DiffCLIP: Leveraging Stable Diffusion for Language Grounded 3D Classification

0
💬
Sign in to get full access
Overview
- Large pre-trained models like CLIP have had a significant impact on computer vision, enabling multi-modal learning.
- However, CLIP's performance on 3D point cloud processing tasks is limited due to the domain gap between depth maps and training images.
- This paper proposes "DiffCLIP", a new pre-training framework that incorporates stable diffusion with ControlNet to minimize the domain gap in the visual branch.
- A style-prompt generation module is also introduced for few-shot tasks in the textual branch.
- Extensive experiments show that DiffCLIP has strong abilities for 3D understanding, achieving state-of-the-art performance on zero-shot classification tasks.
Plain English Explanation
Large pre-trained AI models like CLIP have revolutionized computer vision by allowing models to learn from both images and text. This has led to impressive results in tasks like image classification, object detection, and semantic segmentation.
However, these models struggle with processing 3D data, such as point clouds from depth sensors. This is because the 3D data is very different from the 2D images the models were trained on, creating a "domain gap".
To address this, the researchers developed a new pre-training approach called "DiffCLIP". DiffCLIP combines two powerful AI techniques - "stable diffusion" and "ControlNet" - to help the visual branch of the model better understand 3D data. They also introduced a "style-prompt generation" module to improve the model's performance on tasks with limited training data.
Through extensive testing on standard 3D datasets, the researchers showed that DiffCLIP can achieve state-of-the-art results on zero-shot 3D classification tasks. This means the model can correctly identify objects in 3D scenes without being explicitly trained on those specific objects - a very impressive capability.
Technical Explanation
The core innovation of this paper is the DiffCLIP framework, which aims to address the domain gap between 3D point cloud data and the 2D images used to pre-train models like CLIP.
DiffCLIP incorporates two key components:
-
Stable Diffusion with ControlNet: The researchers use the stable diffusion model, which can generate realistic images from text descriptions, and combine it with ControlNet, a technique that allows the diffusion process to be guided by additional input (in this case, the 3D point cloud data). This helps the visual branch of DiffCLIP learn a more robust representation of 3D data.
-
Style-Prompt Generation Module: For the textual branch, the researchers introduce a style-prompt generation module. This allows the model to adapt its language understanding to specific few-shot tasks by automatically generating appropriate text prompts.
The researchers evaluate DiffCLIP on standard 3D understanding benchmarks, including ModelNet10, ModelNet40, and ScanObjectNN. They show that DiffCLIP achieves state-of-the-art performance on zero-shot 3D classification tasks, outperforming previous methods by a significant margin. For example, on the OBJ_BG subset of ScanObjectNN, DiffCLIP achieves 43.2% accuracy, which is the best reported result.
Critical Analysis
The paper presents a compelling approach to addressing the domain gap between 2D image data and 3D point cloud data for pre-trained models like CLIP. The use of stable diffusion and ControlNet is a clever way to help the visual branch of the model better understand 3D structures, and the style-prompt generation module is an interesting solution for improving few-shot learning performance.
However, the paper does not delve into the potential limitations or drawbacks of the DiffCLIP approach. For example, the computational and memory requirements of the model are not discussed, which could be a concern for real-world deployment. Additionally, the paper does not explore the generalization of the model to other 3D tasks beyond classification, such as 3D object detection or segmentation.
Furthermore, the paper could have provided more insights into the specific mechanisms by which DiffCLIP is able to outperform previous methods on the 3D understanding benchmarks. A deeper analysis of the model's strengths and weaknesses would help readers better understand the potential and limitations of the approach.
Overall, the DiffCLIP framework represents an important step towards bridging the gap between 2D and 3D data for pre-trained models. However, further research is needed to fully understand the capabilities and constraints of this approach, as well as its potential impact on the broader field of 3D computer vision.
Conclusion
This paper presents a novel pre-training framework called DiffCLIP that aims to address the domain gap between 2D image data and 3D point cloud data for large pre-trained models. By incorporating stable diffusion and ControlNet, DiffCLIP is able to learn a more robust representation of 3D structures, while the style-prompt generation module helps improve performance on few-shot 3D understanding tasks.
The researchers demonstrate the effectiveness of DiffCLIP through extensive experiments on standard 3D datasets, where the model achieves state-of-the-art results on zero-shot 3D classification. This suggests that DiffCLIP could be a valuable tool for advancing the field of 3D computer vision and enabling more effective use of pre-trained models in real-world 3D applications.
