Semantically Consistent Video Inpainting with Conditional Diffusion Models
2405.00251
0
1
📶
Abstract
Current state-of-the-art methods for video inpainting typically rely on optical flow or attention-based approaches to inpaint masked regions by propagating visual information across frames. While such approaches have led to significant progress on standard benchmarks, they struggle with tasks that require the synthesis of novel content that is not present in other frames. In this paper we reframe video inpainting as a conditional generative modeling problem and present a framework for solving such problems with conditional video diffusion models. We highlight the advantages of using a generative approach for this task, showing that our method is capable of generating diverse, high-quality inpaintings and synthesizing new content that is spatially, temporally, and semantically consistent with the provided context.
Create account to get full access
Overview
- Current video inpainting methods rely on optical flow or attention-based approaches to propagate visual information across frames
- These approaches struggle with tasks that require the synthesis of novel content not present in other frames
- This paper reframes video inpainting as a conditional generative modeling problem and presents a framework for solving it with conditional video diffusion models
- The authors highlight the advantages of using a generative approach, showing their method can generate diverse, high-quality inpaintings and synthesize new content that is consistent with the provided context
Plain English Explanation
The paper is about a new way to fill in missing parts of videos. Typical methods for this task, called "video inpainting," use techniques like optical flow or attention to copy information from other parts of the video. While this works well for some tasks, it struggles when you need to create new content that doesn't exist elsewhere in the video.
The researchers propose reframing video inpainting as a "conditional generative modeling" problem. This means they're using a machine learning model that can generate new video content, but it's "conditioned" on the existing parts of the video. Their framework uses a special type of generative model called a "diffusion model" (sketch-guided image inpainting, reffusion).
The key advantage of this generative approach is that it can create diverse, high-quality inpaintings that seamlessly fit the spatial, temporal, and semantic context of the video. Rather than just copying from elsewhere, the model can synthesize new content that logically belongs in the missing parts.
Technical Explanation
The paper presents a framework for solving video inpainting using conditional video diffusion models. Diffusion models are a type of generative model that work by adding noise to an input and then learning to reverse that noising process to generate new samples.
In this case, the input to the diffusion model is the partially-observed video frames with masked regions, and the model is trained to generate plausible content to fill in those missing parts. The model is "conditional" in the sense that the generation is guided by the available video context.
The authors demonstrate that this generative approach outperforms previous state-of-the-art optical flow and attention-based methods on standard video inpainting benchmarks. Their model is able to synthesize novel content that is spatially, temporally, and semantically consistent with the provided context.
Critical Analysis
The paper provides a compelling case for reframing video inpainting as a conditional generative modeling problem. The authors show that their diffusion-based approach can generate diverse, high-quality inpaintings that go beyond simply copying information from other frames.
However, the evaluation is limited to standard video inpainting benchmarks, and it's not clear how the method would scale to more complex, real-world video editing tasks. Additionally, the paper does not deeply explore the limitations or failure cases of the proposed framework.
Further research could investigate how this generative approach handles videos with more drastic changes in content, occlusions, or camera motion. There may also be opportunities to combine the strengths of flow-based and generative techniques to create even more robust and versatile video inpainting models.
Overall, this work represents an interesting step forward in using powerful generative modeling techniques to tackle challenging video editing problems. But as with any new research, there is still room for refinement and expansion of the ideas presented here.
Conclusion
This paper introduces a novel framework for video inpainting that reframes the problem as a conditional generative modeling task. By using a diffusion-based generative model, the proposed approach can synthesize diverse, high-quality inpaintings that are spatially, temporally, and semantically consistent with the provided video context.
The key advantage of this generative approach is that it can create new content rather than simply copying from other parts of the video. This allows the model to handle a broader range of inpainting challenges compared to traditional optical flow or attention-based methods.
