Diff-A-Riff: Musical Accompaniment Co-creation via Latent Diffusion Models
2406.08384
0
0
🤷
Abstract
Recent advancements in deep generative models present new opportunities for music production but also pose challenges, such as high computational demands and limited audio quality. Moreover, current systems frequently rely solely on text input and typically focus on producing complete musical pieces, which is incompatible with existing workflows in music production. To address these issues, we introduce Diff-A-Riff, a Latent Diffusion Model designed to generate high-quality instrumental accompaniments adaptable to any musical context. This model offers control through either audio references, text prompts, or both, and produces 48kHz pseudo-stereo audio while significantly reducing inference time and memory usage. We demonstrate the model's capabilities through objective metrics and subjective listening tests, with extensive examples available on the accompanying website: sonycslparis.github.io/diffariff-companion/
Create account to get full access
Overview
- Recent advancements in deep generative models have created new possibilities for music production, but also present challenges such as high computational demands and limited audio quality.
- Current systems often rely solely on text input and focus on producing complete musical pieces, which is incompatible with existing workflows in music production.
- To address these issues, the researchers introduce Diff-A-Riff, a Latent Diffusion Model designed to generate high-quality instrumental accompaniments that can be adapted to any musical context.
Plain English Explanation
Deep learning models have become powerful tools for generating music, but they often come with drawbacks. They can be resource-intensive, producing low-quality audio, and they may not fit well with how musicians actually work. Diff-A-Riff aims to solve these problems by creating an AI that can generate high-quality background music that can be easily incorporated into a composer's workflow.
The key idea is to focus on generating accompaniment tracks, rather than complete musical pieces. This allows the model to produce more realistic and adaptable audio that can be combined with a musician's own compositions. The model also offers flexibility, letting users guide the generation process through either audio references, text prompts, or a combination of both.
Importantly, the researchers have designed Diff-A-Riff to run efficiently, with faster inference times and lower memory usage than previous music generation systems. This makes it more practical for real-world music production.
Technical Explanation
The Diff-A-Riff model is built upon the Latent Diffusion architecture, which has been shown to be effective for tasks like video background music generation and text-to-music alignment. The researchers have adapted this approach to focus specifically on generating high-quality instrumental accompaniments.
The model takes either an audio reference, text prompt, or a combination of both as input. It then uses a diffusion-based process to generate a 48kHz pseudo-stereo audio output that can be seamlessly integrated into a musician's existing work. Importantly, this process is designed to be computationally efficient, with faster inference times and lower memory usage than previous music generation systems.
The researchers evaluate the model's performance through both objective metrics and subjective listening tests, demonstrating its ability to produce coherent and adaptable accompaniments. They provide extensive examples on the accompanying website for users to explore.
Critical Analysis
The Diff-A-Riff model addresses several important limitations of existing music generation systems, such as their focus on producing complete musical pieces and their high computational demands. By focusing on generating accompaniments rather than full compositions, the model is able to produce more flexible and realistic audio that can be easily incorporated into a musician's workflow.
However, the paper does not provide a detailed analysis of the model's limitations or potential issues. For example, it is unclear how the model would handle more complex musical structures or how it would perform in genres beyond the examples provided. Additionally, the researchers do not discuss the potential ethical implications of AI-generated music, such as concerns around plagiarism or the displacement of human musicians.
Despite these gaps, the Diff-A-Riff research represents an important step forward in making AI-generated music more practical and accessible for real-world music production. As the field of text-to-music editing and audio editing with diffusion models continues to evolve, it will be important for researchers to carefully consider the implications and limitations of these technologies.
Conclusion
The Diff-A-Riff model represents a significant advancement in the field of AI-generated music. By focusing on the generation of high-quality instrumental accompaniments, the researchers have created a system that is more compatible with existing music production workflows and can be easily integrated into a composer's creative process.
