MusicMagus: Zero-Shot Text-to-Music Editing via Diffusion Models
2402.06178
0
0

Abstract
Recent advances in text-to-music generation models have opened new avenues in musical creativity. However, music generation usually involves iterative refinements, and how to edit the generated music remains a significant challenge. This paper introduces a novel approach to the editing of music generated by such models, enabling the modification of specific attributes, such as genre, mood and instrument, while maintaining other aspects unchanged. Our method transforms text editing to textit{latent space manipulation} while adding an extra constraint to enforce consistency. It seamlessly integrates with existing pretrained text-to-music diffusion models without requiring additional training. Experimental results demonstrate superior performance over both zero-shot and certain supervised baselines in style and timbre transfer evaluations. Additionally, we showcase the practical applicability of our approach in real-world music editing scenarios.
Create account to get full access
Overview
- This paper introduces MusicMagus, a novel zero-shot text-to-music editing system that uses diffusion models to generate and edit music based on textual prompts.
- The system allows users to create, manipulate, and refine musical compositions by providing natural language descriptions, without the need for musical expertise or prior training on specific music datasets.
- The paper presents the model architecture, training process, and experimental results, demonstrating the capabilities of MusicMagus in generating and editing music from text prompts.
Plain English Explanation
MusicMagus is a new way to create and edit music using just words. Normally, making music requires a lot of musical knowledge and training. But with MusicMagus, you can simply describe what kind of music you want, and the system will generate it for you.
The key innovation is the use of "diffusion models," which are a type of machine learning model that can generate and edit images, audio, and other types of data based on textual descriptions. In the case of MusicMagus, the diffusion model is trained to understand the relationship between text and music, allowing it to generate and modify musical compositions in response to natural language prompts.
For example, you could tell MusicMagus to "create a cheerful, upbeat piano melody" or "make the drums more intense and the melody more melancholic." The system would then generate or edit the music accordingly, without you needing to know anything about music theory or composition.
This zero-shot approach, where the system can work with any text prompt without requiring prior training on specific music datasets, is a key advantage of MusicMagus. It makes music creation and editing accessible to a much wider audience, empowering anyone to express their musical ideas through language.
The paper provides details on how the MusicMagus system works, including the model architecture and the training process. It also presents the results of experiments demonstrating the system's capabilities, showing that it can generate and edit music in a wide variety of styles and genres based on textual prompts.
Technical Explanation
The MusicMagus system is built on the foundation of diffusion models, a type of machine learning architecture that has shown great success in tasks like image generation and text-to-speech conversion. In the context of MusicMagus, the diffusion model is trained to generate and edit musical compositions based on textual prompts.
The key components of the MusicMagus architecture include:
- Diffusion Model: The core of the system, responsible for transforming text prompts into musical outputs. The diffusion model is trained using a combination of text-to-music alignment and zero-shot learning techniques.
- Text Encoder: Encodes the input text prompts into a latent representation that can be processed by the diffusion model.
- Music Decoder: Generates the final musical output based on the diffusion model's output, which can be in the form of MIDI or audio data.
The training process for MusicMagus involves several steps:
- Text-to-Music Alignment: The system is trained to align textual descriptions with corresponding musical compositions, building an understanding of the relationship between language and music.
- Zero-Shot Learning: The model is then trained to generate and edit music in a zero-shot manner, without requiring prior exposure to specific music datasets. This allows the system to work with a wide range of text prompts.
- Iterative Refinement: The generated music can be further refined and edited by providing additional text prompts, allowing users to gradually shape the musical output to their liking.
The experimental results presented in the paper demonstrate the impressive capabilities of MusicMagus. The system is able to generate and edit music across a variety of genres, styles, and instrumentation, all based on natural language descriptions. This suggests that MusicMagus could be a powerful tool for democratizing music creation and empowering a wider audience to express their musical ideas.
Critical Analysis
The MusicMagus system represents a significant advancement in the field of text-to-music generation and editing, but it is important to consider some potential limitations and areas for further research:
-
Dataset Bias: While the zero-shot approach allows MusicMagus to work with a wide range of text prompts, the system's performance may still be influenced by the underlying dataset used for training. Careful consideration of dataset diversity and representation is crucial to ensure the system's outputs are unbiased and inclusive.
-
Musical Coherence: The paper focuses on the system's ability to generate and edit music based on textual prompts, but it does not extensively evaluate the overall musical coherence and quality of the generated compositions. Further research is needed to assess the system's ability to maintain musical structure, harmony, and emotional expressiveness.
-
Evaluation Metrics: The paper relies on subjective human evaluations to assess the system's performance. While this provides valuable insights, more objective and quantifiable metrics for evaluating text-to-music systems would be beneficial for tracking progress and comparing different approaches.
-
Real-World Deployment: The current implementation of MusicMagus is a research prototype. Deploying such a system in a real-world setting would likely require addressing additional challenges, such as user interface design, integration with existing music production workflows, and ensuring a positive user experience for non-expert music creators.
