CLIP-based Point Cloud Classification via Point Cloud to Image Translation

0

Sign in to get full access
Overview
- This paper explores using CLIP (Contrastive Language-Image Pre-Training) for point cloud classification tasks.
- The key idea is to translate point clouds into images, which can then be classified using the CLIP model.
- This approach aims to leverage the powerful language-vision understanding of CLIP for few-shot and zero-shot point cloud classification.
Plain English Explanation
The paper introduces a new way to classify 3D point cloud data using a pre-trained language-vision model called CLIP. Point clouds are 3D representations of objects or scenes, made up of a set of individual points in space.
Traditionally, classifying point clouds has been a challenging task, requiring specialized deep learning models. The researchers in this paper had the clever idea of converting the point cloud data into a 2D image format, which can then be fed into the CLIP model.
CLIP is a powerful AI system that has been pre-trained on a huge amount of image-text data, allowing it to understand the relationship between visual and linguistic concepts. By translating point clouds into images, the researchers can leverage CLIP's impressive language-vision understanding to classify the 3D data, even in few-shot or zero-shot scenarios where only limited training data is available.
This approach has several potential benefits. First, it allows point cloud classification to benefit from the advancements in large-scale language-vision models like CLIP, without needing to train a specialized 3D model from scratch. Second, the use of image-based classification can be more efficient and scalable than working directly with 3D point cloud data. And third, the zero-shot and few-shot capabilities of CLIP-based classification could be particularly useful in applications where labeled 3D data is scarce.
Technical Explanation
The core of the proposed approach is a Point Cloud to Image Translation (PC2IT) module that converts 3D point cloud data into a 2D image representation. This translation is achieved using a convolutional neural network architecture inspired by image-to-image translation models.
The translated images are then passed through the pre-trained CLIP model, which extracts visual features that can be used for classification. The researchers explore both zero-shot and few-shot learning scenarios, leveraging CLIP's ability to relate visual concepts to textual class labels.
Experiments on several point cloud classification benchmarks demonstrate the effectiveness of this CLIP-based approach, particularly in few-shot and zero-shot settings where it outperforms specialized 3D classifiers. The results highlight the potential of leveraging large-scale language-vision models like CLIP for 3D data understanding tasks.
Critical Analysis
The paper presents a novel and promising approach for point cloud classification, but there are a few potential limitations and areas for further research:
-
The quality and fidelity of the point cloud to image translation could impact the final classification performance, especially for more complex 3D shapes. Exploring more advanced translation architectures or techniques may be valuable.
-
The reliance on pre-trained CLIP means the approach is limited by CLIP's own biases and shortcomings, which could be further investigated.
-
The few-shot and zero-shot capabilities demonstrated in the paper are promising, but the performance gap to fully supervised methods suggests there is room for improvement in this area.
-
The scope of the experiments is relatively narrow, focusing on standard point cloud classification benchmarks. Evaluating the method on a broader range of 3D data understanding tasks could provide additional insights.
Overall, this paper presents an innovative approach that leverages the power of large-scale language-vision models for point cloud classification. Further research into the limitations and potential extensions of this technique could yield valuable advancements in 3D data understanding.
Conclusion
This paper introduces a novel CLIP-based approach for point cloud classification, which translates 3D point cloud data into 2D images that can then be classified using the pre-trained CLIP model. The key advantage of this method is its ability to leverage the powerful language-vision understanding of CLIP, particularly in few-shot and zero-shot learning scenarios where labeled 3D data is scarce.
The results demonstrate the effectiveness of this approach on standard point cloud classification benchmarks, outperforming specialized 3D classifiers in few-shot and zero-shot settings. While the paper highlights the potential of this technique, further research is needed to address potential limitations, such as the quality of the point cloud to image translation and the reliance on the pre-trained CLIP model.
