Adversarial Attacks on Both Face Recognition and Face Anti-spoofing Models

0
Sign in to get full access
Overview
- This paper investigates the potential for adversarial attacks to impact both face recognition and face anti-spoofing models.
- The researchers explore methods to generate adversarial examples that can fool both types of models simultaneously.
- The findings have implications for the security and robustness of face-based authentication systems.
Plain English Explanation
Face recognition and face anti-spoofing are two important components of many security systems. Face recognition aims to identify individuals, while face anti-spoofing detects attempts to bypass the system using fake faces, such as photos or videos.
This paper explores whether it's possible to create "adversarial examples" - slightly modified images that can trick both face recognition and face anti-spoofing models. The researchers developed new attack methods and tested them on various face recognition and anti-spoofing models.
The key finding is that it is indeed possible to generate adversarial examples that can fool both types of models simultaneously. This means that a real person's face could potentially be modified in a way that allows them to bypass both the identification and the liveness detection components of a secure facial authentication system.
This has important implications for the security of face-based authentication. It suggests that these systems may be vulnerable to more sophisticated attacks than previously thought, and that more work is needed to improve their robustness against adversarial examples.
Technical Explanation
The paper first reviews related work on adversarial attacks against face recognition and face anti-spoofing models. The researchers then propose a novel optimization-based attack method that can generate adversarial examples to fool both types of models at the same time.
The key idea is to formulate a single objective function that captures the goals of both types of attacks. This allows the optimization process to find a perturbation to the input image that minimizes the face recognition score while also maximizing the face anti-spoofing score, tricking both models.
The researchers evaluate their attack method on several state-of-the-art face recognition and face anti-spoofing models, including FaceNet, SphereFace, and ArcFace for face recognition, and PFE, FAS-TD, and CDCN for face anti-spoofing. The results show that the proposed attack can achieve a high success rate in fooling both types of models simultaneously.
Additionally, the paper investigates the transferability of the adversarial examples, finding that they can often be used to attack different models, even those with different architectures.
Critical Analysis
The paper provides a thorough investigation of the potential vulnerabilities of combined face recognition and anti-spoofing systems to adversarial attacks. The proposed attack method is well-designed and the experimental results are compelling.
