Differentially Private Verification of Survey-Weighted Estimates
2404.02519
0
0

Abstract
Several official statistics agencies release synthetic data as public use microdata files. In practice, synthetic data do not admit accurate results for every analysis. Thus, it is beneficial for agencies to provide users with feedback on the quality of their analyses of the synthetic data. One approach is to couple synthetic data with a verification server that provides users with measures of the similarity of estimates computed with the synthetic and underlying confidential data. However, such measures leak information about the confidential records, so that agencies may wish to apply disclosure control methods to the released verification measures. We present a verification measure that satisfies differential privacy and can be used when the underlying confidential are collected with a complex survey design. We illustrate the verification measure using repeated sampling simulations where the confidential data are sampled with a probability proportional to size design, and the analyst estimates a population total or mean with the synthetic data. The simulations suggest that the verification measures can provide useful information about the quality of synthetic data inferences.
Create account to get full access
Overview
- This paper explores a method for verifying survey-weighted estimates while preserving the privacy of the survey participants.
- The researchers propose a differentially private algorithm that allows for verification of survey results without compromising the confidentiality of the underlying data.
- The technique aims to balance the need for accurate and reliable survey data with the ethical obligation to protect the privacy of survey respondents.
Plain English Explanation
Survey data is incredibly valuable for understanding populations and informing important decisions. However, the personal information collected in surveys must be carefully protected to maintain participants' privacy. This paper describes a new approach that allows the accuracy of survey results to be verified without revealing the private details of individual respondents.
The key idea is to apply a technique called "differential privacy" to the survey data. Differential privacy adds controlled amounts of noise or randomness to the data, masking individual responses while preserving the overall statistical patterns. This enables independent verification of the survey findings without compromising the confidentiality of the underlying information.
Imagine a survey asking about people's personal finances. The researchers wouldn't want to disclose each participant's exact income or savings. But they could apply differential privacy to summarize the overall wealth distribution without revealing private details. This allows them to confirm the accuracy of the survey results while protecting individual privacy.
The paper demonstrates how this differentially private verification process can be applied to a common survey analysis technique called "survey weighting." Survey weighting adjusts the sample to better represent the broader population being studied. The authors show how to verify these weighted estimates in a privacy-preserving way, an important advance for ensuring the integrity of survey data.
Technical Explanation
The paper introduces a framework for differentially private verification of survey-weighted estimates. Survey-weighted estimation is a common technique used to adjust survey samples to better reflect the target population. The authors demonstrate how to apply differential privacy principles to enable verification of these weighted estimates without compromising the privacy of individual respondents.
Differential privacy involves deliberately adding noise or randomness to data in a controlled way, masking individual-level details while preserving useful statistical patterns. The authors develop a differentially private algorithm that allows an independent third party to validate the accuracy of survey-weighted estimates without access to the raw survey responses.
Key steps in the process include:
- Calculating survey-weighted point estimates and corresponding variance estimates.
- Injecting differential privacy noise into the weighted estimates and variances.
- Providing the perturbed estimates to a verifier, who can then confirm the results without accessing the original survey data.
The authors prove that this approach satisfies the formal requirements of differential privacy, ensuring strong privacy guarantees. They also demonstrate the efficacy of the method through simulation experiments, showing it can accurately verify weighted estimates while protecting respondent confidentiality.
Critical Analysis
The paper presents an important contribution to the challenge of enabling verification and scrutiny of survey data while upholding ethical data privacy standards. The proposed differentially private verification framework represents a promising approach to this longstanding dilemma.
That said, the authors acknowledge several caveats and limitations to their work. The technique assumes the availability of accurate survey weights, which may not always be the case in practice. There are also open questions about how to best calibrate the privacy-accuracy tradeoffs inherent in the differential privacy mechanism.
Additionally, the paper focuses on verifying point estimates and variances, but does not address the privacy-preserving validation of more complex survey analyses. Extending the approach to handle a broader range of statistical summaries and inferences would be a valuable area for future research.
Overall, the paper makes a compelling case for the value of differentially private verification of survey data. While further work is needed to refine and expand the techniques, this research represents an important step forward in balancing the competing priorities of data integrity and individual privacy.
Conclusion
This paper introduces a novel framework for verifying the accuracy of survey-weighted estimates in a manner that preserves the privacy of survey respondents. By applying the principles of differential privacy, the authors demonstrate how an independent party can validate the statistical properties of weighted survey data without gaining access to the underlying personal information.
This work addresses a critical challenge at the intersection of survey methodology, data science, and research ethics. Upholding data privacy is essential for maintaining public trust and participation in important survey initiatives. Yet verifying the quality and representativeness of survey findings is also vital for informing sound policy decisions. The differentially private verification approach presented in this paper represents a promising advance in reconciling these competing priorities.
As survey data continues to play an increasingly central role in evidence-based decision making, techniques like those described in this paper will become increasingly important. The authors' rigorous treatment of the problem and validation of the approach through simulation studies highlight the technical sophistication and practical relevance of this research. Further developments along these lines have the potential to significantly strengthen the reliability and trustworthiness of survey-based insights across a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Differentially Private Synthetic Data with Private Density Estimation
Nikolija Bojkovic, Po-Ling Loh
0
0
The need to analyze sensitive data, such as medical records or financial data, has created a critical research challenge in recent years. In this paper, we adopt the framework of differential privacy, and explore mechanisms for generating an entire dataset which accurately captures characteristics of the original data. We build upon the work of Boedihardjo et al, which laid the foundations for a new optimization-based algorithm for generating private synthetic data. Importantly, we adapt their algorithm by replacing a uniform sampling step with a private distribution estimator; this allows us to obtain better computational guarantees for discrete distributions, and develop a novel algorithm suitable for continuous distributions. We also explore applications of our work to several statistical tasks.
5/9/2024

