Diff-BGM: A Diffusion Model for Video Background Music Generation
2405.11913
0
0
Abstract
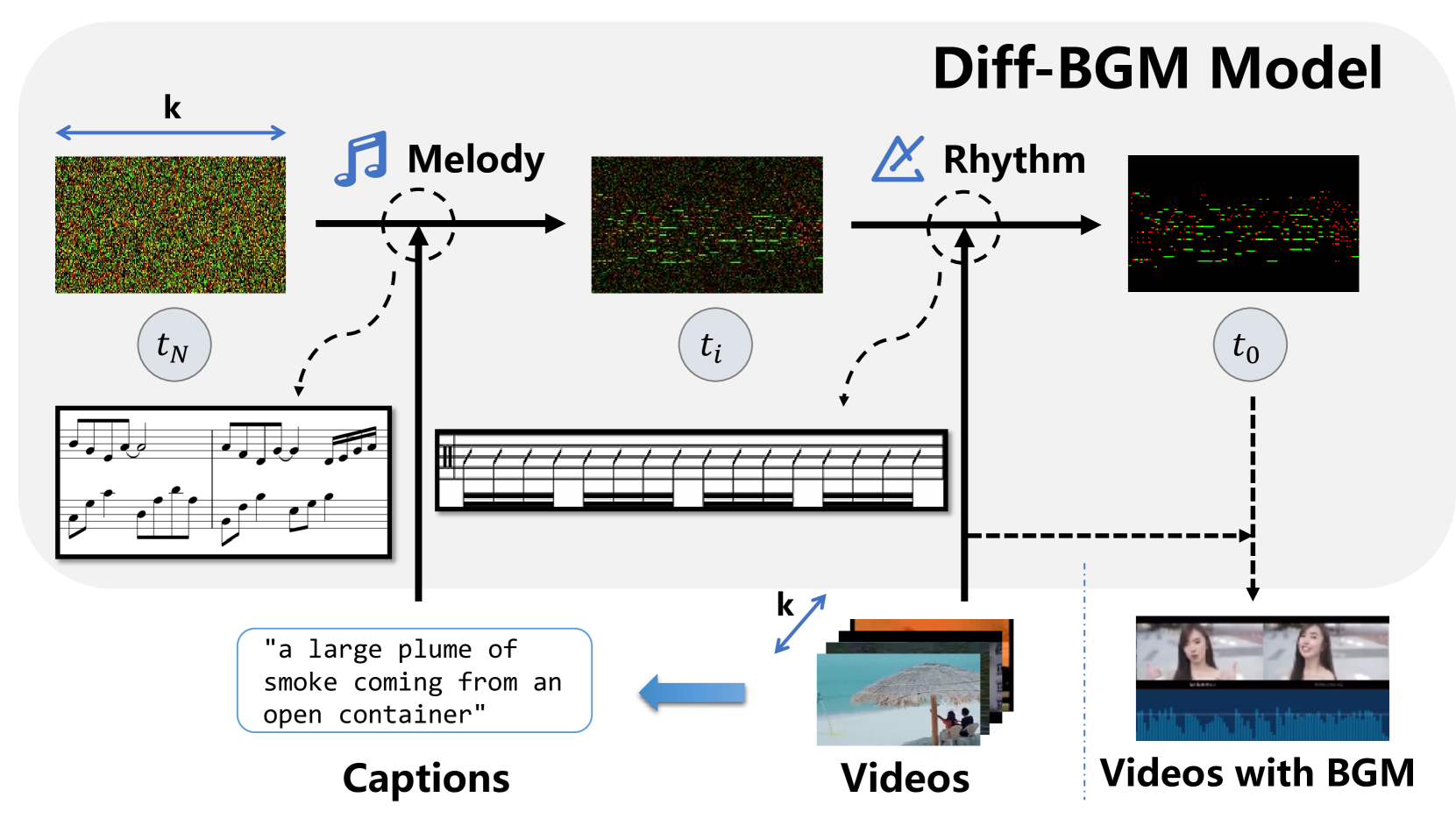
When editing a video, a piece of attractive background music is indispensable. However, video background music generation tasks face several challenges, for example, the lack of suitable training datasets, and the difficulties in flexibly controlling the music generation process and sequentially aligning the video and music. In this work, we first propose a high-quality music-video dataset BGM909 with detailed annotation and shot detection to provide multi-modal information about the video and music. We then present evaluation metrics to assess music quality, including music diversity and alignment between music and video with retrieval precision metrics. Finally, we propose the Diff-BGM framework to automatically generate the background music for a given video, which uses different signals to control different aspects of the music during the generation process, i.e., uses dynamic video features to control music rhythm and semantic features to control the melody and atmosphere. We propose to align the video and music sequentially by introducing a segment-aware cross-attention layer. Experiments verify the effectiveness of our proposed method. The code and models are available at https://github.com/sizhelee/Diff-BGM.