However, the paper does not address potential mitigations or defenses against such attacks. Future work could explore techniques to improve the robustness of these systems, such as adversarial training or specialized defenses.
Additionally, the paper focuses on digital adversarial examples, but does not consider physical-world attacks, which may pose additional challenges. Investigating the feasibility of physical adversarial attacks on face recognition and anti-spoofing systems would be a valuable extension of this work.
Conclusion
This paper presents an important study on the security implications of adversarial attacks that can simultaneously target both face recognition and face anti-spoofing models. The findings suggest that these systems may be more vulnerable than previously thought, and highlight the need for continued research into improving their robustness against sophisticated attacks.
As face-based authentication becomes more widespread, understanding and addressing these types of vulnerabilities will be crucial for maintaining the security and trustworthiness of these systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Adversarial Attacks on Both Face Recognition and Face Anti-spoofing Models
Fengfan Zhou, Qianyu Zhou, Xiangtai Li, Xuequan Lu, Lizhuang Ma, Hefei Ling
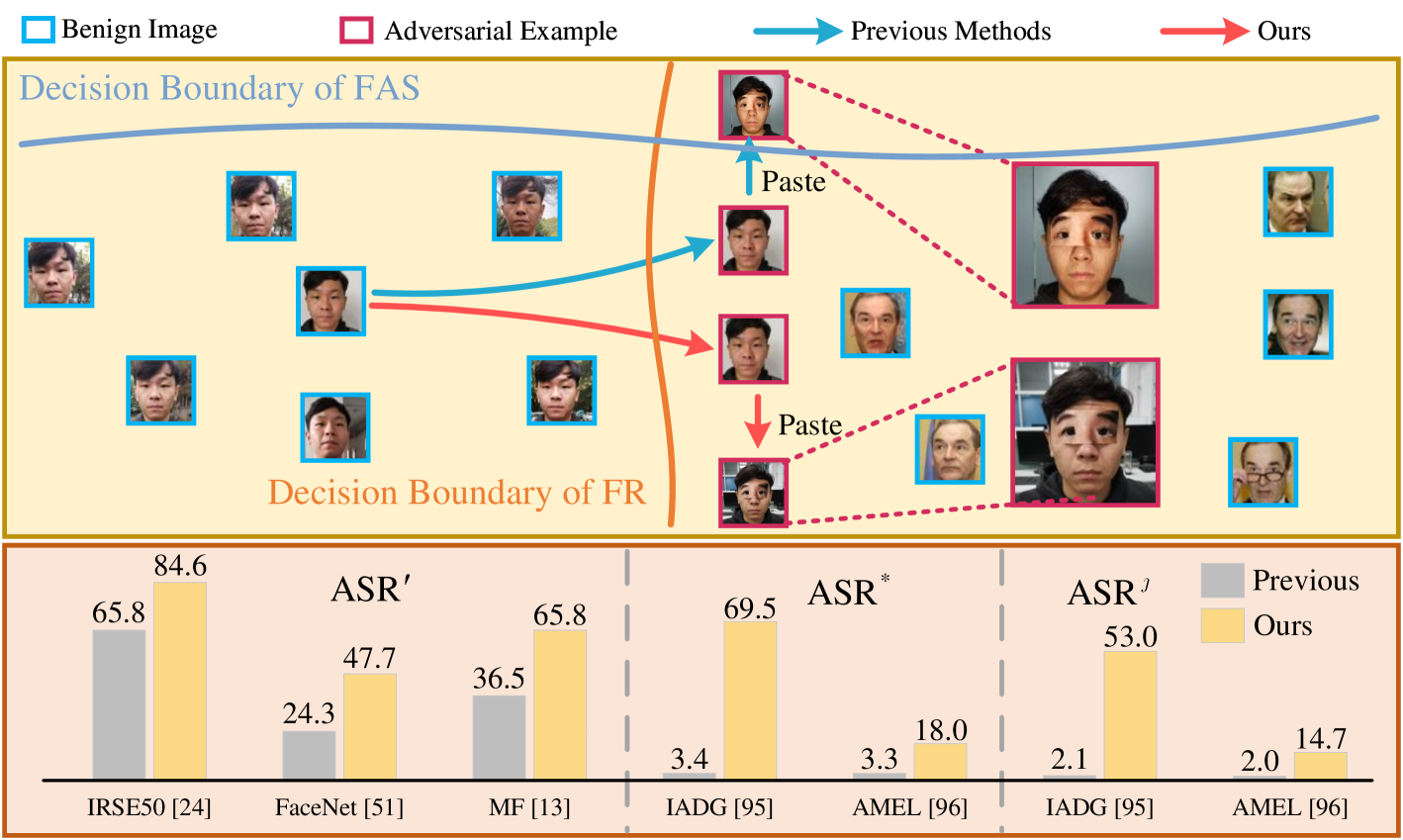
Adversarial attacks on Face Recognition (FR) systems have proven highly effective in compromising pure FR models, yet adversarial examples may be ineffective to the complete FR systems as Face Anti-Spoofing (FAS) models are often incorporated and can detect a significant number of them. To address this under-explored and essential problem, we propose a novel setting of adversarially attacking both FR and FAS models simultaneously, aiming to enhance the practicability of adversarial attacks on FR systems. In particular, we introduce a new attack method, namely Style-aligned Distribution Biasing (SDB), to improve the capacity of black-box attacks on both FR and FAS models. Specifically, our SDB framework consists of three key components. Firstly, to enhance the transferability of FAS models, we design a Distribution-aware Score Biasing module to optimize adversarial face examples away from the distribution of spoof images utilizing scores. Secondly, to mitigate the substantial style differences between live images and adversarial examples initialized with spoof images, we introduce an Instance Style Alignment module that aligns the style of adversarial examples with live images. In addition, to alleviate the conflicts between the gradients of FR and FAS models, we propose a Gradient Consistency Maintenance module to minimize disparities between the gradients using Hessian approximation. Extensive experiments showcase the superiority of our proposed attack method to state-of-the-art adversarial attacks.
