Image Neural Field Diffusion Models
2406.07480
0
1
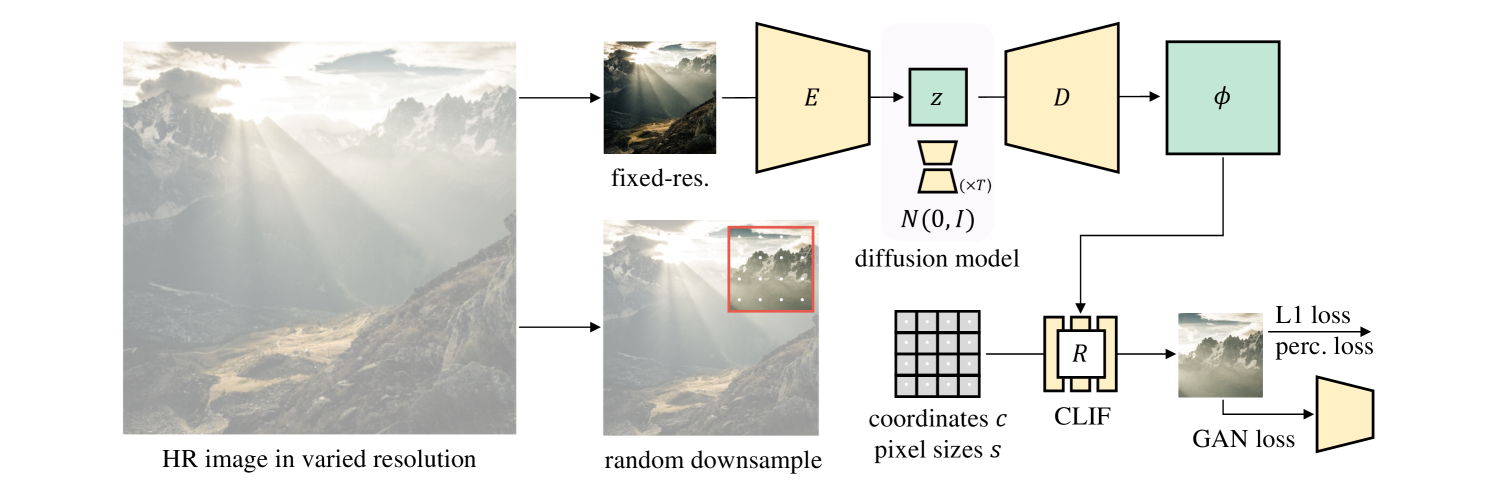
Abstract
Diffusion models have shown an impressive ability to model complex data distributions, with several key advantages over GANs, such as stable training, better coverage of the training distribution's modes, and the ability to solve inverse problems without extra training. However, most diffusion models learn the distribution of fixed-resolution images. We propose to learn the distribution of continuous images by training diffusion models on image neural fields, which can be rendered at any resolution, and show its advantages over fixed-resolution models. To achieve this, a key challenge is to obtain a latent space that represents photorealistic image neural fields. We propose a simple and effective method, inspired by several recent techniques but with key changes to make the image neural fields photorealistic. Our method can be used to convert existing latent diffusion autoencoders into image neural field autoencoders. We show that image neural field diffusion models can be trained using mixed-resolution image datasets, outperform fixed-resolution diffusion models followed by super-resolution models, and can solve inverse problems with conditions applied at different scales efficiently.
Create account to get full access
Overview
- Introduces a new class of diffusion models called Image Neural Field Diffusion Models (INFDMs) that can generate high-quality images by diffusing a Gaussian noise signal into a neural field representation.
- Explores the use of neural fields to model the image generation process, which can capture complex spatial and semantic relationships.
- Demonstrates the effectiveness of INFDMs in various image generation tasks, including image synthesis, inpainting, and super-resolution.
Plain English Explanation
Image Neural Field Diffusion Models (INFDMs) are a type of diffusion model that can create high-quality images. These models work by taking a random noise signal and gradually transforming it into a detailed image.
The key innovation of INFDMs is the use of a "neural field" to represent the image. A neural field is a way of modeling complex, interconnected relationships in an image, like the spatial arrangement of objects and their semantic meaning. By using a neural field, INFDMs can capture these intricate patterns and generate images that are both visually appealing and semantically coherent.
INFDMs have shown promising results in a variety of image generation tasks, such as image synthesis, image inpainting, and super-resolution. By leveraging the power of neural fields, these models can produce high-quality images that are difficult to distinguish from real ones.
Technical Explanation
The key technical innovation of Image Neural Field Diffusion Models (INFDMs) is the use of a neural field representation to model the image generation process. This allows the model to capture complex spatial and semantic relationships within the image, going beyond the limitations of traditional pixel-based image generation approaches.
The INFDN architecture consists of a diffusion network that gradually transforms a Gaussian noise signal into a neural field representation of the desired image. This neural field is a continuous, high-dimensional function that encodes the spatial layout, object semantics, and other relevant image properties. By diffusing the noise signal into this neural field, the model can generate images with a high degree of fidelity and coherence.
The researchers demonstrate the effectiveness of INFDMs in various image generation tasks, such as image synthesis, image inpainting, and super-resolution. In these experiments, the INFDN models are able to generate visually appealing and semantically meaningful images, outperforming previous state-of-the-art diffusion-based approaches.
Critical Analysis
The Image Neural Field Diffusion Models (INFDMs) presented in this paper represent a promising advancement in the field of diffusion-based image generation. The use of neural fields to model the image generation process is a novel and compelling approach that allows the models to capture complex spatial and semantic relationships.
However, the paper does not extensively discuss the limitations and potential drawbacks of this approach. For instance, the computational complexity and training requirements of the neural field representation are not thoroughly addressed. Additionally, the paper does not explore the interpretability and robustness of the generated images, which are important considerations for real-world applications.
Further research is needed to fully understand the capabilities and limitations of INFDMs, as well as to explore potential extensions and improvements to the core methodology. Nonetheless, the promising results demonstrated in this paper suggest that the use of neural fields in diffusion models is a fruitful area of exploration for the image generation community.
Conclusion
The Image Neural Field Diffusion Models (INFDMs) presented in this paper introduce a novel approach to diffusion-based image generation. By leveraging neural fields to model the image generation process, INFDMs are able to capture complex spatial and semantic relationships, leading to the generation of high-quality, visually appealing, and semantically coherent images.
The demonstrated effectiveness of INFDMs in various image generation tasks, such as image synthesis, image inpainting, and super-resolution, suggests that this approach has the potential to significantly advance the state of the art in diffusion-based image generation. Further research and exploration of the limitations and potential extensions of INFDMs will be crucial for unlocking the full potential of this promising new class of models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