Despite these potential limitations, the MusicMagus system represents a significant step forward in the quest to democratize music creation and empower more people to express their musical ideas through natural language. As the field of text-to-music generation continues to evolve, researchers and developers should remain vigilant in addressing these challenges and exploring new frontiers to make music creation more accessible and inclusive for all.
Conclusion
The MusicMagus system introduced in this paper showcases the power of diffusion models in the realm of text-to-music generation and editing. By leveraging the inherent relationship between language and music, MusicMagus allows users to create, manipulate, and refine musical compositions simply by providing natural language descriptions, without the need for prior musical expertise or training on specific music datasets.
The system's zero-shot capabilities, which enable it to work with a wide range of text prompts, have the potential to democratize music creation and empower a broader audience to express their musical ideas. As the field of text-to-music generation continues to evolve, further research and development of systems like MusicMagus could have far-reaching implications, making music creation more accessible and inclusive for people of all backgrounds and skill levels.
While the paper highlights the impressive capabilities of MusicMagus, it also acknowledges areas for potential improvement, such as addressing dataset bias, ensuring musical coherence, and developing more robust evaluation metrics. As researchers and developers continue to push the boundaries of this technology, it will be crucial to address these challenges and explore new frontiers to unlock the full potential of text-to-music systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Instruct-MusicGen: Unlocking Text-to-Music Editing for Music Language Models via Instruction Tuning
Yixiao Zhang, Yukara Ikemiya, Woosung Choi, Naoki Murata, Marco A. Mart'inez-Ram'irez, Liwei Lin, Gus Xia, Wei-Hsiang Liao, Yuki Mitsufuji, Simon Dixon
0
0
Recent advances in text-to-music editing, which employ text queries to modify music (e.g. by changing its style or adjusting instrumental components), present unique challenges and opportunities for AI-assisted music creation. Previous approaches in this domain have been constrained by the necessity to train specific editing models from scratch, which is both resource-intensive and inefficient; other research uses large language models to predict edited music, resulting in imprecise audio reconstruction. To Combine the strengths and address these limitations, we introduce Instruct-MusicGen, a novel approach that finetunes a pretrained MusicGen model to efficiently follow editing instructions such as adding, removing, or separating stems. Our approach involves a modification of the original MusicGen architecture by incorporating a text fusion module and an audio fusion module, which allow the model to process instruction texts and audio inputs concurrently and yield the desired edited music. Remarkably, Instruct-MusicGen only introduces 8% new parameters to the original MusicGen model and only trains for 5K steps, yet it achieves superior performance across all tasks compared to existing baselines, and demonstrates performance comparable to the models trained for specific tasks. This advancement not only enhances the efficiency of text-to-music editing but also broadens the applicability of music language models in dynamic music production environments.
5/30/2024

MeLFusion: Synthesizing Music from Image and Language Cues using Diffusion Models
Sanjoy Chowdhury, Sayan Nag, K J Joseph, Balaji Vasan Srinivasan, Dinesh Manocha
0
0
Music is a universal language that can communicate emotions and feelings. It forms an essential part of the whole spectrum of creative media, ranging from movies to social media posts. Machine learning models that can synthesize music are predominantly conditioned on textual descriptions of it. Inspired by how musicians compose music not just from a movie script, but also through visualizations, we propose MeLFusion, a model that can effectively use cues from a textual description and the corresponding image to synthesize music. MeLFusion is a text-to-music diffusion model with a novel visual synapse, which effectively infuses the semantics from the visual modality into the generated music. To facilitate research in this area, we introduce a new dataset MeLBench, and propose a new evaluation metric IMSM. Our exhaustive experimental evaluation suggests that adding visual information to the music synthesis pipeline significantly improves the quality of generated music, measured both objectively and subjectively, with a relative gain of up to 67.98% on the FAD score. We hope that our work will gather attention to this pragmatic, yet relatively under-explored research area.
6/10/2024
🤷
Zero-Shot Unsupervised and Text-Based Audio Editing Using DDPM Inversion
Hila Manor, Tomer Michaeli
0
0
Editing signals using large pre-trained models, in a zero-shot manner, has recently seen rapid advancements in the image domain. However, this wave has yet to reach the audio domain. In this paper, we explore two zero-shot editing techniques for audio signals, which use DDPM inversion with pre-trained diffusion models. The first, which we coin ZEro-shot Text-based Audio (ZETA) editing, is adopted from the image domain. The second, named ZEro-shot UnSupervized (ZEUS) editing, is a novel approach for discovering semantically meaningful editing directions without supervision. When applied to music signals, this method exposes a range of musically interesting modifications, from controlling the participation of specific instruments to improvisations on the melody. Samples and code can be found in https://hilamanor.github.io/AudioEditing/ .