While the evaluation is limited to standard benchmarks, this work represents an exciting step forward in using powerful machine learning techniques to enable more sophisticated video editing capabilities. Further research could explore how to scale these ideas to real-world applications and combine them with other complementary approaches.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
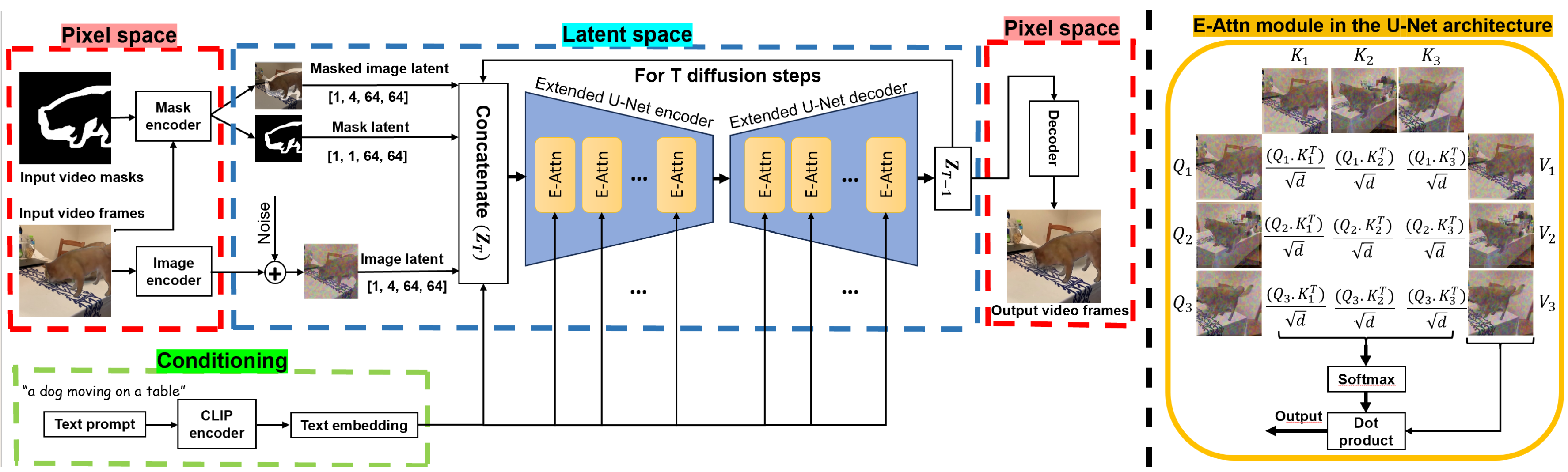
Temporally Consistent Object Editing in Videos using Extended Attention
AmirHossein Zamani, Amir G. Aghdam, Tiberiu Popa, Eugene Belilovsky
0
0
Image generation and editing have seen a great deal of advancements with the rise of large-scale diffusion models that allow user control of different modalities such as text, mask, depth maps, etc. However, controlled editing of videos still lags behind. Prior work in this area has focused on using 2D diffusion models to globally change the style of an existing video. On the other hand, in many practical applications, editing localized parts of the video is critical. In this work, we propose a method to edit videos using a pre-trained inpainting image diffusion model. We systematically redesign the forward path of the model by replacing the self-attention modules with an extended version of attention modules that creates frame-level dependencies. In this way, we ensure that the edited information will be consistent across all the video frames no matter what the shape and position of the masked area is. We qualitatively compare our results with state-of-the-art in terms of accuracy on several video editing tasks like object retargeting, object replacement, and object removal tasks. Simulations demonstrate the superior performance of the proposed strategy.
6/4/2024
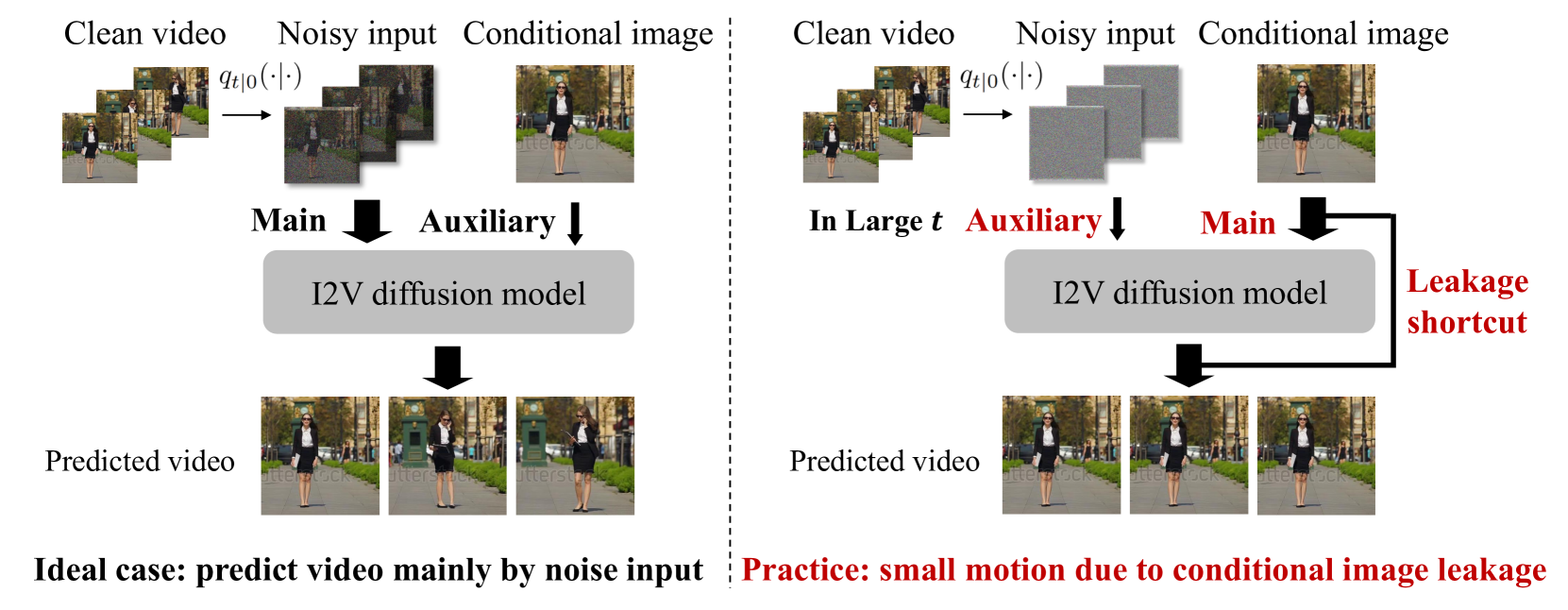
Identifying and Solving Conditional Image Leakage in Image-to-Video Diffusion Model
Min Zhao, Hongzhou Zhu, Chendong Xiang, Kaiwen Zheng, Chongxuan Li, Jun Zhu
0
0
Diffusion models have obtained substantial progress in image-to-video (I2V) generation. However, such models are not fully understood. In this paper, we report a significant but previously overlooked issue in I2V diffusion models (I2V-DMs), namely, conditional image leakage. I2V-DMs tend to over-rely on the conditional image at large time steps, neglecting the crucial task of predicting the clean video from noisy inputs, which results in videos lacking dynamic and vivid motion. We further address this challenge from both inference and training aspects by presenting plug-and-play strategies accordingly. First, we introduce a training-free inference strategy that starts the generation process from an earlier time step to avoid the unreliable late-time steps of I2V-DMs, as well as an initial noise distribution with optimal analytic expressions (Analytic-Init) by minimizing the KL divergence between it and the actual marginal distribution to effectively bridge the training-inference gap. Second, to mitigate conditional image leakage during training, we design a time-dependent noise distribution for the