The model's ability to generate 48kHz pseudo-stereo audio while maintaining computational efficiency is particularly impressive and suggests that AI-generated music is becoming increasingly viable for real-world use cases. As the technology continues to evolve, it will be crucial for researchers and developers to carefully consider the ethical implications and potential limitations of these tools, ensuring that they are used in a responsible and meaningful way to support and empower human musicians, rather than replace them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Long-form music generation with latent diffusion
Zach Evans, Julian D. Parker, CJ Carr, Zack Zukowski, Josiah Taylor, Jordi Pons
0
0
Audio-based generative models for music have seen great strides recently, but so far have not managed to produce full-length music tracks with coherent musical structure. We show that by training a generative model on long temporal contexts it is possible to produce long-form music of up to 4m45s. Our model consists of a diffusion-transformer operating on a highly downsampled continuous latent representation (latent rate of 21.5Hz). It obtains state-of-the-art generations according to metrics on audio quality and prompt alignment, and subjective tests reveal that it produces full-length music with coherent structure.
4/17/2024
🏋️
Subtractive Training for Music Stem Insertion using Latent Diffusion Models
Ivan Villa-Renteria, Mason L. Wang, Zachary Shah, Zhe Li, Soohyun Kim, Neelesh Ramachandran, Mert Pilanci
0
0
We present Subtractive Training, a simple and novel method for synthesizing individual musical instrument stems given other instruments as context. This method pairs a dataset of complete music mixes with 1) a variant of the dataset lacking a specific stem, and 2) LLM-generated instructions describing how the missing stem should be reintroduced. We then fine-tune a pretrained text-to-audio diffusion model to generate the missing instrument stem, guided by both the existing stems and the text instruction. Our results demonstrate Subtractive Training's efficacy in creating authentic drum stems that seamlessly blend with the existing tracks. We also show that we can use the text instruction to control the generation of the inserted stem in terms of rhythm, dynamics, and genre, allowing us to modify the style of a single instrument in a full song while keeping the remaining instruments the same. Lastly, we extend this technique to MIDI formats, successfully generating compatible bass, drum, and guitar parts for incomplete arrangements.
6/28/2024
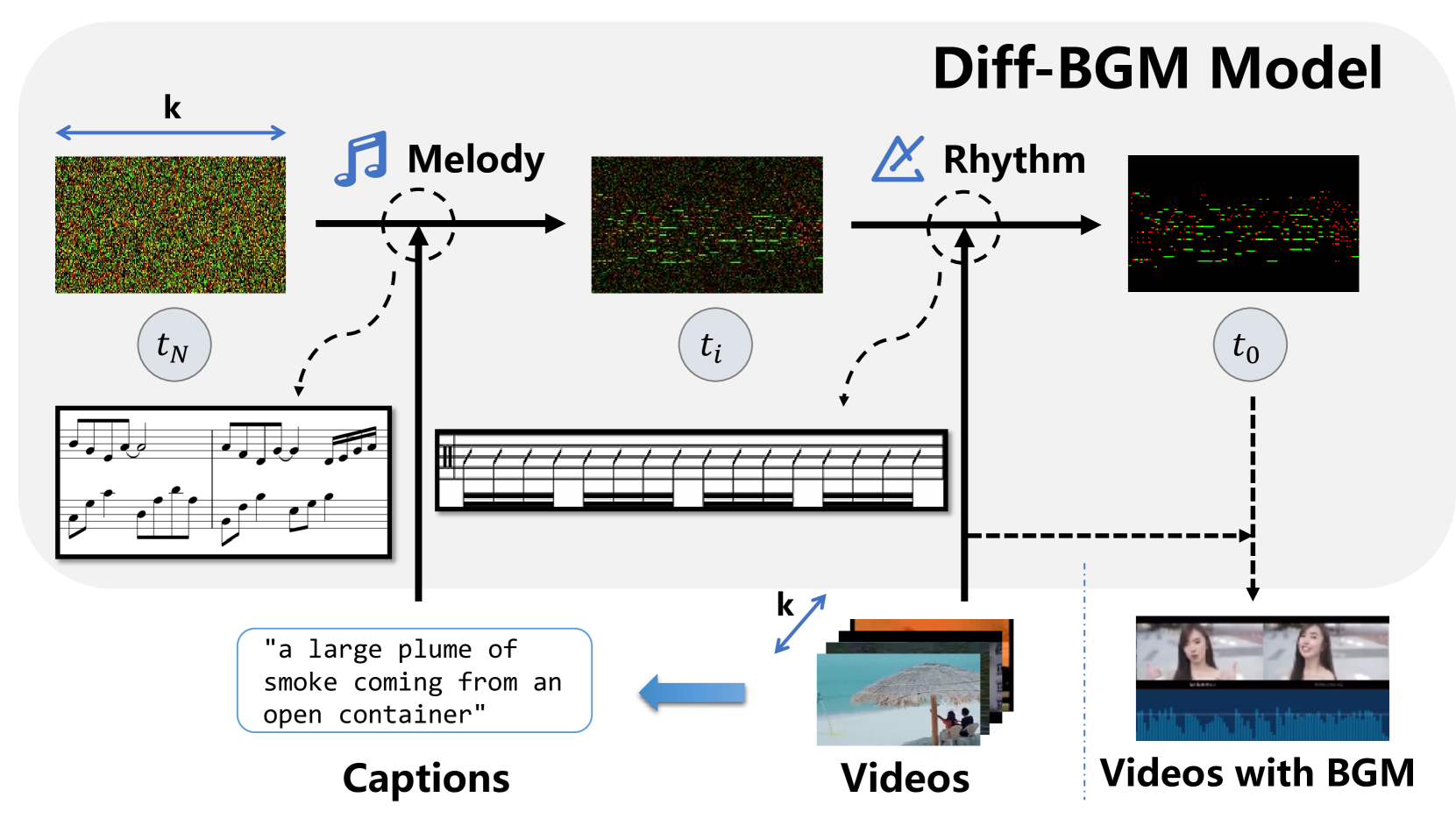
Diff-BGM: A Diffusion Model for Video Background Music Generation
Sizhe Li, Yiming Qin, Minghang Zheng, Xin Jin, Yang Liu
0
0
