Diffusion-driven GAN Inversion for Multi-Modal Face Image Generation
2405.04356
0
0
🖼️
Abstract
We present a new multi-modal face image generation method that converts a text prompt and a visual input, such as a semantic mask or scribble map, into a photo-realistic face image. To do this, we combine the strengths of Generative Adversarial networks (GANs) and diffusion models (DMs) by employing the multi-modal features in the DM into the latent space of the pre-trained GANs. We present a simple mapping and a style modulation network to link two models and convert meaningful representations in feature maps and attention maps into latent codes. With GAN inversion, the estimated latent codes can be used to generate 2D or 3D-aware facial images. We further present a multi-step training strategy that reflects textual and structural representations into the generated image. Our proposed network produces realistic 2D, multi-view, and stylized face images, which align well with inputs. We validate our method by using pre-trained 2D and 3D GANs, and our results outperform existing methods. Our project page is available at https://github.com/1211sh/Diffusion-driven_GAN-Inversion/.
Create account to get full access
Overview
- The paper presents a new multi-modal face image generation method that combines Generative Adversarial Networks (GANs) and Diffusion Models (DMs) to convert text prompts and visual inputs into realistic face images.
- The method leverages the strengths of both GAN and DM approaches, using a simple mapping and style modulation network to link the two models and convert meaningful representations into latent codes.
- The proposed network can generate 2D, multi-view, and stylized face images that align well with the input text and visual prompts, outperforming existing methods.
Plain English Explanation
The researchers have developed a new way to create realistic-looking face images from text descriptions and visual sketches. They've combined two powerful AI techniques, called Generative Adversarial Networks (GANs) and Diffusion Models (DMs), to make this work.
GANs are great at generating detailed, photorealistic images, but they can be tricky to train and control. DMs, on the other hand, are better at capturing the overall structure and style of an image, but the results may not be as sharp. The researchers figured out a way to take the best of both approaches and use them together.
Their method uses a simple "mapping" network to translate the information from the text and visual inputs into a special format that the GAN can understand. Then, a "style modulation" network helps the GAN generate images that match the desired look and feel. This allows the system to create 2D, 3D-aware, and stylized face images that closely match the given prompts.
The key advantage of this approach is that it can produce very convincing face images that are well-aligned with the input text and sketches. This could be useful for a variety of applications, like photo editing, virtual character creation, or even AI-generated art.
Technical Explanation
The researchers' method combines the strengths of Generative Adversarial Networks (GANs) and Diffusion Models (DMs) to enable multi-modal face image generation from text prompts and visual inputs like semantic masks or scribble maps.
The core of the approach is a simple mapping and style modulation network that links the pre-trained GAN and DM models. This network converts meaningful representations in the DM's feature maps and attention maps into latent codes that can be used by the GAN to generate the final face images.
The method employs a multi-step training strategy that reflects both the textual and structural information from the inputs into the generated images. During training, the network learns to generate 2D, multi-view, and stylized face images that closely align with the provided prompts.
The researchers validate their approach by using pre-trained 2D and 3D GANs, and their results outperform existing text-to-image and text-to-3D generation methods, as demonstrated on the project page.
Critical Analysis
The paper presents a promising approach for multi-modal face image generation, leveraging the strengths of both GANs and DMs. However, the authors do not extensively discuss potential limitations or caveats of their method.
For example, it would be useful to understand the computational and memory requirements of the proposed network, as well as its performance on diverse face attributes and skin tones. The authors could also explore the model's ability to generalize to unseen face poses, expressions, and ethnicities.
Additionally, while the results are impressive, the paper does not provide a detailed analysis of failure cases or edge cases where the model may struggle. Further research could investigate the robustness of the approach and identify areas for improvement.
Overall, the research represents an interesting step forward in the field of text-guided image generation, with potential applications in areas like photo editing, 3D character creation, and semantic image segmentation. However, further exploration of the method's limitations and edge cases could help strengthen the research and inform future developments in this area.
