PointDifformer: Robust Point Cloud Registration With Neural Diffusion and Transformer

0
Sign in to get full access
Overview
- This paper presents PointDifformer, a novel approach for robust point cloud registration that combines neural diffusion and transformer architectures.
- The method leverages the strengths of both techniques to handle challenging cases like partial overlap, noise, and outliers in point cloud data.
- PointDifformer outperforms state-of-the-art point cloud registration methods on several benchmark datasets.
Plain English Explanation
Point cloud registration is the process of aligning two 3D point clouds, often captured from different perspectives, to create a unified representation. This is an important task in various applications, such as 3D reconstruction, robot navigation, and augmented reality.
However, real-world point cloud data can be challenging to work with due to factors like partial overlap between the clouds, noise, and outliers (points that don't belong to the object of interest). Traditional registration methods may struggle to handle these complexities.
The PointDifformer approach aims to address these challenges by combining two powerful techniques: neural diffusion and transformer architectures. Neural diffusion is a method that uses heat diffusion to learn a representation of the point cloud, while transformers are a type of neural network that can capture long-range dependencies in data.
By integrating these two approaches, PointDifformer can effectively handle partial overlap, noise, and outliers in point cloud data, resulting in more robust and accurate registration. The method outperforms other state-of-the-art point cloud registration techniques on standard benchmark datasets, demonstrating its potential to improve 3D reconstruction, object dynamics modeling, and other applications that rely on accurate point cloud alignment.
Technical Explanation
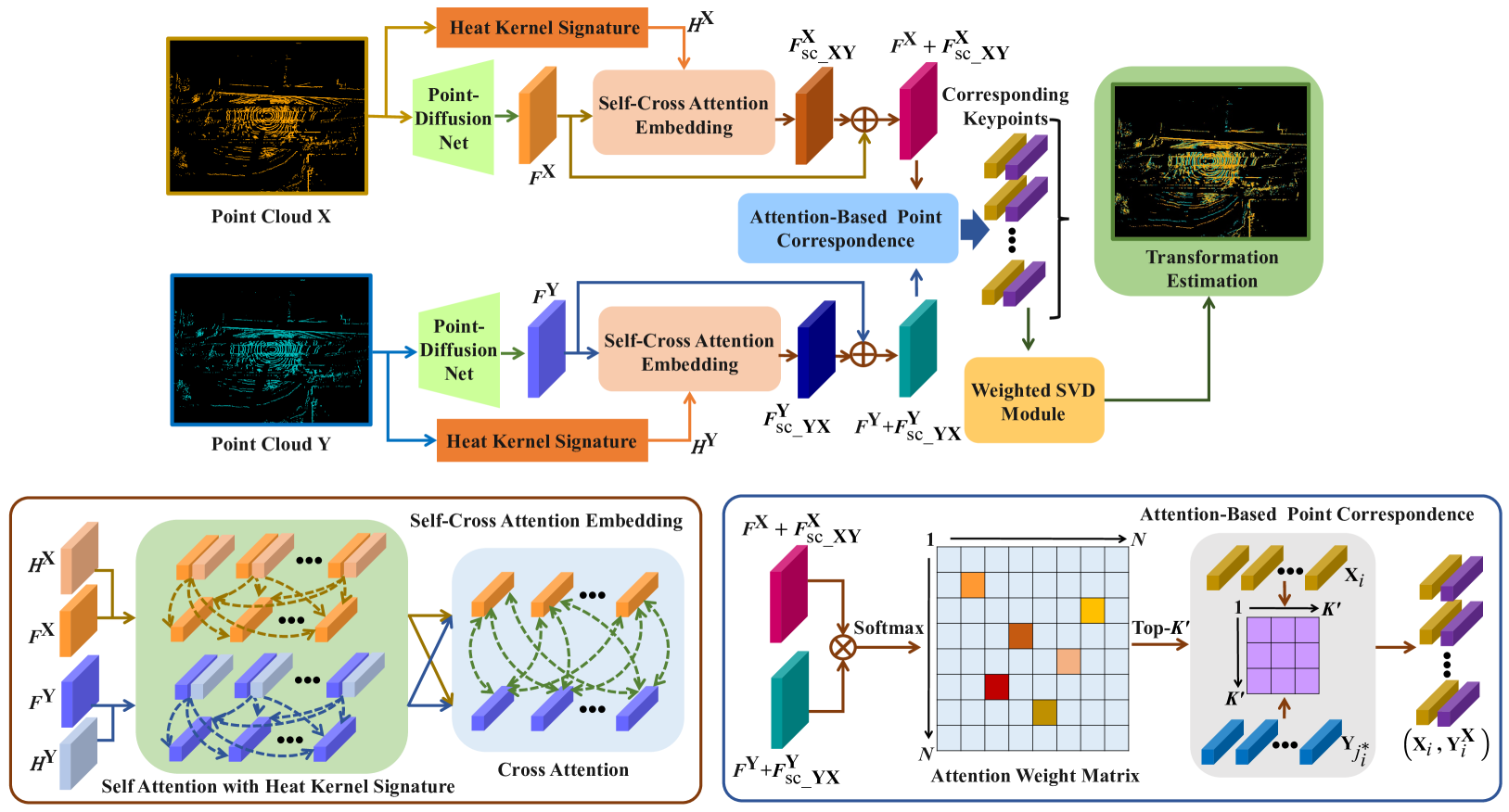
The PointDifformer architecture consists of two main components:
-
Neural Diffusion Module: This module uses heat kernel signature to learn a representation of the input point clouds, capturing their geometric and topological properties. The diffusion process helps the model handle partial overlap, noise, and outliers.