5/30/2024
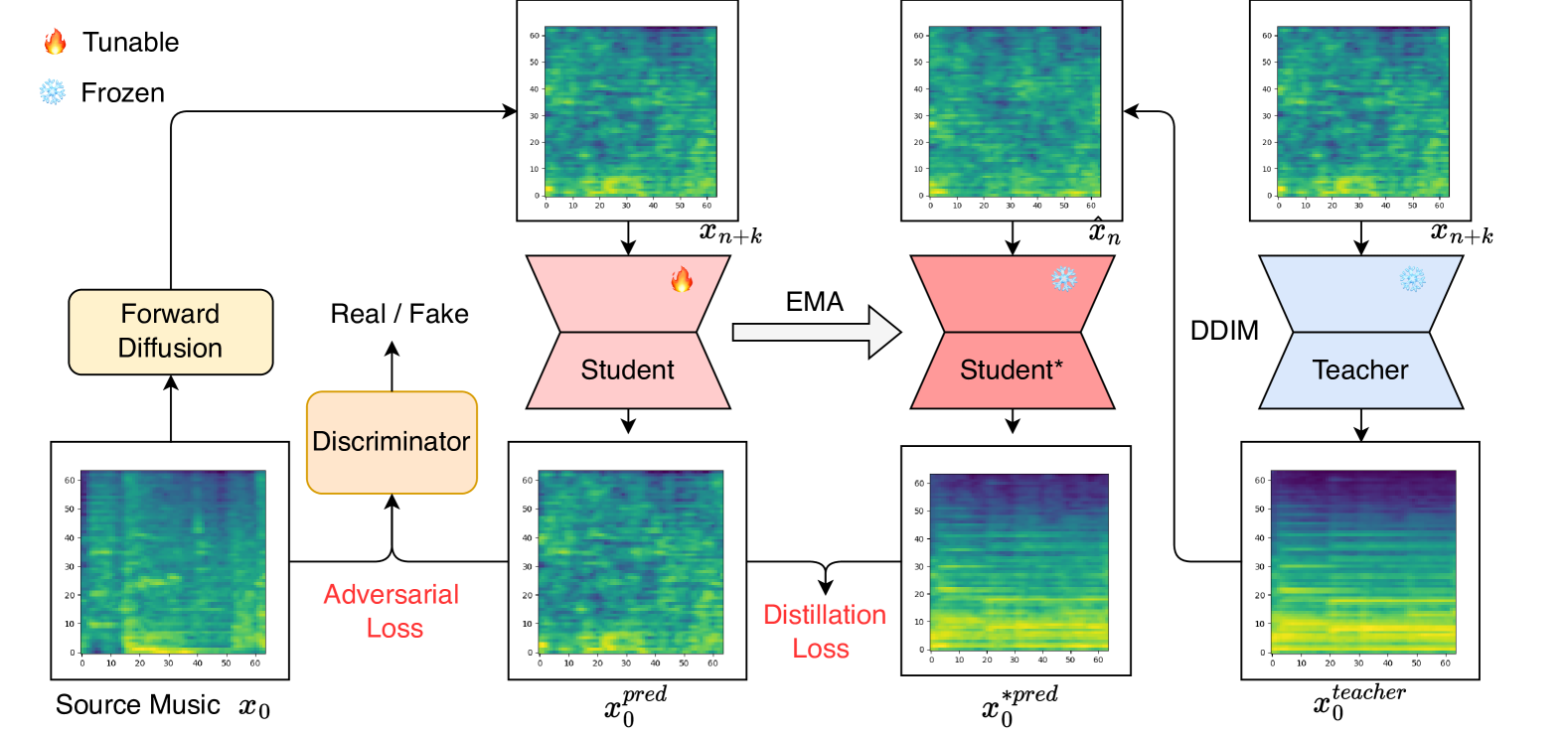
Music Consistency Models
Zhengcong Fei, Mingyuan Fan, Junshi Huang
0
0
Consistency models have exhibited remarkable capabilities in facilitating efficient image/video generation, enabling synthesis with minimal sampling steps. It has proven to be advantageous in mitigating the computational burdens associated with diffusion models. Nevertheless, the application of consistency models in music generation remains largely unexplored. To address this gap, we present Music Consistency Models (texttt{MusicCM}), which leverages the concept of consistency models to efficiently synthesize mel-spectrogram for music clips, maintaining high quality while minimizing the number of sampling steps. Building upon existing text-to-music diffusion models, the texttt{MusicCM} model incorporates consistency distillation and adversarial discriminator training. Moreover, we find it beneficial to generate extended coherent music by incorporating multiple diffusion processes with shared constraints. Experimental results reveal the effectiveness of our model in terms of computational efficiency, fidelity, and naturalness. Notable, texttt{MusicCM} achieves seamless music synthesis with a mere four sampling steps, e.g., only one second per minute of the music clip, showcasing the potential for real-time application.
4/23/2024