Overall, this work represents an exciting step forward in using large-scale language-vision models for 3D data understanding, with potential applications in a variety of domains where efficient and flexible classification of point cloud data is required.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CLIP-based Point Cloud Classification via Point Cloud to Image Translation
Shuvozit Ghose, Manyi Li, Yiming Qian, Yang Wang
Point cloud understanding is an inherently challenging problem because of the sparse and unordered structure of the point cloud in the 3D space. Recently, Contrastive Vision-Language Pre-training (CLIP) based point cloud classification model i.e. PointCLIP has added a new direction in the point cloud classification research domain. In this method, at first multi-view depth maps are extracted from the point cloud and passed through the CLIP visual encoder. To transfer the 3D knowledge to the network, a small network called an adapter is fine-tuned on top of the CLIP visual encoder. PointCLIP has two limitations. Firstly, the point cloud depth maps lack image information which is essential for tasks like classification and recognition. Secondly, the adapter only relies on the global representation of the multi-view features. Motivated by this observation, we propose a Pretrained Point Cloud to Image Translation Network (PPCITNet) that produces generalized colored images along with additional salient visual cues to the point cloud depth maps so that it can achieve promising performance on point cloud classification and understanding. In addition, we propose a novel viewpoint adapter that combines the view feature processed by each viewpoint as well as the global intertwined knowledge that exists across the multi-view features. The experimental results demonstrate the superior performance of the proposed model over existing state-of-the-art CLIP-based models on ModelNet10, ModelNet40, and ScanobjectNN datasets.
Read more8/9/2024
💬
0
DiffCLIP: Leveraging Stable Diffusion for Language Grounded 3D Classification
Sitian Shen, Zilin Zhu, Linqian Fan, Harry Zhang, Xinxiao Wu
Large pre-trained models have had a significant impact on computer vision by enabling multi-modal learning, where the CLIP model has achieved impressive results in image classification, object detection, and semantic segmentation. However, the model's performance on 3D point cloud processing tasks is limited due to the domain gap between depth maps from 3D projection and training images of CLIP. This paper proposes DiffCLIP, a new pre-training framework that incorporates stable diffusion with ControlNet to minimize the domain gap in the visual branch. Additionally, a style-prompt generation module is introduced for few-shot tasks in the textual branch. Extensive experiments on the ModelNet10, ModelNet40, and ScanObjectNN datasets show that DiffCLIP has strong abilities for 3D understanding. By using stable diffusion and style-prompt generation, DiffCLIP achieves an accuracy of 43.2% for zero-shot classification on OBJ_BG of ScanObjectNN, which is state-of-the-art performance, and an accuracy of 80.6% for zero-shot classification on ModelNet10, which is comparable to state-of-the-art performance.