While the paper presents a compelling approach, it would be valuable to see further analysis of the model's limitations and potential areas for improvement. Nonetheless, the DiffCLIP framework represents an important step forward in bridging the gap between 2D and 3D data for powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
DiffCLIP: Leveraging Stable Diffusion for Language Grounded 3D Classification
Sitian Shen, Zilin Zhu, Linqian Fan, Harry Zhang, Xinxiao Wu
Large pre-trained models have had a significant impact on computer vision by enabling multi-modal learning, where the CLIP model has achieved impressive results in image classification, object detection, and semantic segmentation. However, the model's performance on 3D point cloud processing tasks is limited due to the domain gap between depth maps from 3D projection and training images of CLIP. This paper proposes DiffCLIP, a new pre-training framework that incorporates stable diffusion with ControlNet to minimize the domain gap in the visual branch. Additionally, a style-prompt generation module is introduced for few-shot tasks in the textual branch. Extensive experiments on the ModelNet10, ModelNet40, and ScanObjectNN datasets show that DiffCLIP has strong abilities for 3D understanding. By using stable diffusion and style-prompt generation, DiffCLIP achieves an accuracy of 43.2% for zero-shot classification on OBJ_BG of ScanObjectNN, which is state-of-the-art performance, and an accuracy of 80.6% for zero-shot classification on ModelNet10, which is comparable to state-of-the-art performance.
Read more5/7/2024

0
Diffusion Feedback Helps CLIP See Better
Wenxuan Wang, Quan Sun, Fan Zhang, Yepeng Tang, Jing Liu, Xinlong Wang
Contrastive Language-Image Pre-training (CLIP), which excels at abstracting open-world representations across domains and modalities, has become a foundation for a variety of vision and multimodal tasks. However, recent studies reveal that CLIP has severe visual shortcomings, such as which can hardly distinguish orientation, quantity, color, structure, etc. These visual shortcomings also limit the perception capabilities of multimodal large language models (MLLMs) built on CLIP. The main reason could be that the image-text pairs used to train CLIP are inherently biased, due to the lack of the distinctiveness of the text and the diversity of images. In this work, we present a simple post-training approach for CLIP models, which largely overcomes its visual shortcomings via a self-supervised diffusion process. We introduce DIVA, which uses the DIffusion model as a Visual Assistant for CLIP. Specifically, DIVA leverages generative feedback from text-to-image diffusion models to optimize CLIP representations, with only images (without corresponding text). We demonstrate that DIVA improves CLIP's performance on the challenging MMVP-VLM benchmark which assesses fine-grained visual abilities to a large extent (e.g., 3-7%), and enhances the performance of MLLMs and vision models on multimodal understanding and segmentation tasks. Extensive evaluation on 29 image classification and retrieval benchmarks confirms that our framework preserves CLIP's strong zero-shot capabilities. The code is available at https://github.com/baaivision/DIVA.
Read more8/27/2024
0
FreeSeg-Diff: Training-Free Open-Vocabulary Segmentation with Diffusion Models
Barbara Toniella Corradini, Mustafa Shukor, Paul Couairon, Guillaume Couairon, Franco Scarselli, Matthieu Cord
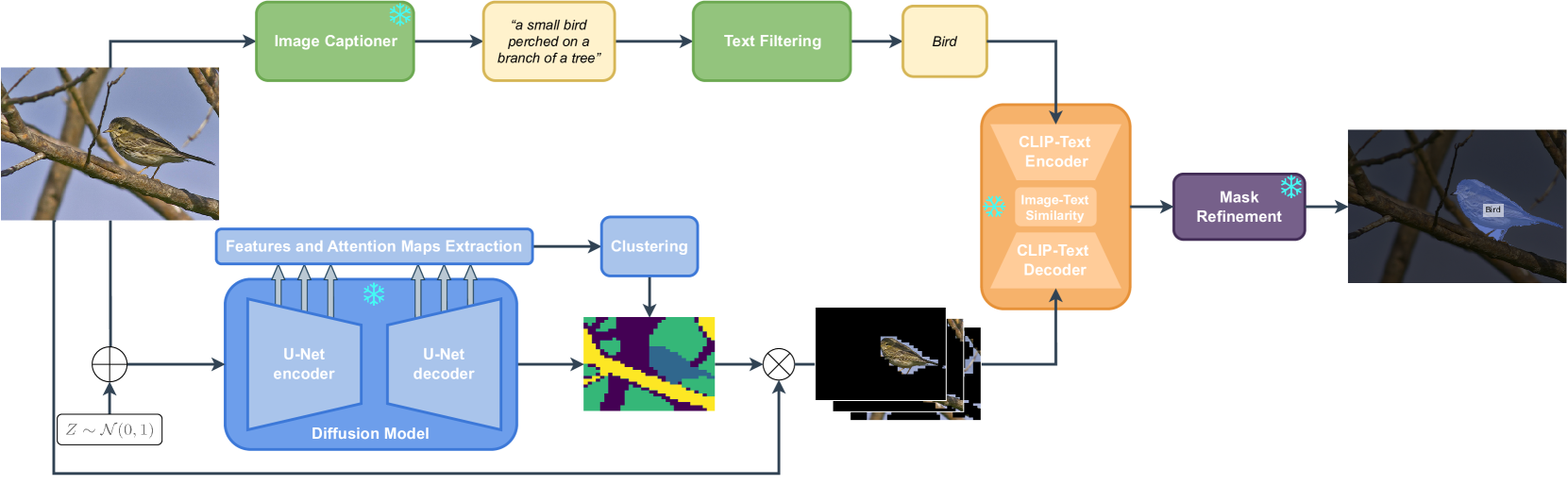