Synthetic Census Data Generation via Multidimensional Multiset Sum
Cynthia Dwork, Kristjan Greenewald, Manish Raghavan
0
0
The US Decennial Census provides valuable data for both research and policy purposes. Census data are subject to a variety of disclosure avoidance techniques prior to release in order to preserve respondent confidentiality. While many are interested in studying the impacts of disclosure avoidance methods on downstream analyses, particularly with the introduction of differential privacy in the 2020 Decennial Census, these efforts are limited by a critical lack of data: The underlying microdata, which serve as necessary input to disclosure avoidance methods, are kept confidential. In this work, we aim to address this limitation by providing tools to generate synthetic microdata solely from published Census statistics, which can then be used as input to any number of disclosure avoidance algorithms for the sake of evaluation and carrying out comparisons. We define a principled distribution over microdata given published Census statistics and design algorithms to sample from this distribution. We formulate synthetic data generation in this context as a knapsack-style combinatorial optimization problem and develop novel algorithms for this setting. While the problem we study is provably hard, we show empirically that our methods work well in practice, and we offer theoretical arguments to explain our performance. Finally, we verify that the data we produce are close to the desired ground truth.
4/17/2024

Continual Release of Differentially Private Synthetic Data from Longitudinal Data Collections
Mark Bun, Marco Gaboardi, Marcel Neunhoeffer, Wanrong Zhang
0
0
Motivated by privacy concerns in long-term longitudinal studies in medical and social science research, we study the problem of continually releasing differentially private synthetic data from longitudinal data collections. We introduce a model where, in every time step, each individual reports a new data element, and the goal of the synthesizer is to incrementally update a synthetic dataset in a consistent way to capture a rich class of statistical properties. We give continual synthetic data generation algorithms that preserve two basic types of queries: fixed time window queries and cumulative time queries. We show nearly tight upper bounds on the error rates of these algorithms and demonstrate their empirical performance on realistically sized datasets from the U.S. Census Bureau's Survey of Income and Program Participation.
5/28/2024
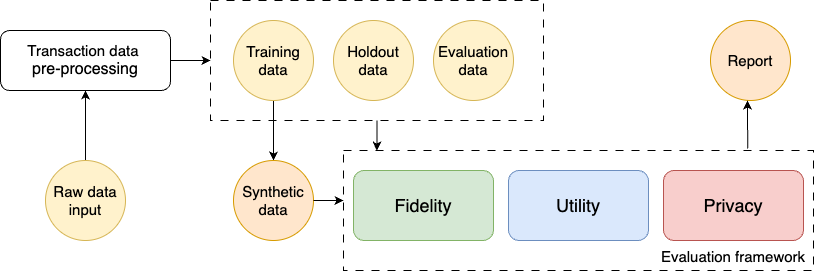
Advancing Retail Data Science: Comprehensive Evaluation of Synthetic Data
Yu Xia, Chi-Hua Wang, Joshua Mabry, Guang Cheng
0
0
The evaluation of synthetic data generation is crucial, especially in the retail sector where data accuracy is paramount. This paper introduces a comprehensive framework for assessing synthetic retail data, focusing on fidelity, utility, and privacy. Our approach differentiates between continuous and discrete data attributes, providing precise evaluation criteria. Fidelity is measured through stability and generalizability. Stability ensures synthetic data accurately replicates known data distributions, while generalizability confirms its robustness in novel scenarios. Utility is demonstrated through the synthetic data's effectiveness in critical retail tasks such as demand forecasting and dynamic pricing, proving its value in predictive analytics and strategic planning. Privacy is safeguarded using Differential Privacy, ensuring synthetic data maintains a perfect balance between resembling training and holdout datasets without compromising security. Our findings validate that this framework provides reliable and scalable evaluation for synthetic retail data. It ensures high fidelity, utility, and privacy, making it an essential tool for advancing retail data science. This framework meets the evolving needs of the retail industry with precision and confidence, paving the way for future advancements in synthetic data methodologies.
6/21/2024