: Image-to-Point Cloud Registration Leveraging Pretrained Diffusion Models and Monocular Depth Estimators
Haiping Wang, Yuan Liu, Bing Wang, Yujing Sun, Zhen Dong, Wenping Wang, Bisheng Yang
0
0
Matching cross-modality features between images and point clouds is a fundamental problem for image-to-point cloud registration. However, due to the modality difference between images and points, it is difficult to learn robust and discriminative cross-modality features by existing metric learning methods for feature matching. Instead of applying metric learning on cross-modality data, we propose to unify the modality between images and point clouds by pretrained large-scale models first, and then establish robust correspondence within the same modality. We show that the intermediate features, called diffusion features, extracted by depth-to-image diffusion models are semantically consistent between images and point clouds, which enables the building of coarse but robust cross-modality correspondences. We further extract geometric features on depth maps produced by the monocular depth estimator. By matching such geometric features, we significantly improve the accuracy of the coarse correspondences produced by diffusion features. Extensive experiments demonstrate that without any task-specific training, direct utilization of both features produces accurate image-to-point cloud registration. On three public indoor and outdoor benchmarks, the proposed method averagely achieves a 20.6 percent improvement in Inlier Ratio, a three-fold higher Inlier Number, and a 48.6 percent improvement in Registration Recall than existing state-of-the-arts.
4/16/2024
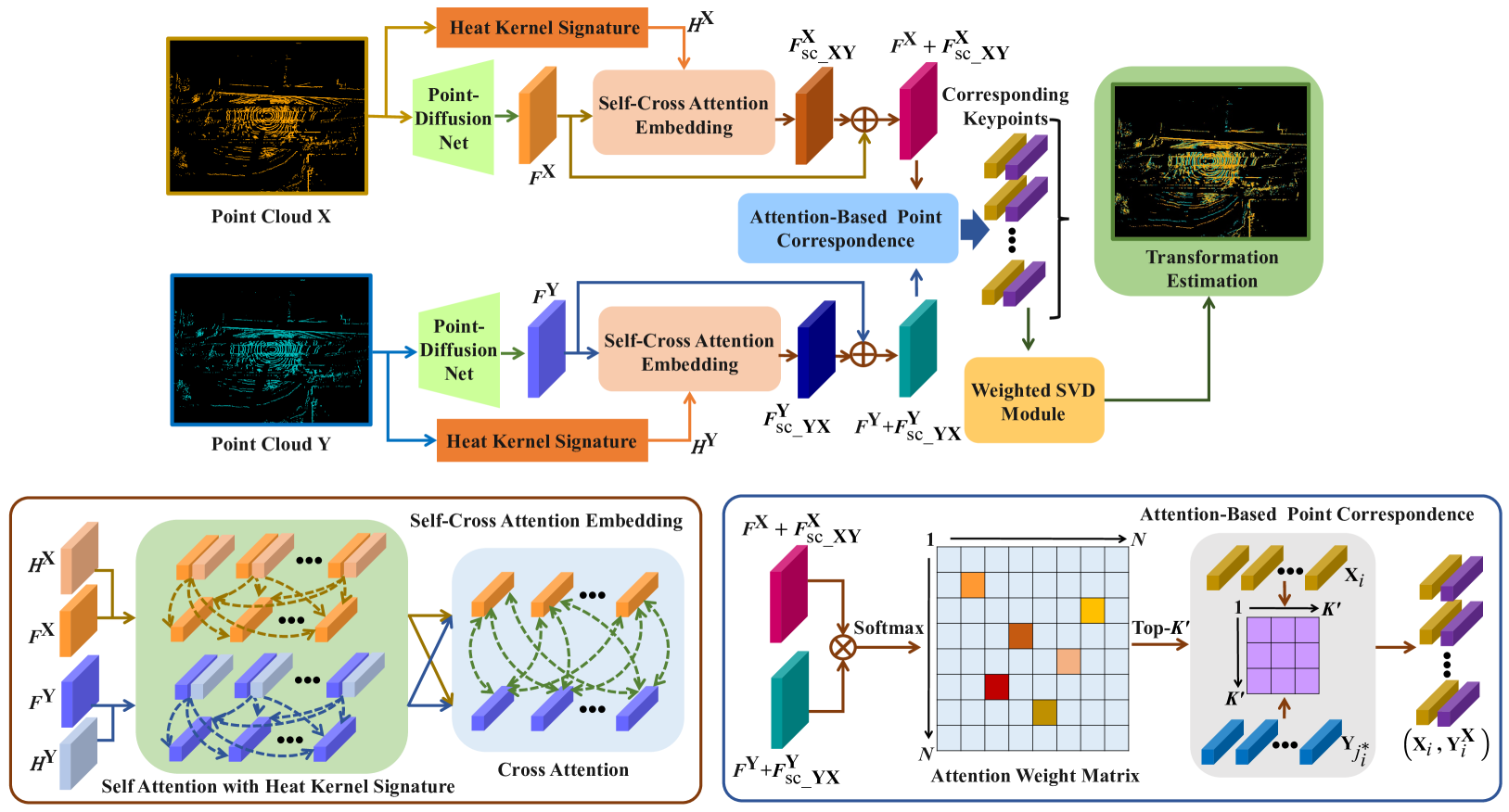
PointDifformer: Robust Point Cloud Registration With Neural Diffusion and Transformer
Rui She, Qiyu Kang, Sijie Wang, Wee Peng Tay, Kai Zhao, Yang Song, Tianyu Geng, Yi Xu, Diego Navarro Navarro, Andreas Hartmannsgruber
0
0
Point cloud registration is a fundamental technique in 3-D computer vision with applications in graphics, autonomous driving, and robotics. However, registration tasks under challenging conditions, under which noise or perturbations are prevalent, can be difficult. We propose a robust point cloud registration approach that leverages graph neural partial differential equations (PDEs) and heat kernel signatures. Our method first uses graph neural PDE modules to extract high dimensional features from point clouds by aggregating information from the 3-D point neighborhood, thereby enhancing the robustness of the feature representations. Then, we incorporate heat kernel signatures into an attention mechanism to efficiently obtain corresponding keypoints. Finally, a singular value decomposition (SVD) module with learnable weights is used to predict the transformation between two point clouds. Empirical experiments on a 3-D point cloud dataset demonstrate that our approach not only achieves state-of-the-art performance for point cloud registration but also exhibits better robustness to additive noise or 3-D shape perturbations.