Create account to get full access
Overview
- This paper introduces Diff-BGM, a diffusion model for generating background music for videos.
- Diff-BGM can create diverse and coherent background music that complements the visual content of a video.
- The model is trained on a dataset of video-music pairs and uses a diffusion process to generate the music.
Plain English Explanation
Diff-BGM is a new way to automatically create background music for videos. Background music is the music that plays in the background of a video to set the mood and enhance the visuals.
Diff-BGM works by learning from a dataset of videos paired with their corresponding background music. It uses a process called diffusion to generate new background music that fits the visual content of a video. Diffusion is a technique where the model starts with random noise and gradually transforms it into something more meaningful, in this case, background music.
The key advantage of Diff-BGM is that it can create diverse and coherent background music that complements the video. This is an important capability, as finding the right background music can be challenging and time-consuming for video creators. Diff-BGM automates this process and allows for more creative and expressive video production.
Technical Explanation
Diff-BGM is a diffusion-based model for generating background music to accompany videos. The model is trained on a dataset of video-music pairs, where each video is paired with its corresponding background music.
During training, the model learns to gradually transform random noise into the target background music, using a diffusion process. This process involves repeatedly adding noise to the music and then learning to reverse the process to generate new music that matches the video content.
The key innovation of Diff-BGM is its ability to capture the complex relationship between the visual and auditory elements of a video. By learning from the paired dataset, the model can generate background music that is semantically consistent with the video, creating a more immersive and cohesive viewing experience.
The paper also explores the use of various conditioning techniques to further improve the quality and diversity of the generated background music, such as using video features or text descriptions as additional inputs to the model.
Critical Analysis
The Diff-BGM paper presents a promising approach to the challenging task of automatically generating background music for videos. The use of diffusion models, which have shown impressive results in other domains, is a well-chosen technique for this problem.
One potential limitation of the work is the reliance on a dataset of pre-existing video-music pairs. While this allows the model to learn the relationship between visuals and audio, it may limit the model's ability to generate truly novel and creative background music. Exploring ways to incorporate additional musical knowledge or generative capabilities could help address this constraint.
Additionally, the paper does not provide a detailed evaluation of the generated music's quality and its impact on the overall viewing experience. Further user studies or objective metrics could help assess the practical benefits of Diff-BGM for video creators and consumers.
Overall, Diff-BGM represents an exciting step forward in the field of automated background music generation. As the authors note, this technology could have significant implications for video production, gaming, and other multimedia applications. Continued research in this area could lead to even more advanced and versatile tools for enhancing the audiovisual experience.
Conclusion
The Diff-BGM paper presents a novel diffusion-based approach to generating background music that complements the visual content of videos. By learning from a dataset of video-music pairs, the model can create diverse and coherent background music that enhances the viewing experience.
