Diffusion-based image inpainting with internal learning
2406.04206
0
0
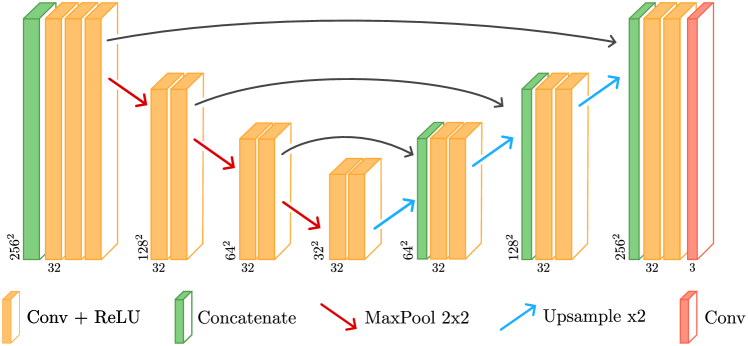
Abstract
Diffusion models are now the undisputed state-of-the-art for image generation and image restoration. However, they require large amounts of computational power for training and inference. In this paper, we propose lightweight diffusion models for image inpainting that can be trained on a single image, or a few images. We show that our approach competes with large state-of-the-art models in specific cases. We also show that training a model on a single image is particularly relevant for image acquisition modality that differ from the RGB images of standard learning databases. We show results in three different contexts: texture images, line drawing images, and materials BRDF, for which we achieve state-of-the-art results in terms of realism, with a computational load that is greatly reduced compared to concurrent methods.
Create account to get full access
Overview
- This paper presents a novel diffusion-based method for image inpainting, where missing or corrupted regions of an image are filled in using a single input image.
- The key innovation is the use of "internal learning," which leverages the structure and patterns within the input image itself to guide the inpainting process, rather than relying on external training data.
- The method is shown to produce high-quality inpainting results on a variety of image types and corruption scenarios.
Plain English Explanation
The paper describes a new way to fill in missing or damaged parts of an image using a diffusion-based inpainting approach. Normally, this type of inpainting would require a large dataset of example images to learn from.
However, this new method is able to do the inpainting using only the single input image itself. It does this by internally learning the patterns and structures that are already present in the image, and then using that knowledge to intelligently fill in the missing regions.
This is a clever approach that can produce high-quality inpainted results without needing a big training dataset. It could be useful for tasks like restoring old photos, repairing damaged images, or removing unwanted objects from photos.
Technical Explanation
The core of the method is a diffusion model that is trained to progressively add noise to the input image, and then learn to reverse that noising process to generate plausible completions of the missing regions.
Rather than relying on external training data, the diffusion model is internally trained using only the structure and patterns present in the single input image. This allows the model to capture the unique characteristics of that particular image and use them to guide the inpainting.
The authors demonstrate the effectiveness of their approach through extensive experiments on a variety of inpainting tasks and image types. They show that their method can outperform previous state-of-the-art inpainting techniques, especially in cases where the missing regions are large or the image content is complex.
Critical Analysis
One potential limitation of the approach is that it may struggle with highly diverse or uncommon image content that is not well-represented within the single input image. In such cases, the internal learning process may not be able to capture all the necessary visual information to perform accurate inpainting.
Additionally, the computational cost of the diffusion-based inpainting process could be higher than simpler, more traditional inpainting methods, especially for large image resolutions or complex inpainting tasks. This is an area that may require further optimization to make the technique more practical for real-world applications.
Overall, the paper presents a compelling and novel approach to image inpainting that leverages the power of diffusion models and internal learning to produce high-quality results. The technique opens up interesting avenues for further research and development in this important computer vision domain.
Conclusion
This paper introduces a diffusion-based image inpainting method that uses internal learning to generate plausible completions of missing or corrupted regions in a single input image. By training the diffusion model on the patterns and structures present in the input image itself, rather than relying on external training data, the technique is able to produce high-quality inpainting results without the need for a large dataset.
The authors demonstrate the effectiveness of their approach through extensive experiments, showing that it can outperform previous state-of-the-art inpainting methods, especially in challenging cases with large missing regions or complex image content. While the technique may have some limitations in terms of computational cost and handling highly diverse image content, it represents an exciting advancement in the field of image inpainting and could find useful applications in various real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Streamlining Image Editing with Layered Diffusion Brushes
Peyman Gholami, Robert Xiao
0
0
Denoising diffusion models have recently gained prominence as powerful tools for a variety of image generation and manipulation tasks. Building on this, we propose a novel tool for real-time editing of images that provides users with fine-grained region-targeted supervision in addition to existing prompt-based controls. Our novel editing technique, termed Layered Diffusion Brushes, leverages prompt-guided and region-targeted alteration of intermediate denoising steps, enabling precise modifications while maintaining the integrity and context of the input image. We provide an editor based on Layered Diffusion Brushes modifications, which incorporates well-known image editing concepts such as layer masks, visibility toggles, and independent manipulation of layers; regardless of their order. Our system renders a single edit on a 512x512 image within 140 ms using a high-end consumer GPU, enabling real-time feedback and rapid exploration of candidate edits. We validated our method and editing system through a user study involving both natural images (using inversion) and generated images, showcasing its usability and effectiveness compared to existing techniques such as InstructPix2Pix and Stable Diffusion Inpainting for refining images. Our approach demonstrates efficacy across a range of tasks, including object attribute adjustments, error correction, and sequential prompt-based object placement and manipulation, demonstrating its versatility and potential for enhancing creative workflows.