Conclusion
The presented multi-modal face image generation method offers a novel approach that combines the strengths of GANs and DMs to enable the creation of realistic face images from text prompts and visual inputs. By leveraging a simple mapping and style modulation network, the system can generate 2D, multi-view, and stylized face images that closely align with the provided prompts.
This research represents an important step forward in the field of text-guided image generation, with potential applications in areas like virtual character design, photo editing, and AI-generated art. While the results are impressive, further exploration of the method's limitations and robustness could help refine the approach and inspire future advancements in this rapidly evolving field of study.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📶
InvertAvatar: Incremental GAN Inversion for Generalized Head Avatars
Xiaochen Zhao, Jingxiang Sun, Lizhen Wang, Jinli Suo, Yebin Liu
0
0
While high fidelity and efficiency are central to the creation of digital head avatars, recent methods relying on 2D or 3D generative models often experience limitations such as shape distortion, expression inaccuracy, and identity flickering. Additionally, existing one-shot inversion techniques fail to fully leverage multiple input images for detailed feature extraction. We propose a novel framework, textbf{Incremental 3D GAN Inversion}, that enhances avatar reconstruction performance using an algorithm designed to increase the fidelity from multiple frames, resulting in improved reconstruction quality proportional to frame count. Our method introduces a unique animatable 3D GAN prior with two crucial modifications for enhanced expression controllability alongside an innovative neural texture encoder that categorizes texture feature spaces based on UV parameterization. Differentiating from traditional techniques, our architecture emphasizes pixel-aligned image-to-image translation, mitigating the need to learn correspondences between observation and canonical spaces. Furthermore, we incorporate ConvGRU-based recurrent networks for temporal data aggregation from multiple frames, boosting geometry and texture detail reconstruction. The proposed paradigm demonstrates state-of-the-art performance on one-shot and few-shot avatar animation tasks. Code will be available at https://github.com/XChenZ/invertAvatar.
5/28/2024
🐍
In-N-Out: Faithful 3D GAN Inversion with Volumetric Decomposition for Face Editing
Yiran Xu, Zhixin Shu, Cameron Smith, Seoung Wug Oh, Jia-Bin Huang
0
0
3D-aware GANs offer new capabilities for view synthesis while preserving the editing functionalities of their 2D counterparts. GAN inversion is a crucial step that seeks the latent code to reconstruct input images or videos, subsequently enabling diverse editing tasks through manipulation of this latent code. However, a model pre-trained on a particular dataset (e.g., FFHQ) often has difficulty reconstructing images with out-of-distribution (OOD) objects such as faces with heavy make-up or occluding objects. We address this issue by explicitly modeling OOD objects from the input in 3D-aware GANs. Our core idea is to represent the image using two individual neural radiance fields: one for the in-distribution content and the other for the out-of-distribution object. The final reconstruction is achieved by optimizing the composition of these two radiance fields with carefully designed regularization. We demonstrate that our explicit decomposition alleviates the inherent trade-off between reconstruction fidelity and editability. We evaluate reconstruction accuracy and editability of our method on challenging real face images and videos and showcase favorable results against other baselines.