-
Transformer Module: This component takes the diffusion-based features and uses a transformer network to learn long-range dependencies in the point cloud data. This helps the model better capture the overall structure and shape of the objects, further improving the registration performance.
The PointDifformer model is trained end-to-end using a combination of point-to-point and point-to-plane losses, which encourage the model to align the point clouds both locally and globally. The model is evaluated on several benchmark datasets, including the 3DMatch and ETH datasets, demonstrating state-of-the-art performance in terms of registration accuracy and robustness to challenging conditions.
Critical Analysis
The paper provides a thorough evaluation of PointDifformer's performance, including comparisons to other popular point cloud registration methods. The results show that the proposed approach outperforms existing techniques, particularly in cases with partial overlap, noise, and outliers.
However, the paper does not address several potential limitations and areas for further research. For example, the computational complexity of the model is not discussed, which could be a concern for real-time applications or large-scale point cloud processing. Additionally, the paper does not explore the model's sensitivity to hyperparameter tuning or the impact of the specific architectural choices on the overall performance.
Further research could investigate ways to optimize the PointDifformer model for efficiency, explore the model's generalization capabilities to different types of point cloud data, and compare its performance to other recent advancements in the field of point cloud registration.
Conclusion
The PointDifformer paper presents a novel and effective approach for robust point cloud registration. By leveraging the strengths of neural diffusion and transformer architectures, the method can handle challenging real-world conditions, such as partial overlap, noise, and outliers, and outperform state-of-the-art registration techniques.
The proposed approach has the potential to significantly improve the accuracy and reliability of 3D reconstruction, robot navigation, and other applications that rely on accurate point cloud alignment. As the field of point cloud processing continues to evolve, the insights and techniques introduced in this paper may inspire further advancements and serve as a foundation for future research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PointDifformer: Robust Point Cloud Registration With Neural Diffusion and Transformer
Rui She, Qiyu Kang, Sijie Wang, Wee Peng Tay, Kai Zhao, Yang Song, Tianyu Geng, Yi Xu, Diego Navarro Navarro, Andreas Hartmannsgruber
Point cloud registration is a fundamental technique in 3-D computer vision with applications in graphics, autonomous driving, and robotics. However, registration tasks under challenging conditions, under which noise or perturbations are prevalent, can be difficult. We propose a robust point cloud registration approach that leverages graph neural partial differential equations (PDEs) and heat kernel signatures. Our method first uses graph neural PDE modules to extract high dimensional features from point clouds by aggregating information from the 3-D point neighborhood, thereby enhancing the robustness of the feature representations. Then, we incorporate heat kernel signatures into an attention mechanism to efficiently obtain corresponding keypoints. Finally, a singular value decomposition (SVD) module with learnable weights is used to predict the transformation between two point clouds. Empirical experiments on a 3-D point cloud dataset demonstrate that our approach not only achieves state-of-the-art performance for point cloud registration but also exhibits better robustness to additive noise or 3-D shape perturbations.