When editing a video, a piece of attractive background music is indispensable. However, video background music generation tasks face several challenges, for example, the lack of suitable training datasets, and the difficulties in flexibly controlling the music generation process and sequentially aligning the video and music. In this work, we first propose a high-quality music-video dataset BGM909 with detailed annotation and shot detection to provide multi-modal information about the video and music. We then present evaluation metrics to assess music quality, including music diversity and alignment between music and video with retrieval precision metrics. Finally, we propose the Diff-BGM framework to automatically generate the background music for a given video, which uses different signals to control different aspects of the music during the generation process, i.e., uses dynamic video features to control music rhythm and semantic features to control the melody and atmosphere. We propose to align the video and music sequentially by introducing a segment-aware cross-attention layer. Experiments verify the effectiveness of our proposed method. The code and models are available at https://github.com/sizhelee/Diff-BGM.
5/21/2024

Tango 2: Aligning Diffusion-based Text-to-Audio Generations through Direct Preference Optimization
Navonil Majumder, Chia-Yu Hung, Deepanway Ghosal, Wei-Ning Hsu, Rada Mihalcea, Soujanya Poria
0
0
Generative multimodal content is increasingly prevalent in much of the content creation arena, as it has the potential to allow artists and media personnel to create pre-production mockups by quickly bringing their ideas to life. The generation of audio from text prompts is an important aspect of such processes in the music and film industry. Many of the recent diffusion-based text-to-audio models focus on training increasingly sophisticated diffusion models on a large set of datasets of prompt-audio pairs. These models do not explicitly focus on the presence of concepts or events and their temporal ordering in the output audio with respect to the input prompt. Our hypothesis is focusing on how these aspects of audio generation could improve audio generation performance in the presence of limited data. As such, in this work, using an existing text-to-audio model Tango, we synthetically create a preference dataset where each prompt has a winner audio output and some loser audio outputs for the diffusion model to learn from. The loser outputs, in theory, have some concepts from the prompt missing or in an incorrect order. We fine-tune the publicly available Tango text-to-audio model using diffusion-DPO (direct preference optimization) loss on our preference dataset and show that it leads to improved audio output over Tango and AudioLDM2, in terms of both automatic- and manual-evaluation metrics.
4/17/2024