Read more5/7/2024
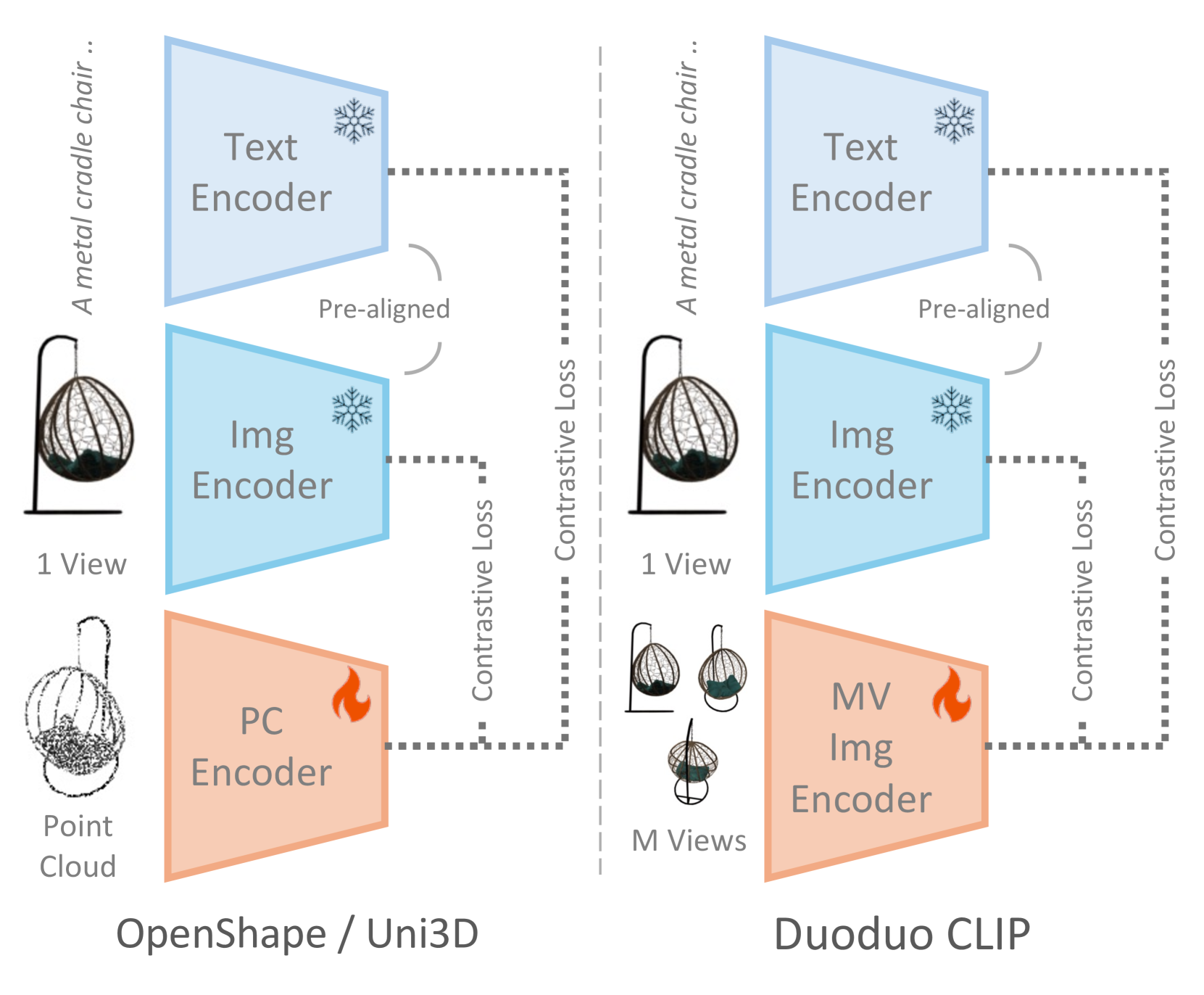
0
Duoduo CLIP: Efficient 3D Understanding with Multi-View Images
Han-Hung Lee, Yiming Zhang, Angel X. Chang
We introduce Duoduo CLIP, a model for 3D representation learning that learns shape encodings from multi-view images instead of point-clouds. The choice of multi-view images allows us to leverage 2D priors from off-the-shelf CLIP models to facilitate fine-tuning with 3D data. Our approach not only shows better generalization compared to existing point cloud methods, but also reduces GPU requirements and training time. In addition, we modify the model with cross-view attention to leverage information across multiple frames of the object which further boosts performance. Compared to the current SOTA point cloud method that requires 480 A100 hours to train 1 billion model parameters we only require 57 A5000 hours and 87 million parameters. Multi-view images also provide more flexibility in use cases compared to point clouds. This includes being able to encode objects with a variable number of images, with better performance when more views are used. This is in contrast to point cloud based methods, where an entire scan or model of an object is required. We showcase this flexibility with object retrieval from images of real-world objects. Our model also achieves better performance in more fine-grained text to shape retrieval, demonstrating better text-and-shape alignment than point cloud based models.
Read more6/18/2024
🧪
0
TagCLIP: Improving Discrimination Ability of Open-Vocabulary Semantic Segmentation
Jingyao Li, Pengguang Chen, Shengju Qian, Shu Liu, Jiaya Jia
Contrastive Language-Image Pre-training (CLIP) has recently shown great promise in pixel-level zero-shot learning tasks. However, existing approaches utilizing CLIP's text and patch embeddings to generate semantic masks often misidentify input pixels from unseen classes, leading to confusion between novel classes and semantically similar ones. In this work, we propose a novel approach, TagCLIP (Trusty-aware guided CLIP), to address this issue. We disentangle the ill-posed optimization problem into two parallel processes: semantic matching performed individually and reliability judgment for improving discrimination ability. Building on the idea of special tokens in language modeling representing sentence-level embeddings, we introduce a trusty token that enables distinguishing novel classes from known ones in prediction. To evaluate our approach, we conduct experiments on two benchmark datasets, PASCAL VOC 2012, COCO-Stuff 164K and PASCAL Context. Our results show that TagCLIP improves the Intersection over Union (IoU) of unseen classes by 7.4%, 1.7% and 2.1%, respectively, with negligible overheads. The code is available at https://github.com/dvlab-research/TagCLIP.
Read more9/4/2024