Diffusion-Driven Data Replay: A Novel Approach to Combat Forgetting in Federated Class Continual Learning

0

Sign in to get full access
Overview
- This paper proposes a novel approach called "Diffusion-Driven Data Replay" to address the problem of catastrophic forgetting in federated class continual learning.
- The key idea is to use a diffusion model to generate samples of past classes, which are then used to continually train the model and prevent forgetting.
- The approach is evaluated on benchmark continual learning datasets and shows significant improvements over existing methods.
Plain English Explanation
In machine learning, a common challenge is catastrophic forgetting. This refers to the tendency of a model to forget how to perform previous tasks as it is trained on new tasks. For example, if you train an image classification model to recognize cats and dogs, and then train it to recognize birds and rabbits, it may start to perform poorly on the cat and dog classification.
The paper introduces a new technique called Diffusion-Driven Data Replay to address this problem. The key idea is to use a diffusion model to generate samples of the past classes (e.g., cats and dogs) and then use those generated samples to continually train the model. This helps the model retain the knowledge it learned previously, while also acquiring new knowledge.
The advantage of this approach is that it doesn't require storing the actual training data from the past, which can be memory-intensive. Instead, the diffusion model can generate realistic-looking samples on-the-fly, which are then used for training.
The paper evaluates this approach on standard benchmarks for continual learning and shows that it outperforms existing methods in terms of preventing catastrophic forgetting.
Technical Explanation
The paper introduces a novel approach called Diffusion-Driven Data Replay (D2R) to address the problem of catastrophic forgetting in federated class continual learning.
The core idea is to use a diffusion model to generate samples of past classes, which are then used to continually train the main classification model. This helps the model retain the knowledge it learned previously, while also acquiring new knowledge.
Specifically, the authors train a diffusion model on the data from the past classes. This diffusion model can then be used to generate new samples of those past classes on-the-fly, without the need to store the original training data. These generated samples are then used in a replay buffer to continually train the main classification model.
The authors evaluate this approach on benchmark continual learning datasets, including iCIFAR100 and CORe50. They show that D2R significantly outperforms existing methods in terms of preventing catastrophic forgetting and maintaining high performance on both past and new tasks.
Critical Analysis
The paper presents a compelling approach to addressing the challenge of catastrophic forgetting in continual learning. The use of a diffusion model to generate samples of past classes is a novel and promising idea, as it avoids the need to store large amounts of training data.
One potential limitation of the approach is the computational cost of training the diffusion model, which can be resource-intensive. The authors do not provide a detailed analysis of the training time and memory requirements of their approach compared to other methods.
Additionally, the paper does not explore the impact of the quality of the generated samples on the performance of the main classification model. It would be interesting to see how the approach performs when the diffusion model is not able to generate high-quality samples of the past classes.
Another area for further research could be the integration of the D2R approach with other continual learning techniques, such as rehearsal-based or meta-learning methods, to potentially further improve the performance and robustness of the system.
Conclusion
The paper presents a novel approach called Diffusion-Driven Data Replay (D2R) to address the problem of catastrophic forgetting in federated class continual learning. By using a diffusion model to generate samples of past classes, the approach is able to continually train the main classification model and prevent it from forgetting previous knowledge.
The evaluation results show that D2R significantly outperforms existing methods on standard continual learning benchmarks. While the approach has some potential limitations, it represents an important step forward in addressing one of the key challenges in continual learning.