4/23/2024

Diffusion Model With Optimal Covariance Matching
Zijing Ou, Mingtian Zhang, Andi Zhang, Tim Z. Xiao, Yingzhen Li, David Barber
0
0
The probabilistic diffusion model has become highly effective across various domains. Typically, sampling from a diffusion model involves using a denoising distribution characterized by a Gaussian with a learned mean and either fixed or learned covariances. In this paper, we leverage the recently proposed full covariance moment matching technique and introduce a novel method for learning covariances. Unlike traditional data-driven covariance approximation approaches, our method involves directly regressing the optimal analytic covariance using a new, unbiased objective named Optimal Covariance Matching (OCM). This approach can significantly reduce the approximation error in covariance prediction. We demonstrate how our method can substantially enhance the sampling efficiency of both Markovian (DDPM) and non-Markovian (DDIM) diffusion model families.
6/18/2024
🏋️
Diffusion Hyperfeatures: Searching Through Time and Space for Semantic Correspondence
Grace Luo, Lisa Dunlap, Dong Huk Park, Aleksander Holynski, Trevor Darrell
0
0
Diffusion models have been shown to be capable of generating high-quality images, suggesting that they could contain meaningful internal representations. Unfortunately, the feature maps that encode a diffusion model's internal information are spread not only over layers of the network, but also over diffusion timesteps, making it challenging to extract useful descriptors. We propose Diffusion Hyperfeatures, a framework for consolidating multi-scale and multi-timestep feature maps into per-pixel feature descriptors that can be used for downstream tasks. These descriptors can be extracted for both synthetic and real images using the generation and inversion processes. We evaluate the utility of our Diffusion Hyperfeatures on the task of semantic keypoint correspondence: our method achieves superior performance on the SPair-71k real image benchmark. We also demonstrate that our method is flexible and transferable: our feature aggregation network trained on the inversion features of real image pairs can be used on the generation features of synthetic image pairs with unseen objects and compositions. Our code is available at https://diffusion-hyperfeatures.github.io.
4/3/2024