Advancing Retail Data Science: Comprehensive Evaluation of Synthetic Data
2406.13130
0
0
Abstract
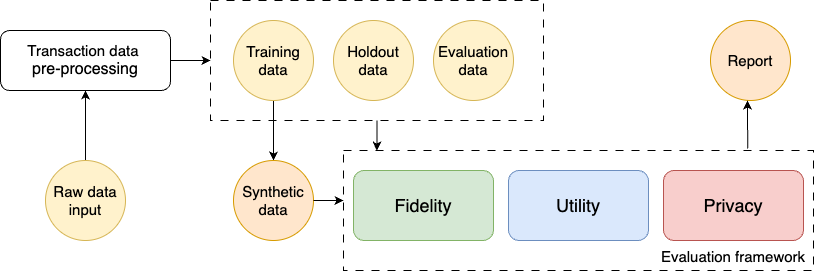
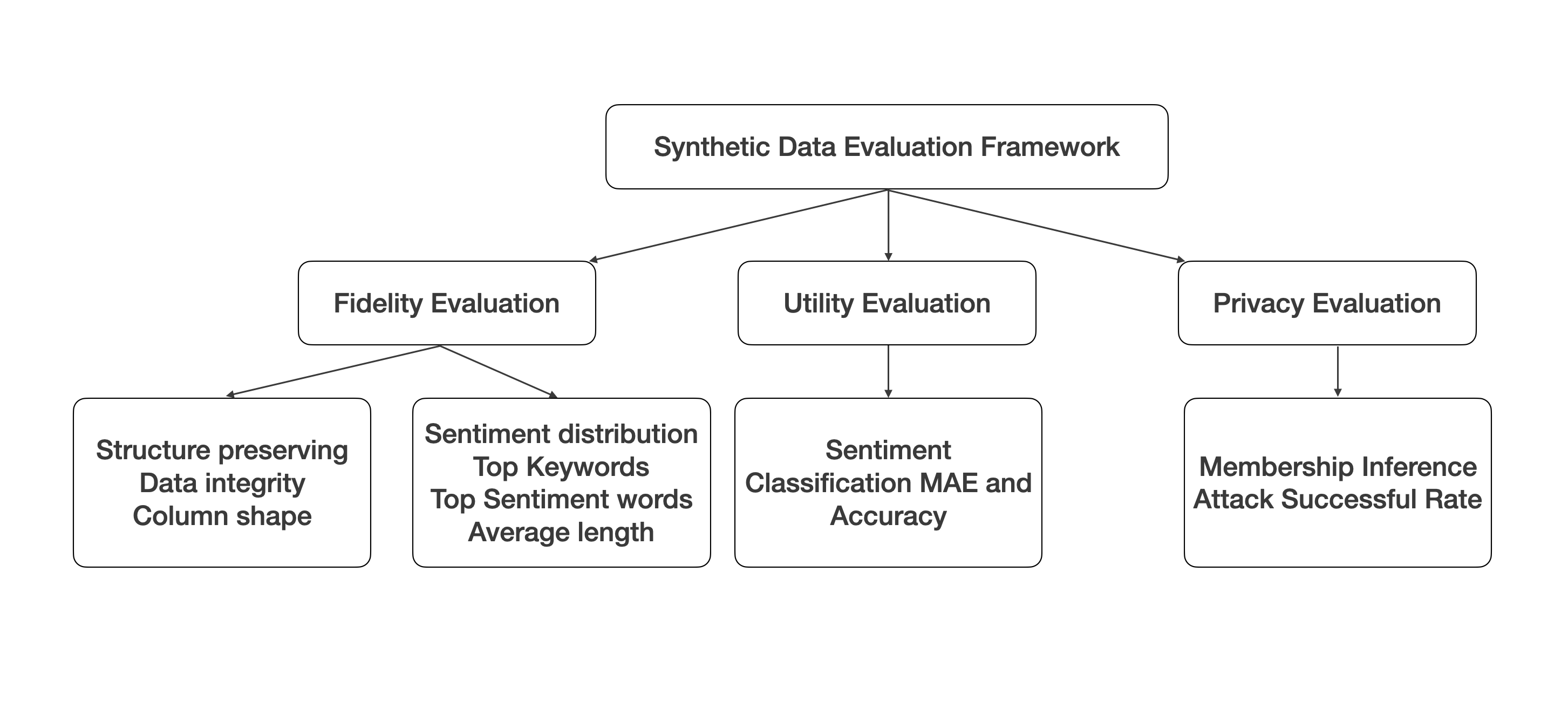
The evaluation of synthetic data generation is crucial, especially in the retail sector where data accuracy is paramount. This paper introduces a comprehensive framework for assessing synthetic retail data, focusing on fidelity, utility, and privacy. Our approach differentiates between continuous and discrete data attributes, providing precise evaluation criteria. Fidelity is measured through stability and generalizability. Stability ensures synthetic data accurately replicates known data distributions, while generalizability confirms its robustness in novel scenarios. Utility is demonstrated through the synthetic data's effectiveness in critical retail tasks such as demand forecasting and dynamic pricing, proving its value in predictive analytics and strategic planning. Privacy is safeguarded using Differential Privacy, ensuring synthetic data maintains a perfect balance between resembling training and holdout datasets without compromising security. Our findings validate that this framework provides reliable and scalable evaluation for synthetic retail data. It ensures high fidelity, utility, and privacy, making it an essential tool for advancing retail data science. This framework meets the evolving needs of the retail industry with precision and confidence, paving the way for future advancements in synthetic data methodologies.