Overall, the paper demonstrates the potential of diffusion models to play a key role in developing more robust and adaptive machine learning systems that can continually learn and adapt over time.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Diffusion-Driven Data Replay: A Novel Approach to Combat Forgetting in Federated Class Continual Learning
Jinglin Liang, Jin Zhong, Hanlin Gu, Zhongqi Lu, Xingxing Tang, Gang Dai, Shuangping Huang, Lixin Fan, Qiang Yang
Federated Class Continual Learning (FCCL) merges the challenges of distributed client learning with the need for seamless adaptation to new classes without forgetting old ones. The key challenge in FCCL is catastrophic forgetting, an issue that has been explored to some extent in Continual Learning (CL). However, due to privacy preservation requirements, some conventional methods, such as experience replay, are not directly applicable to FCCL. Existing FCCL methods mitigate forgetting by generating historical data through federated training of GANs or data-free knowledge distillation. However, these approaches often suffer from unstable training of generators or low-quality generated data, limiting their guidance for the model. To address this challenge, we propose a novel method of data replay based on diffusion models. Instead of training a diffusion model, we employ a pre-trained conditional diffusion model to reverse-engineer each class, searching the corresponding input conditions for each class within the model's input space, significantly reducing computational resources and time consumption while ensuring effective generation. Furthermore, we enhance the classifier's domain generalization ability on generated and real data through contrastive learning, indirectly improving the representational capability of generated data for real data. Comprehensive experiments demonstrate that our method significantly outperforms existing baselines. Code is available at https://github.com/jinglin-liang/DDDR.
Read more9/5/2024

0
Adaptive Memory Replay for Continual Learning
James Seale Smith, Lazar Valkov, Shaunak Halbe, Vyshnavi Gutta, Rogerio Feris, Zsolt Kira, Leonid Karlinsky
Foundation Models (FMs) have become the hallmark of modern AI, however, these models are trained on massive data, leading to financially expensive training. Updating FMs as new data becomes available is important, however, can lead to `catastrophic forgetting', where models underperform on tasks related to data sub-populations observed too long ago. This continual learning (CL) phenomenon has been extensively studied, but primarily in a setting where only a small amount of past data can be stored. We advocate for the paradigm where memory is abundant, allowing us to keep all previous data, but computational resources are limited. In this setting, traditional replay-based CL approaches are outperformed by a simple baseline which replays past data selected uniformly at random, indicating that this setting necessitates a new approach. We address this by introducing a framework of adaptive memory replay for continual learning, where sampling of past data is phrased as a multi-armed bandit problem. We utilize Bolzmann sampling to derive a method which dynamically selects past data for training conditioned on the current task, assuming full data access and emphasizing training efficiency. Through extensive evaluations on both vision and language pre-training tasks, we demonstrate the effectiveness of our approach, which maintains high performance while reducing forgetting by up to 10% at no training efficiency cost.
Read more4/22/2024

0
CORE: Mitigating Catastrophic Forgetting in Continual Learning through Cognitive Replay
Jianshu Zhang, Yankai Fu, Ziheng Peng, Dongyu Yao, Kun He
This paper introduces a novel perspective to significantly mitigate catastrophic forgetting in continuous learning (CL), which emphasizes models' capacity to preserve existing knowledge and assimilate new information. Current replay-based methods treat every task and data sample equally and thus can not fully exploit the potential of the replay buffer. In response, we propose COgnitive REplay (CORE), which draws inspiration from human cognitive review processes. CORE includes two key strategies: Adaptive Quantity Allocation and Quality-Focused Data Selection. The former adaptively modulates the replay buffer allocation for each task based on its forgetting rate, while the latter guarantees the inclusion of representative data that best encapsulates the characteristics of each task within the buffer. Our approach achieves an average accuracy of 37.95% on split-CIFAR10, surpassing the best baseline method by 6.52%. Additionally, it significantly enhances the accuracy of the poorest-performing task by 6.30% compared to the top baseline. Code is available at https://github.com/sterzhang/CORE.