conditional image, which favors high noise levels at large time steps to sufficiently interfere with the conditional image. We validate these strategies on various I2V-DMs using our collected open-domain image benchmark and the UCF101 dataset. Extensive results demonstrate that our methods outperform baselines by producing videos with more dynamic and natural motion without compromising image alignment and temporal consistency. The project page: url{https://cond-image-leak.github.io/}.
6/26/2024
Diffusion-based image inpainting with internal learning
Nicolas Cherel, Andr'es Almansa, Yann Gousseau, Alasdair Newson
0
0
Diffusion models are now the undisputed state-of-the-art for image generation and image restoration. However, they require large amounts of computational power for training and inference. In this paper, we propose lightweight diffusion models for image inpainting that can be trained on a single image, or a few images. We show that our approach competes with large state-of-the-art models in specific cases. We also show that training a model on a single image is particularly relevant for image acquisition modality that differ from the RGB images of standard learning databases. We show results in three different contexts: texture images, line drawing images, and materials BRDF, for which we achieve state-of-the-art results in terms of realism, with a computational load that is greatly reduced compared to concurrent methods.
6/7/2024

StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation
Yupeng Zhou, Daquan Zhou, Ming-Ming Cheng, Jiashi Feng, Qibin Hou
0
0
For recent diffusion-based generative models, maintaining consistent content across a series of generated images, especially those containing subjects and complex details, presents a significant challenge. In this paper, we propose a new way of self-attention calculation, termed Consistent Self-Attention, that significantly boosts the consistency between the generated images and augments prevalent pretrained diffusion-based text-to-image models in a zero-shot manner. To extend our method to long-range video generation, we further introduce a novel semantic space temporal motion prediction module, named Semantic Motion Predictor. It is trained to estimate the motion conditions between two provided images in the semantic spaces. This module converts the generated sequence of images into videos with smooth transitions and consistent subjects that are significantly more stable than the modules based on latent spaces only, especially in the context of long video generation. By merging these two novel components, our framework, referred to as StoryDiffusion, can describe a text-based story with consistent images or videos encompassing a rich variety of contents. The proposed StoryDiffusion encompasses pioneering explorations in visual story generation with the presentation of images and videos, which we hope could inspire more research from the aspect of architectural modifications. Our code is made publicly available at https://github.com/HVision-NKU/StoryDiffusion.
5/3/2024