4/16/2024
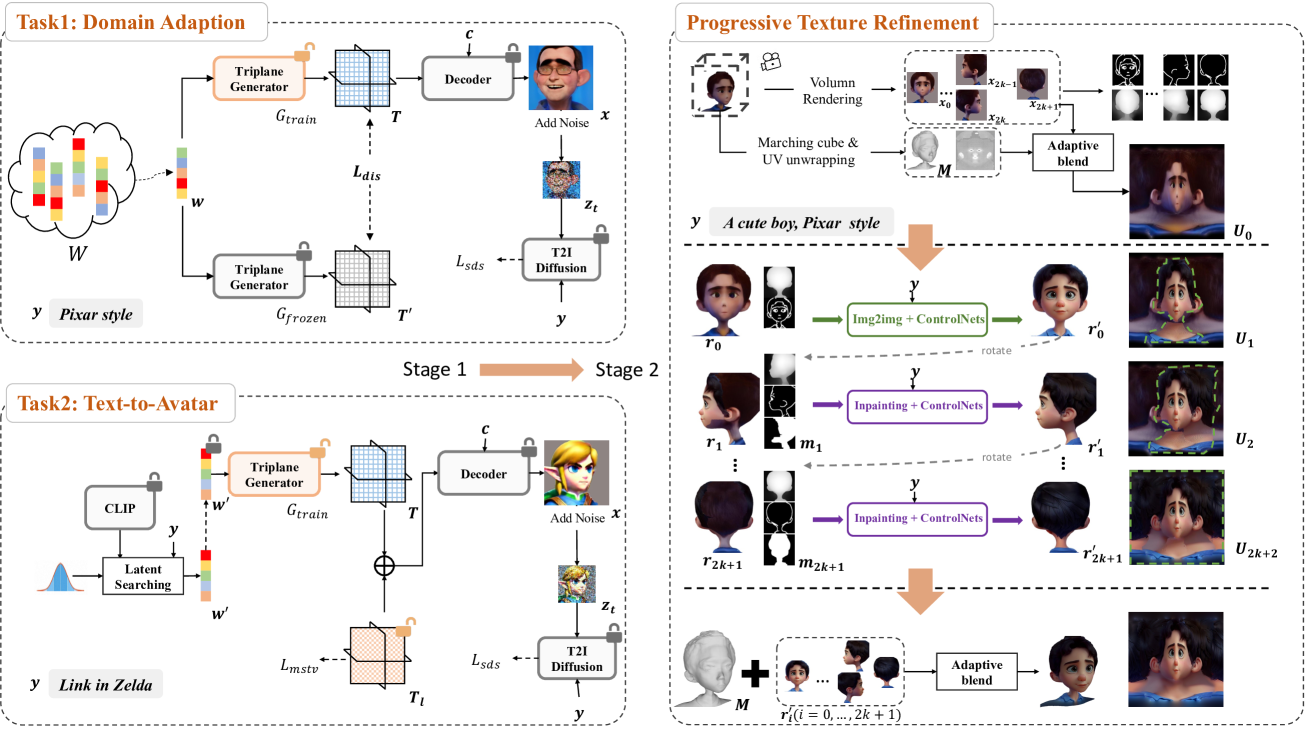
DiffusionGAN3D: Boosting Text-guided 3D Generation and Domain Adaptation by Combining 3D GANs and Diffusion Priors
Biwen Lei, Kai Yu, Mengyang Feng, Miaomiao Cui, Xuansong Xie
0
0
Text-guided domain adaptation and generation of 3D-aware portraits find many applications in various fields. However, due to the lack of training data and the challenges in handling the high variety of geometry and appearance, the existing methods for these tasks suffer from issues like inflexibility, instability, and low fidelity. In this paper, we propose a novel framework DiffusionGAN3D, which boosts text-guided 3D domain adaptation and generation by combining 3D GANs and diffusion priors. Specifically, we integrate the pre-trained 3D generative models (e.g., EG3D) and text-to-image diffusion models. The former provides a strong foundation for stable and high-quality avatar generation from text. And the diffusion models in turn offer powerful priors and guide the 3D generator finetuning with informative direction to achieve flexible and efficient text-guided domain adaptation. To enhance the diversity in domain adaptation and the generation capability in text-to-avatar, we introduce the relative distance loss and case-specific learnable triplane respectively. Besides, we design a progressive texture refinement module to improve the texture quality for both tasks above. Extensive experiments demonstrate that the proposed framework achieves excellent results in both domain adaptation and text-to-avatar tasks, outperforming existing methods in terms of generation quality and efficiency. The project homepage is at https://younglbw.github.io/DiffusionGAN3D-homepage/.