5/2/2024
📶
Semantically Consistent Video Inpainting with Conditional Diffusion Models
Dylan Green, William Harvey, Saeid Naderiparizi, Matthew Niedoba, Yunpeng Liu, Xiaoxuan Liang, Jonathan Lavington, Ke Zhang, Vasileios Lioutas, Setareh Dabiri, Adam Scibior, Berend Zwartsenberg, Frank Wood
0
0
Current state-of-the-art methods for video inpainting typically rely on optical flow or attention-based approaches to inpaint masked regions by propagating visual information across frames. While such approaches have led to significant progress on standard benchmarks, they struggle with tasks that require the synthesis of novel content that is not present in other frames. In this paper we reframe video inpainting as a conditional generative modeling problem and present a framework for solving such problems with conditional video diffusion models. We highlight the advantages of using a generative approach for this task, showing that our method is capable of generating diverse, high-quality inpaintings and synthesizing new content that is spatially, temporally, and semantically consistent with the provided context.
5/2/2024
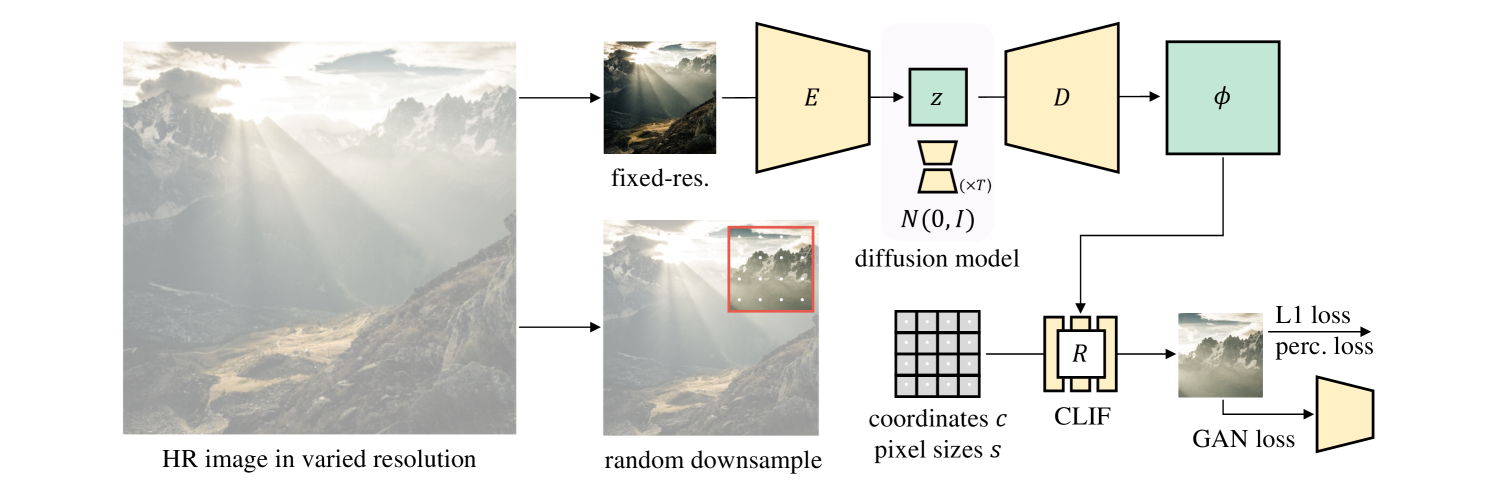
Image Neural Field Diffusion Models
Yinbo Chen, Oliver Wang, Richard Zhang, Eli Shechtman, Xiaolong Wang, Michael Gharbi
0
0
Diffusion models have shown an impressive ability to model complex data distributions, with several key advantages over GANs, such as stable training, better coverage of the training distribution's modes, and the ability to solve inverse problems without extra training. However, most diffusion models learn the distribution of fixed-resolution images. We propose to learn the distribution of continuous images by training diffusion models on image neural fields, which can be rendered at any resolution, and show its advantages over fixed-resolution models. To achieve this, a key challenge is to obtain a latent space that represents photorealistic image neural fields. We propose a simple and effective method, inspired by several recent techniques but with key changes to make the image neural fields photorealistic. Our method can be used to convert existing latent diffusion autoencoders into image neural field autoencoders. We show that image neural field diffusion models can be trained using mixed-resolution image datasets, outperform fixed-resolution diffusion models followed by super-resolution models, and can solve inverse problems with conditions applied at different scales efficiently.
6/12/2024

Plug-and-Play Diffusion Distillation
Yi-Ting Hsiao, Siavash Khodadadeh, Kevin Duarte, Wei-An Lin, Hui Qu, Mingi Kwon, Ratheesh Kalarot
0
0
Diffusion models have shown tremendous results in image generation. However, due to the iterative nature of the diffusion process and its reliance on classifier-free guidance, inference times are slow. In this paper, we propose a new distillation approach for guided diffusion models in which an external lightweight guide model is trained while the original text-to-image model remains frozen. We show that our method reduces the inference computation of classifier-free guided latent-space diffusion models by almost half, and only requires 1% trainable parameters of the base model. Furthermore, once trained, our guide model can be applied to various fine-tuned, domain-specific versions of the base diffusion model without the need for additional training: this plug-and-play functionality drastically improves inference computation while maintaining the visual fidelity of generated images. Empirically, we show that our approach is able to produce visually appealing results and achieve a comparable FID score to the teacher with as few as 8 to 16 steps.
6/17/2024