Foundation models have exhibited unprecedented capabilities in tackling many domains and tasks. Models such as CLIP are currently widely used to bridge cross-modal representations, and text-to-image diffusion models are arguably the leading models in terms of realistic image generation. Image generative models are trained on massive datasets that provide them with powerful internal spatial representations. In this work, we explore the potential benefits of such representations, beyond image generation, in particular, for dense visual prediction tasks. We focus on the task of image segmentation, which is traditionally solved by training models on closed-vocabulary datasets, with pixel-level annotations. To avoid the annotation cost or training large diffusion models, we constraint our setup to be zero-shot and training-free. In a nutshell, our pipeline leverages different and relatively small-sized, open-source foundation models for zero-shot open-vocabulary segmentation. The pipeline is as follows: the image is passed to both a captioner model (i.e. BLIP) and a diffusion model (i.e., Stable Diffusion Model) to generate a text description and visual representation, respectively. The features are clustered and binarized to obtain class agnostic masks for each object. These masks are then mapped to a textual class, using the CLIP model to support open-vocabulary. Finally, we add a refinement step that allows to obtain a more precise segmentation mask. Our approach (dubbed FreeSeg-Diff), which does not rely on any training, outperforms many training-based approaches on both Pascal VOC and COCO datasets. In addition, we show very competitive results compared to the recent weakly-supervised segmentation approaches. We provide comprehensive experiments showing the superiority of diffusion model features compared to other pretrained models. Project page: https://bcorrad.github.io/freesegdiff/
Read more4/1/2024

0
CLIP-based Point Cloud Classification via Point Cloud to Image Translation
Shuvozit Ghose, Manyi Li, Yiming Qian, Yang Wang
Point cloud understanding is an inherently challenging problem because of the sparse and unordered structure of the point cloud in the 3D space. Recently, Contrastive Vision-Language Pre-training (CLIP) based point cloud classification model i.e. PointCLIP has added a new direction in the point cloud classification research domain. In this method, at first multi-view depth maps are extracted from the point cloud and passed through the CLIP visual encoder. To transfer the 3D knowledge to the network, a small network called an adapter is fine-tuned on top of the CLIP visual encoder. PointCLIP has two limitations. Firstly, the point cloud depth maps lack image information which is essential for tasks like classification and recognition. Secondly, the adapter only relies on the global representation of the multi-view features. Motivated by this observation, we propose a Pretrained Point Cloud to Image Translation Network (PPCITNet) that produces generalized colored images along with additional salient visual cues to the point cloud depth maps so that it can achieve promising performance on point cloud classification and understanding. In addition, we propose a novel viewpoint adapter that combines the view feature processed by each viewpoint as well as the global intertwined knowledge that exists across the multi-view features. The experimental results demonstrate the superior performance of the proposed model over existing state-of-the-art CLIP-based models on ModelNet10, ModelNet40, and ScanobjectNN datasets.
Read more8/9/2024