4/15/2024
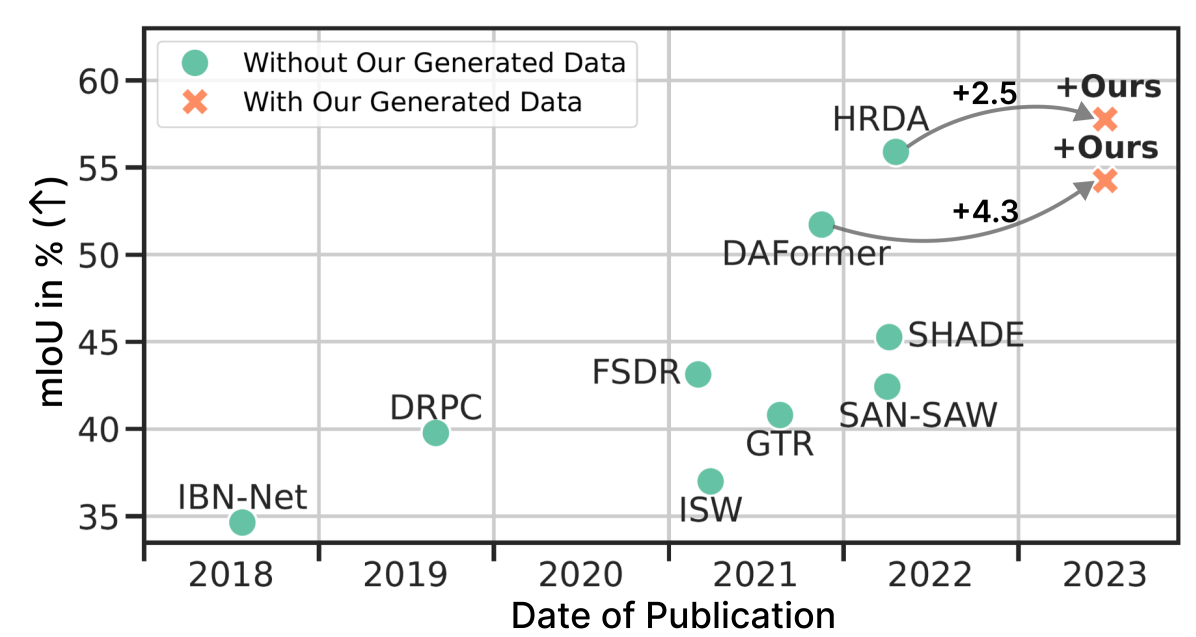
DGInStyle: Domain-Generalizable Semantic Segmentation with Image Diffusion Models and Stylized Semantic Control
Yuru Jia, Lukas Hoyer, Shengyu Huang, Tianfu Wang, Luc Van Gool, Konrad Schindler, Anton Obukhov
0
0
Large, pretrained latent diffusion models (LDMs) have demonstrated an extraordinary ability to generate creative content, specialize to user data through few-shot fine-tuning, and condition their output on other modalities, such as semantic maps. However, are they usable as large-scale data generators, e.g., to improve tasks in the perception stack, like semantic segmentation? We investigate this question in the context of autonomous driving, and answer it with a resounding yes. We propose an efficient data generation pipeline termed DGInStyle. First, we examine the problem of specializing a pretrained LDM to semantically-controlled generation within a narrow domain. Second, we propose a Style Swap technique to endow the rich generative prior with the learned semantic control. Third, we design a Multi-resolution Latent Fusion technique to overcome the bias of LDMs towards dominant objects. Using DGInStyle, we generate a diverse dataset of street scenes, train a domain-agnostic semantic segmentation model on it, and evaluate the model on multiple popular autonomous driving datasets. Our approach consistently increases the performance of several domain generalization methods compared to the previous state-of-the-art methods. Source code and dataset are available at https://dginstyle.github.io.
4/10/2024