Create account to get full access
Overview
- Comprehensive evaluation of synthetic data for retail data science
- Explores the use of synthetic data to improve data availability and privacy protection
- Assesses the performance and characteristics of different synthetic data generation approaches
Plain English Explanation
This research paper takes a deep dive into the use of synthetic data in the field of retail data science. Synthetic data is artificially generated data that aims to mimic the statistical properties of real-world data, without compromising individual privacy. The researchers recognize the growing importance of synthetic data, as businesses in the retail industry often face challenges in accessing and utilizing sensitive customer data.
The paper presents a comprehensive evaluation of various synthetic data generation techniques, examining how well they can capture the nuances and complexities of real retail data. By evaluating the performance and characteristics of these synthetic data models, the researchers provide valuable insights into the strengths, weaknesses, and trade-offs of different approaches.
This work is particularly significant as it contributes to the broader effort of auditing and generating synthetic data that can be trusted and controlled. By establishing a multi-faceted evaluation framework, the researchers help retail organizations make informed decisions about when and how to incorporate synthetic data into their data science workflows.
Additionally, the paper explores instance-level safety and fidelity considerations when working with synthetic data, recognizing the importance of preserving the essential characteristics of the original data while ensuring individual privacy.
The findings and insights presented in this research can inform best practices and lessons learned for the broader synthetic data community, paving the way for more effective and responsible use of these techniques in retail data science and beyond.
Technical Explanation
The paper begins by establishing the background and motivation for the study, highlighting the growing importance of synthetic data in the retail industry. The researchers recognize the challenges faced by businesses in accessing and utilizing sensitive customer data, and the potential of synthetic data to address these challenges while preserving privacy.
The core of the paper focuses on a comprehensive evaluation of various synthetic data generation techniques. The researchers employ a multi-faceted evaluation framework that assesses the performance and characteristics of the synthetic data models across a range of metrics, including statistical fidelity, utility for downstream tasks, and privacy preservation. This rigorous evaluation approach allows the researchers to gain a deeper understanding of the strengths, weaknesses, and trade-offs of different synthetic data generation methods.
Moreover, the paper explores the importance of instance-level safety and fidelity when working with synthetic data. The researchers recognize that preserving the essential characteristics of the original data while ensuring individual privacy is a critical consideration in the retail context.
The findings and insights from this research contribute to the broader efforts of auditing and generating synthetic data that can be trusted and controlled, as well as the establishment of multi-faceted evaluation frameworks for assessing the quality and suitability of synthetic data. The researchers also discuss best practices and lessons learned from their work, which can inform the broader synthetic data community.
Critical Analysis
The paper presents a thorough and well-designed study, addressing the important challenge of synthetic data evaluation in the retail industry. The researchers' multi-faceted evaluation framework is a valuable contribution, as it provides a comprehensive approach to assessing the performance and characteristics of synthetic data models.
One potential area for further exploration is the impact of different synthetic data generation techniques on specific downstream retail tasks, such as customer segmentation, demand forecasting, or pricing optimization. While the paper examines the utility of synthetic data for general tasks, a more granular analysis of how the synthetic data performs in real-world retail applications could provide additional insights.
Additionally, the paper could have delved deeper into the potential biases or systematic errors that may arise in the synthetic data, and how these issues could be mitigated. Understanding the limitations and potential pitfalls of synthetic data is crucial for its responsible and effective deployment in the retail sector.
Overall, this research represents a significant step forward in the field of synthetic data evaluation, and the insights and methodologies presented can be valuable for both researchers and practitioners in the retail data science community.
Conclusion
This research paper presents a comprehensive evaluation of synthetic data generation techniques for the retail industry, highlighting the growing importance of synthetic data in addressing data access and privacy challenges. The researchers employ a rigorous multi-faceted evaluation framework to assess the performance and characteristics of different synthetic data models, providing valuable insights into their strengths, weaknesses, and trade-offs.
The findings from this study contribute to the broader efforts of auditing and generating synthetic data that can be trusted and controlled, as well as the establishment of evaluation frameworks and best practices for the synthetic data community. The researchers' emphasis on instance-level safety and fidelity is particularly relevant in the retail context, where preserving the essential characteristics of the original data while ensuring individual privacy is of utmost importance.