Read more4/10/2024
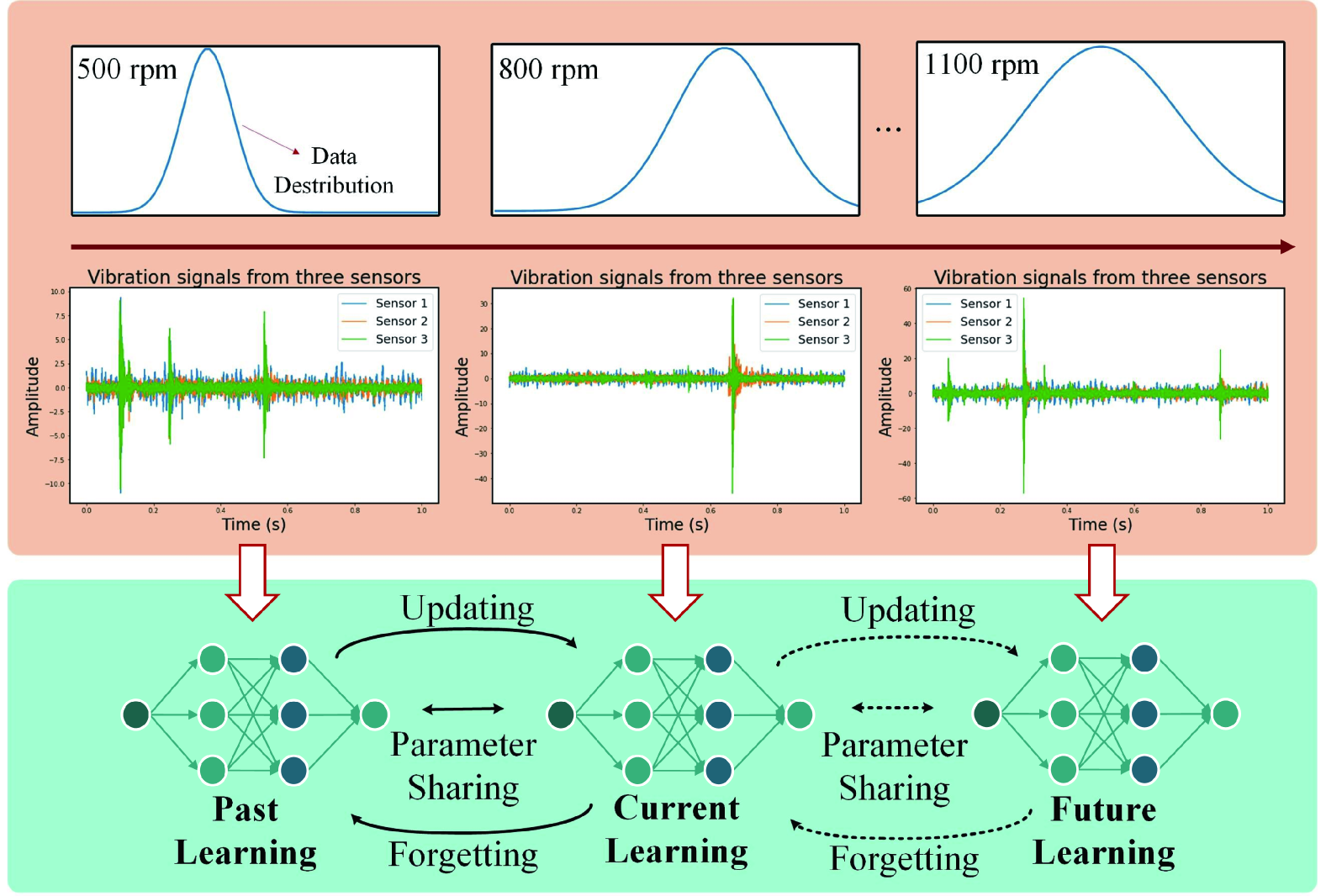
0
Continual Learning with Diffusion-based Generative Replay for Industrial Streaming Data
Jiayi He, Jiao Chen, Qianmiao Liu, Suyan Dai, Jianhua Tang, Dongpo Liu
The Industrial Internet of Things (IIoT) integrates interconnected sensors and devices to support industrial applications, but its dynamic environments pose challenges related to data drift. Considering the limited resources and the need to effectively adapt models to new data distributions, this paper introduces a Continual Learning (CL) approach, i.e., Distillation-based Self-Guidance (DSG), to address challenges presented by industrial streaming data via a novel generative replay mechanism. DSG utilizes knowledge distillation to transfer knowledge from the previous diffusion-based generator to the updated one, improving both the stability of the generator and the quality of reproduced data, thereby enhancing the mitigation of catastrophic forgetting. Experimental results on CWRU, DSA, and WISDM datasets demonstrate the effectiveness of DSG. DSG outperforms the state-of-the-art baseline in accuracy, demonstrating improvements ranging from 2.9% to 5.0% on key datasets, showcasing its potential for practical industrial applications.
Read more6/26/2024