DiffFAS: Face Anti-Spoofing via Generative Diffusion Models

0

Sign in to get full access
Overview
- DiffFAS is a new face anti-spoofing method that uses generative diffusion models.
- It aims to improve the performance and robustness of face anti-spoofing systems.
- The paper presents the DiffFAS framework and evaluates it on several face anti-spoofing datasets.
Plain English Explanation
Facial recognition technology has become increasingly common, for example in smartphones and security systems. However, these systems can be fooled by "spoofing" attacks, where someone uses a fake face (e.g. a photo or mask) to gain unauthorized access. DiffFAS: Face Anti-Spoofing via Generative Diffusion Models introduces a new approach to detect these spoofing attempts.
The key idea is to use a type of machine learning model called a "generative diffusion model" to learn the characteristics of real faces. This model can then be used to identify fake faces that don't match the patterns of real faces. The researchers show that this DiffFAS approach outperforms previous face anti-spoofing methods on several standard datasets.
The main advantage of DiffFAS is that it can detect a wider variety of spoofing attacks, including ones that might fool other anti-spoofing systems. This makes it more robust and reliable for real-world facial recognition applications. By improving the ability to distinguish real faces from fakes, DiffFAS helps strengthen the security and privacy protections of facial recognition systems.
Technical Explanation
DiffFAS: Face Anti-Spoofing via Generative Diffusion Models proposes a new face anti-spoofing method that leverages generative diffusion models. Diffusion models are a type of deep learning architecture that can generate highly realistic images by learning the underlying data distribution.
The key components of the DiffFAS framework are:
-
Diffusion-based Face Generation: A diffusion model is trained to generate realistic face images from random noise. This captures the characteristics of real faces.
-
Face Anti-Spoofing: The trained diffusion model is used as a feature extractor. Face images are passed through the model and the internal representations are used to classify them as real or fake.
-
Self-Supervised Learning: The diffusion model is trained in a self-supervised manner, without requiring labeled real/fake face data. This makes the approach more practical and scalable.
The researchers evaluate DiffFAS on several standard face anti-spoofing datasets and show that it outperforms previous state-of-the-art methods. The diffusion-based approach demonstrates improved generalization and robustness to different types of spoofing attacks.
Critical Analysis
The DiffFAS paper presents a promising new direction for face anti-spoofing using generative diffusion models. The self-supervised training approach is a key strength, as it avoids the need for extensive labeled datasets of real and fake faces.
However, the paper does not address some potential limitations and areas for further research:
-
Computational Complexity: Diffusion models can be computationally intensive, which may limit their deployment in real-time applications. The trade-offs between model performance and inference speed should be analyzed.
-
Bias and Fairness: As with any facial recognition system, there are concerns about algorithmic bias and fairness. The paper does not examine whether DiffFAS exhibits demographic biases in its spoofing detection capabilities.
-
Adversarial Robustness: The paper evaluates DiffFAS against known spoofing attacks, but does not assess its resilience to adversarial attacks specifically designed to fool the system.
-
Real-World Deployment: While the results on benchmark datasets are promising, more research is needed to understand how DiffFAS would perform in diverse, unconstrained real-world scenarios.
Overall, the DiffFAS paper presents an innovative approach to face anti-spoofing that leverages the strengths of generative diffusion models. Further research addressing the above limitations could help strengthen the practical deployment of this technology.
Conclusion
DiffFAS: Face Anti-Spoofing via Generative Diffusion Models introduces a new face anti-spoofing method that uses generative diffusion models to learn the characteristics of real faces. By modeling the underlying data distribution, DiffFAS can more effectively detect a wide range of spoofing attacks compared to previous approaches.
The self-supervised training process and improved generalization capabilities of DiffFAS make it a promising direction for strengthening the security and privacy protections of facial recognition systems. As this technology continues to be deployed in various applications, methods like DiffFAS will play an important role in ensuring these systems are robust against spoofing attempts.