Read more5/28/2024

0
DiffFAS: Face Anti-Spoofing via Generative Diffusion Models
Xinxu Ge, Xin Liu, Zitong Yu, Jingang Shi, Chun Qi, Jie Li, Heikki Kalviainen
Face anti-spoofing (FAS) plays a vital role in preventing face recognition (FR) systems from presentation attacks. Nowadays, FAS systems face the challenge of domain shift, impacting the generalization performance of existing FAS methods. In this paper, we rethink about the inherence of domain shift and deconstruct it into two factors: image style and image quality. Quality influences the purity of the presentation of spoof information, while style affects the manner in which spoof information is presented. Based on our analysis, we propose DiffFAS framework, which quantifies quality as prior information input into the network to counter image quality shift, and performs diffusion-based high-fidelity cross-domain and cross-attack types generation to counter image style shift. DiffFAS transforms easily collectible live faces into high-fidelity attack faces with precise labels while maintaining consistency between live and spoof face identities, which can also alleviate the scarcity of labeled data with novel type attacks faced by nowadays FAS system. We demonstrate the effectiveness of our framework on challenging cross-domain and cross-attack FAS datasets, achieving the state-of-the-art performance. Available at https://github.com/murphytju/DiffFAS.
Read more9/16/2024
0
Rethinking Impersonation and Dodging Attacks on Face Recognition Systems
Fengfan Zhou, Qianyu Zhou, Bangjie Yin, Hui Zheng, Xuequan Lu, Lizhuang Ma, Hefei Ling
Face Recognition (FR) systems can be easily deceived by adversarial examples that manipulate benign face images through imperceptible perturbations. Adversarial attacks on FR encompass two types: impersonation (targeted) attacks and dodging (untargeted) attacks. Previous methods often achieve a successful impersonation attack on FR, however, it does not necessarily guarantee a successful dodging attack on FR in the black-box setting. In this paper, our key insight is that the generation of adversarial examples should perform both impersonation and dodging attacks simultaneously. To this end, we propose a novel attack method termed as Adversarial Pruning (Adv-Pruning), to fine-tune existing adversarial examples to enhance their dodging capabilities while preserving their impersonation capabilities. Adv-Pruning consists of Priming, Pruning, and Restoration stages. Concretely, we propose Adversarial Priority Quantification to measure the region-wise priority of original adversarial perturbations, identifying and releasing those with minimal impact on absolute model output variances. Then, Biased Gradient Adaptation is presented to adapt the adversarial examples to traverse the decision boundaries of both the attacker and victim by adding perturbations favoring dodging attacks on the vacated regions, preserving the prioritized features of the original perturbations while boosting dodging performance. As a result, we can maintain the impersonation capabilities of original adversarial examples while effectively enhancing dodging capabilities. Comprehensive experiments demonstrate the superiority of our method compared with state-of-the-art adversarial attack methods.
Read more8/20/2024
0
Towards Data-Centric Face Anti-Spoofing: Improving Cross-domain Generalization via Physics-based Data Synthesis
Rizhao Cai, Cecelia Soh, Zitong Yu, Haoliang Li, Wenhan Yang, Alex Kot
Face Anti-Spoofing (FAS) research is challenged by the cross-domain problem, where there is a domain gap between the training and testing data. While recent FAS works are mainly model-centric, focusing on developing domain generalization algorithms for improving cross-domain performance, data-centric research for face anti-spoofing, improving generalization from data quality and quantity, is largely ignored. Therefore, our work starts with data-centric FAS by conducting a comprehensive investigation from the data perspective for improving cross-domain generalization of FAS models. More specifically, at first, based on physical procedures of capturing and recapturing, we propose task-specific FAS data augmentation (FAS-Aug), which increases data diversity by synthesizing data of artifacts, such as printing noise, color distortion, moir'e pattern, textit{etc}. Our experiments show that using our FAS augmentation can surpass traditional image augmentation in training FAS models to achieve better cross-domain performance. Nevertheless, we observe that models may rely on the augmented artifacts, which are not environment-invariant, and using FAS-Aug may have a negative effect. As such, we propose Spoofing Attack Risk Equalization (SARE) to prevent models from relying on certain types of artifacts and improve the generalization performance. Last but not least, our proposed FAS-Aug and SARE with recent Vision Transformer backbones can achieve state-of-the-art performance on the FAS cross-domain generalization protocols. The implementation is available at https://github.com/RizhaoCai/FAS_Aug.
Read more9/6/2024