DiffuseHigh: Training-free Progressive High-Resolution Image Synthesis through Structure Guidance
Younghyun Kim, Geunmin Hwang, Eunbyung Park
0
0
Recent surge in large-scale generative models has spurred the development of vast fields in computer vision. In particular, text-to-image diffusion models have garnered widespread adoption across diverse domain due to their potential for high-fidelity image generation. Nonetheless, existing large-scale diffusion models are confined to generate images of up to 1K resolution, which is far from meeting the demands of contemporary commercial applications. Directly sampling higher-resolution images often yields results marred by artifacts such as object repetition and distorted shapes. Addressing the aforementioned issues typically necessitates training or fine-tuning models on higher resolution datasets. However, this undertaking poses a formidable challenge due to the difficulty in collecting large-scale high-resolution contents and substantial computational resources. While several preceding works have proposed alternatives, they often fail to produce convincing results. In this work, we probe the generative ability of diffusion models at higher resolution beyond its original capability and propose a novel progressive approach that fully utilizes generated low-resolution image to guide the generation of higher resolution image. Our method obviates the need for additional training or fine-tuning which significantly lowers the burden of computational costs. Extensive experiments and results validate the efficiency and efficacy of our method.
6/27/2024
🧠
Neural Diffusion Models
Grigory Bartosh, Dmitry Vetrov, Christian A. Naesseth
0
0
Diffusion models have shown remarkable performance on many generative tasks. Despite recent success, most diffusion models are restricted in that they only allow linear transformation of the data distribution. In contrast, broader family of transformations can potentially help train generative distributions more efficiently, simplifying the reverse process and closing the gap between the true negative log-likelihood and the variational approximation. In this paper, we present Neural Diffusion Models (NDMs), a generalization of conventional diffusion models that enables defining and learning time-dependent non-linear transformations of data. We show how to optimise NDMs using a variational bound in a simulation-free setting. Moreover, we derive a time-continuous formulation of NDMs, which allows fast and reliable inference using off-the-shelf numerical ODE and SDE solvers. Finally, we demonstrate the utility of NDMs with learnable transformations through experiments on standard image generation benchmarks, including CIFAR-10, downsampled versions of ImageNet and CelebA-HQ. NDMs outperform conventional diffusion models in terms of likelihood and produce high-quality samples.
6/4/2024

Neural Network Parameter Diffusion
Kai Wang, Zhaopan Xu, Yukun Zhou, Zelin Zang, Trevor Darrell, Zhuang Liu, Yang You
0
0
Diffusion models have achieved remarkable success in image and video generation. In this work, we demonstrate that diffusion models can also textit{generate high-performing neural network parameters}. Our approach is simple, utilizing an autoencoder and a standard latent diffusion model. The autoencoder extracts latent representations of a subset of the trained network parameters. A diffusion model is then trained to synthesize these latent parameter representations from random noise. It then generates new representations that are passed through the autoencoder's decoder, whose outputs are ready to use as new subsets of network parameters. Across various architectures and datasets, our diffusion process consistently generates models of comparable or improved performance over trained networks, with minimal additional cost. Notably, we empirically find that the generated models are not memorizing the trained networks. Our results encourage more exploration on the versatile use of diffusion models.
5/29/2024

Neural Residual Diffusion Models for Deep Scalable Vision Generation
Zhiyuan Ma, Liangliang Zhao, Biqing Qi, Bowen Zhou
0
0
The most advanced diffusion models have recently adopted increasingly deep stacked networks (e.g., U-Net or Transformer) to promote the generative emergence capabilities of vision generation models similar to large language models (LLMs). However, progressively deeper stacked networks will intuitively cause numerical propagation errors and reduce noisy prediction capabilities on generative data, which hinders massively deep scalable training of vision generation models. In this paper, we first uncover the nature that neural networks being able to effectively perform generative denoising lies in the fact that the intrinsic residual unit has consistent dynamic property with the input signal's reverse diffusion process, thus supporting excellent generative abilities. Afterwards, we stand on the shoulders of two common types of deep stacked networks to propose a unified and massively scalable Neural Residual Diffusion Models framework (Neural-RDM for short), which is a simple yet meaningful change to the common architecture of deep generative networks by introducing a series of learnable gated residual parameters that conform to the generative dynamics. Experimental results on various generative tasks show that the proposed neural residual models obtain state-of-the-art scores on image's and video's generative benchmarks. Rigorous theoretical proofs and extensive experiments also demonstrate the advantages of this simple gated residual mechanism consistent with dynamic modeling in improving the fidelity and consistency of generated content and supporting large-scale scalable training. Code is available at https://github.com/Anonymous/Neural-RDM.
6/21/2024