However, further research is needed to address potential limitations around computational complexity, algorithmic bias, and adversarial robustness. Addressing these challenges will be crucial for the real-world deployment of advanced face anti-spoofing solutions like DiffFAS.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!DiffFAS: Face Anti-Spoofing via Generative Diffusion Models
Xinxu Ge, Xin Liu, Zitong Yu, Jingang Shi, Chun Qi, Jie Li, Heikki Kalviainen
Face anti-spoofing (FAS) plays a vital role in preventing face recognition (FR) systems from presentation attacks. Nowadays, FAS systems face the challenge of domain shift, impacting the generalization performance of existing FAS methods. In this paper, we rethink about the inherence of domain shift and deconstruct it into two factors: image style and image quality. Quality influences the purity of the presentation of spoof information, while style affects the manner in which spoof information is presented. Based on our analysis, we propose DiffFAS framework, which quantifies quality as prior information input into the network to counter image quality shift, and performs diffusion-based high-fidelity cross-domain and cross-attack types generation to counter image style shift. DiffFAS transforms easily collectible live faces into high-fidelity attack faces with precise labels while maintaining consistency between live and spoof face identities, which can also alleviate the scarcity of labeled data with novel type attacks faced by nowadays FAS system. We demonstrate the effectiveness of our framework on challenging cross-domain and cross-attack FAS datasets, achieving the state-of-the-art performance. Available at https://github.com/murphytju/DiffFAS.
Read more9/16/2024
0
Towards Data-Centric Face Anti-Spoofing: Improving Cross-domain Generalization via Physics-based Data Synthesis
Rizhao Cai, Cecelia Soh, Zitong Yu, Haoliang Li, Wenhan Yang, Alex Kot
Face Anti-Spoofing (FAS) research is challenged by the cross-domain problem, where there is a domain gap between the training and testing data. While recent FAS works are mainly model-centric, focusing on developing domain generalization algorithms for improving cross-domain performance, data-centric research for face anti-spoofing, improving generalization from data quality and quantity, is largely ignored. Therefore, our work starts with data-centric FAS by conducting a comprehensive investigation from the data perspective for improving cross-domain generalization of FAS models. More specifically, at first, based on physical procedures of capturing and recapturing, we propose task-specific FAS data augmentation (FAS-Aug), which increases data diversity by synthesizing data of artifacts, such as printing noise, color distortion, moir'e pattern, textit{etc}. Our experiments show that using our FAS augmentation can surpass traditional image augmentation in training FAS models to achieve better cross-domain performance. Nevertheless, we observe that models may rely on the augmented artifacts, which are not environment-invariant, and using FAS-Aug may have a negative effect. As such, we propose Spoofing Attack Risk Equalization (SARE) to prevent models from relying on certain types of artifacts and improve the generalization performance. Last but not least, our proposed FAS-Aug and SARE with recent Vision Transformer backbones can achieve state-of-the-art performance on the FAS cross-domain generalization protocols. The implementation is available at https://github.com/RizhaoCai/FAS_Aug.
Read more9/6/2024
📊
0
A visualization method for data domain changes in CNN networks and the optimization method for selecting thresholds in classification tasks
Minzhe Huang, Changwei Nie, Weihong Zhong
In recent years, Face Anti-Spoofing (FAS) has played a crucial role in preserving the security of face recognition technology. With the rise of counterfeit face generation techniques, the challenge posed by digitally edited faces to face anti-spoofing is escalating. Existing FAS technologies primarily focus on intercepting physically forged faces and lack a robust solution for cross-domain FAS challenges. Moreover, determining an appropriate threshold to achieve optimal deployment results remains an issue for intra-domain FAS. To address these issues, we propose a visualization method that intuitively reflects the training outcomes of models by visualizing the prediction results on datasets. Additionally, we demonstrate that employing data augmentation techniques, such as downsampling and Gaussian blur, can effectively enhance performance on cross-domain tasks. Building upon our data visualization approach, we also introduce a methodology for setting threshold values based on the distribution of the training dataset. Ultimately, our methods secured us second place in both the Unified Physical-Digital Face Attack Detection competition and the Snapshot Spectral Imaging Face Anti-spoofing contest. The training code is available at https://github.com/SeaRecluse/CVPRW2024.