This work represents a significant step forward in the field of retail data science, and the insights and methodologies presented can inform the responsible and effective deployment of synthetic data in a variety of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Auditing and Generating Synthetic Data with Controllable Trust Trade-offs
Brian Belgodere, Pierre Dognin, Adam Ivankay, Igor Melnyk, Youssef Mroueh, Aleksandra Mojsilovic, Jiri Navratil, Apoorva Nitsure, Inkit Padhi, Mattia Rigotti, Jerret Ross, Yair Schiff, Radhika Vedpathak, Richard A. Young
0
0
Real-world data often exhibits bias, imbalance, and privacy risks. Synthetic datasets have emerged to address these issues. This paradigm relies on generative AI models to generate unbiased, privacy-preserving data while maintaining fidelity to the original data. However, assessing the trustworthiness of synthetic datasets and models is a critical challenge. We introduce a holistic auditing framework that comprehensively evaluates synthetic datasets and AI models. It focuses on preventing bias and discrimination, ensures fidelity to the source data, assesses utility, robustness, and privacy preservation. We demonstrate the framework's effectiveness by auditing various generative models across diverse use cases like education, healthcare, banking, and human resources, spanning different data modalities such as tabular, time-series, vision, and natural language. This holistic assessment is essential for compliance with regulatory safeguards. We introduce a trustworthiness index to rank synthetic datasets based on their safeguards trade-offs. Furthermore, we present a trustworthiness-driven model selection and cross-validation process during training, exemplified with TrustFormers across various data types. This approach allows for controllable trustworthiness trade-offs in synthetic data creation. Our auditing framework fosters collaboration among stakeholders, including data scientists, governance experts, internal reviewers, external certifiers, and regulators. This transparent reporting should become a standard practice to prevent bias, discrimination, and privacy violations, ensuring compliance with policies and providing accountability, safety, and performance guarantees.
6/11/2024
An evaluation framework for synthetic data generation models
Ioannis E. Livieris, Nikos Alimpertis, George Domalis, Dimitris Tsakalidis
0
0
Nowadays, the use of synthetic data has gained popularity as a cost-efficient strategy for enhancing data augmentation for improving machine learning models performance as well as addressing concerns related to sensitive data privacy. Therefore, the necessity of ensuring quality of generated synthetic data, in terms of accurate representation of real data, consists of primary importance. In this work, we present a new framework for evaluating synthetic data generation models' ability for developing high-quality synthetic data. The proposed approach is able to provide strong statistical and theoretical information about the evaluation framework and the compared models' ranking. Two use case scenarios demonstrate the applicability of the proposed framework for evaluating the ability of synthetic data generation models to generated high quality data. The implementation code can be found in https://github.com/novelcore/synthetic_data_evaluation_framework.
4/16/2024
A Multi-Faceted Evaluation Framework for Assessing Synthetic Data Generated by Large Language Models
Yefeng Yuan, Yuhong Liu, Liang Cheng
0
0
The rapid advancements in generative AI and large language models (LLMs) have opened up new avenues for producing synthetic data, particularly in the realm of structured tabular formats, such as product reviews. Despite the potential benefits, concerns regarding privacy leakage have surfaced, especially when personal information is utilized in the training datasets. In addition, there is an absence of a comprehensive evaluation framework capable of quantitatively measuring the quality of the generated synthetic data and their utility for downstream tasks. In response to this gap, we introduce SynEval, an open-source evaluation framework designed to assess the fidelity, utility, and privacy preservation of synthetically generated tabular data via a suite of diverse evaluation metrics. We validate the efficacy of our proposed framework - SynEval - by applying it to synthetic product review data generated by three state-of-the-art LLMs: ChatGPT, Claude, and Llama. Our experimental findings illuminate the trade-offs between various evaluation metrics in the context of synthetic data generation. Furthermore, SynEval stands as a critical instrument for researchers and practitioners engaged with synthetic tabular data,, empowering them to judiciously determine the suitability of the generated data for their specific applications, with an emphasis on upholding user privacy.
4/24/2024

Instance-Level Safety-Aware Fidelity of Synthetic Data and Its Calibration
Chih-Hong Cheng, Paul Stockel, Xingyu Zhao
0
0
Modeling and calibrating the fidelity of synthetic data is paramount in shaping the future of safe and reliable self-driving technology by offering a cost-effective and scalable alternative to real-world data collection. We focus on its role in safety-critical applications, introducing four types of instance-level fidelity that go beyond mere visual input characteristics. The aim is to ensure that applying testing on synthetic data can reveal real-world safety issues, and the absence of safety-critical issues when testing under synthetic data can provide a strong safety guarantee in real-world behavior. We suggest an optimization method to refine the synthetic data generator, reducing fidelity gaps identified by deep learning components. Experiments show this tuning enhances the correlation between safety-critical errors in synthetic and real data.
5/3/2024