This work highlights the potential of leveraging advanced generative models, such as diffusion models, to automate creative tasks like background music composition. As the technology continues to evolve, we may see even more sophisticated tools that empower video creators and unlock new possibilities for immersive multimedia experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
Diff-A-Riff: Musical Accompaniment Co-creation via Latent Diffusion Models
Javier Nistal, Marco Pasini, Cyran Aouameur, Maarten Grachten, Stefan Lattner
0
0
Recent advancements in deep generative models present new opportunities for music production but also pose challenges, such as high computational demands and limited audio quality. Moreover, current systems frequently rely solely on text input and typically focus on producing complete musical pieces, which is incompatible with existing workflows in music production. To address these issues, we introduce Diff-A-Riff, a Latent Diffusion Model designed to generate high-quality instrumental accompaniments adaptable to any musical context. This model offers control through either audio references, text prompts, or both, and produces 48kHz pseudo-stereo audio while significantly reducing inference time and memory usage. We demonstrate the model's capabilities through objective metrics and subjective listening tests, with extensive examples available on the accompanying website: sonycslparis.github.io/diffariff-companion/
6/13/2024
🔄
Music Style Transfer With Diffusion Model
Hong Huang, Yuyi Wang, Luyao Li, Jun Lin
0
0
Previous studies on music style transfer have mainly focused on one-to-one style conversion, which is relatively limited. When considering the conversion between multiple styles, previous methods required designing multiple modes to disentangle the complex style of the music, resulting in large computational costs and slow audio generation. The existing music style transfer methods generate spectrograms with artifacts, leading to significant noise in the generated audio. To address these issues, this study proposes a music style transfer framework based on diffusion models (DM) and uses spectrogram-based methods to achieve multi-to-multi music style transfer. The GuideDiff method is used to restore spectrograms to high-fidelity audio, accelerating audio generation speed and reducing noise in the generated audio. Experimental results show that our model has good performance in multi-mode music style transfer compared to the baseline and can generate high-quality audio in real-time on consumer-grade GPUs.
4/24/2024
Dance Any Beat: Blending Beats with Visuals in Dance Video Generation
Xuanchen Wang, Heng Wang, Dongnan Liu, Weidong Cai
0
0
The task of generating dance from music is crucial, yet current methods, which mainly produce joint sequences, lead to outputs that lack intuitiveness and complicate data collection due to the necessity for precise joint annotations. We introduce a Dance Any Beat Diffusion model, namely DabFusion, that employs music as a conditional input to directly create dance videos from still images, utilizing conditional image-to-video generation principles. This approach pioneers the use of music as a conditioning factor in image-to-video synthesis. Our method unfolds in two stages: training an auto-encoder to predict latent optical flow between reference and driving frames, eliminating the need for joint annotation, and training a U-Net-based diffusion model to produce these latent optical flows guided by music rhythm encoded by CLAP. Although capable of producing high-quality dance videos, the baseline model struggles with rhythm alignment. We enhance the model by adding beat information, improving synchronization. We introduce a 2D motion-music alignment score (2D-MM Align) for quantitative assessment. Evaluated on the AIST++ dataset, our enhanced model shows marked improvements in 2D-MM Align score and established metrics. Video results can be found on our project page: https://DabFusion.github.io.
5/16/2024
VidMuse: A Simple Video-to-Music Generation Framework with Long-Short-Term Modeling
Zeyue Tian, Zhaoyang Liu, Ruibin Yuan, Jiahao Pan, Xiaoqiang Huang, Qifeng Liu, Xu Tan, Qifeng Chen, Wei Xue, Yike Guo
0
0
In this work, we systematically study music generation conditioned solely on the video. First, we present a large-scale dataset comprising 190K video-music pairs, including various genres such as movie trailers, advertisements, and documentaries. Furthermore, we propose VidMuse, a simple framework for generating music aligned with video inputs. VidMuse stands out by producing high-fidelity music that is both acoustically and semantically aligned with the video. By incorporating local and global visual cues, VidMuse enables the creation of musically coherent audio tracks that consistently match the video content through Long-Short-Term modeling. Through extensive experiments, VidMuse outperforms existing models in terms of audio quality, diversity, and audio-visual alignment. The code and datasets will be available at https://github.com/ZeyueT/VidMuse/.
6/7/2024