Read more4/22/2024
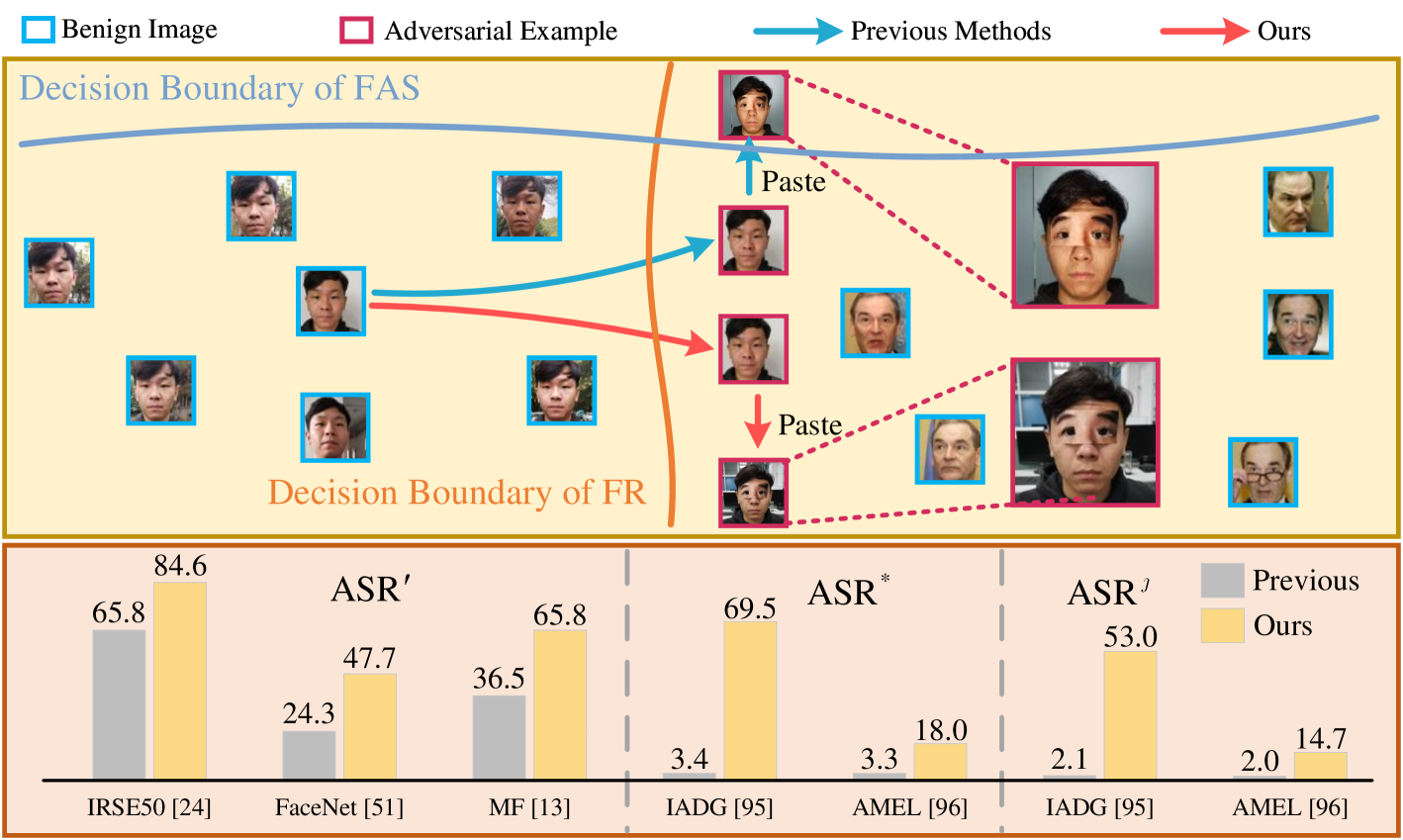
0
Adversarial Attacks on Both Face Recognition and Face Anti-spoofing Models
Fengfan Zhou, Qianyu Zhou, Xiangtai Li, Xuequan Lu, Lizhuang Ma, Hefei Ling
Adversarial attacks on Face Recognition (FR) systems have proven highly effective in compromising pure FR models, yet adversarial examples may be ineffective to the complete FR systems as Face Anti-Spoofing (FAS) models are often incorporated and can detect a significant number of them. To address this under-explored and essential problem, we propose a novel setting of adversarially attacking both FR and FAS models simultaneously, aiming to enhance the practicability of adversarial attacks on FR systems. In particular, we introduce a new attack method, namely Style-aligned Distribution Biasing (SDB), to improve the capacity of black-box attacks on both FR and FAS models. Specifically, our SDB framework consists of three key components. Firstly, to enhance the transferability of FAS models, we design a Distribution-aware Score Biasing module to optimize adversarial face examples away from the distribution of spoof images utilizing scores. Secondly, to mitigate the substantial style differences between live images and adversarial examples initialized with spoof images, we introduce an Instance Style Alignment module that aligns the style of adversarial examples with live images. In addition, to alleviate the conflicts between the gradients of FR and FAS models, we propose a Gradient Consistency Maintenance module to minimize disparities between the gradients using Hessian approximation. Extensive experiments showcase the superiority of our proposed attack method to state-of-the-art adversarial attacks.
Read more5/28/2024