Read more4/23/2024
0
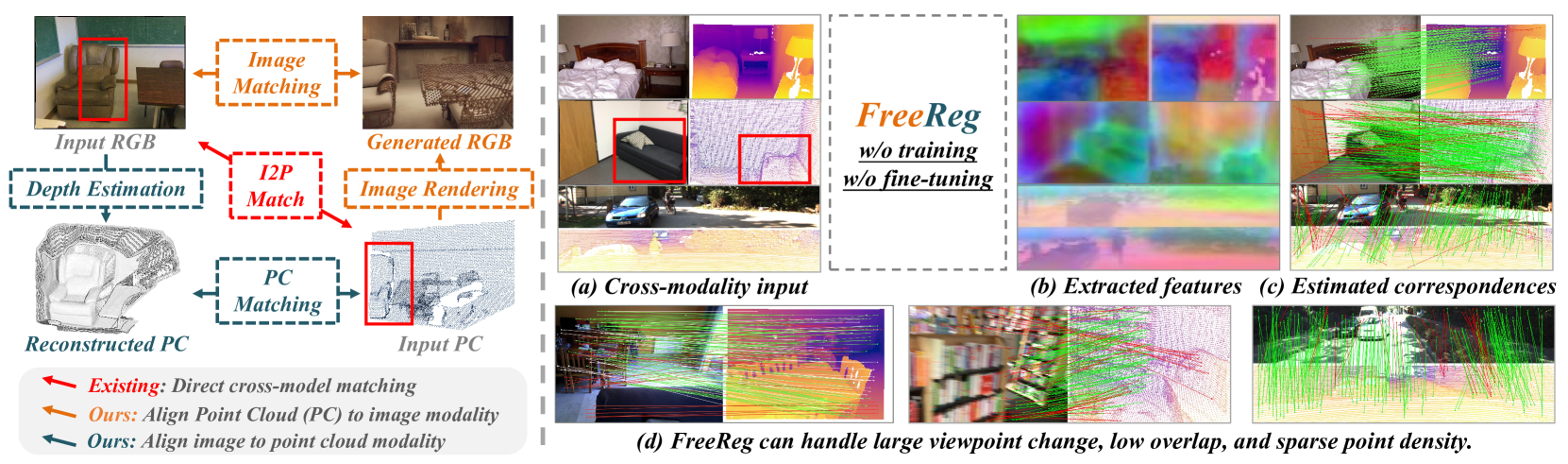
FreeReg: Image-to-Point Cloud Registration Leveraging Pretrained Diffusion Models and Monocular Depth Estimators
Haiping Wang, Yuan Liu, Bing Wang, Yujing Sun, Zhen Dong, Wenping Wang, Bisheng Yang
Matching cross-modality features between images and point clouds is a fundamental problem for image-to-point cloud registration. However, due to the modality difference between images and points, it is difficult to learn robust and discriminative cross-modality features by existing metric learning methods for feature matching. Instead of applying metric learning on cross-modality data, we propose to unify the modality between images and point clouds by pretrained large-scale models first, and then establish robust correspondence within the same modality. We show that the intermediate features, called diffusion features, extracted by depth-to-image diffusion models are semantically consistent between images and point clouds, which enables the building of coarse but robust cross-modality correspondences. We further extract geometric features on depth maps produced by the monocular depth estimator. By matching such geometric features, we significantly improve the accuracy of the coarse correspondences produced by diffusion features. Extensive experiments demonstrate that without any task-specific training, direct utilization of both features produces accurate image-to-point cloud registration. On three public indoor and outdoor benchmarks, the proposed method averagely achieves a 20.6 percent improvement in Inlier Ratio, a three-fold higher Inlier Number, and a 48.6 percent improvement in Registration Recall than existing state-of-the-arts.
Read more4/16/2024

0
SE3ET: SE(3)-Equivariant Transformer for Low-Overlap Point Cloud Registration
Chien Erh Lin, Minghan Zhu, Maani Ghaffari
Partial point cloud registration is a challenging problem in robotics, especially when the robot undergoes a large transformation, causing a significant initial pose error and a low overlap between measurements. This work proposes exploiting equivariant learning from 3D point clouds to improve registration robustness. We propose SE3ET, an SE(3)-equivariant registration framework that employs equivariant point convolution and equivariant transformer designs to learn expressive and robust geometric features. We tested the proposed registration method on indoor and outdoor benchmarks where the point clouds are under arbitrary transformations and low overlapping ratios. We also provide generalization tests and run-time performance.
Read more7/25/2024

0
A Comprehensive Survey and Taxonomy on Point Cloud Registration Based on Deep Learning
Yu-Xin Zhang, Jie Gui, Xiaofeng Cong, Xin Gong, Wenbing Tao
Point cloud registration (PCR) involves determining a rigid transformation that aligns one point cloud to another. Despite the plethora of outstanding deep learning (DL)-based registration methods proposed, comprehensive and systematic studies on DL-based PCR techniques are still lacking. In this paper, we present a comprehensive survey and taxonomy of recently proposed PCR methods. Firstly, we conduct a taxonomy of commonly utilized datasets and evaluation metrics. Secondly, we classify the existing research into two main categories: supervised and unsupervised registration, providing insights into the core concepts of various influential PCR models. Finally, we highlight open challenges and potential directions for future research. A curated collection of valuable resources is made available at https://github.com/yxzhang15/PCR.
Read more7/8/2024