DGInStyle: Domain-Generalizable Semantic Segmentation with Image Diffusion Models and Stylized Semantic Control
2312.03048
0
0
Abstract
Large, pretrained latent diffusion models (LDMs) have demonstrated an extraordinary ability to generate creative content, specialize to user data through few-shot fine-tuning, and condition their output on other modalities, such as semantic maps. However, are they usable as large-scale data generators, e.g., to improve tasks in the perception stack, like semantic segmentation? We investigate this question in the context of autonomous driving, and answer it with a resounding yes. We propose an efficient data generation pipeline termed DGInStyle. First, we examine the problem of specializing a pretrained LDM to semantically-controlled generation within a narrow domain. Second, we propose a Style Swap technique to endow the rich generative prior with the learned semantic control. Third, we design a Multi-resolution Latent Fusion technique to overcome the bias of LDMs towards dominant objects. Using DGInStyle, we generate a diverse dataset of street scenes, train a domain-agnostic semantic segmentation model on it, and evaluate the model on multiple popular autonomous driving datasets. Our approach consistently increases the performance of several domain generalization methods compared to the previous state-of-the-art methods. Source code and dataset are available at https://dginstyle.github.io.
Create account to get full access
Overview
- This paper presents "DGInStyle", a novel approach for domain-generalizable semantic segmentation using image diffusion models and stylized semantic control.
- The key idea is to leverage the power of diffusion models to generate diverse, realistic images that can be used to train a segmentation model to perform well across different domains.
- The paper also introduces a "stylized semantic control" technique that allows the model to generate images with desired semantic layouts, further improving its domain generalization capabilities.
Plain English Explanation
The researchers behind this paper wanted to create a semantic segmentation model that could work well on a variety of different datasets and scenarios, not just a single, specific domain. Semantic segmentation is the task of assigning a category label to every pixel in an image, which is useful for applications like self-driving cars, medical image analysis, and more.
To achieve this domain-generalizability, the researchers used a technique called diffusion models. Diffusion models are a type of generative AI that can create highly realistic images by gradually adding noise to an image and then learning to reverse the process. The researchers trained these diffusion models on diverse datasets, allowing the segmentation model to be exposed to a wide range of visual styles and content during training.
Additionally, the team developed a "stylized semantic control" method that lets the diffusion model generate images with specific semantic layouts, like having a car in the center of the frame. This further boosts the segmentation model's ability to generalize to new domains, as it can learn to recognize objects and scenes in various configurations.
Technical Explanation
The core of the DGInStyle approach is the use of diffusion models to generate diverse, realistic training data for the semantic segmentation model. The researchers trained a diffusion model on a large, diverse dataset of images, allowing it to learn the natural distribution of visual content and styles.
To enable the segmentation model to learn semantic relationships, the diffusion model was also trained to generate images with specific semantic layouts, guided by "stylized semantic control". This involved providing the diffusion model with a target semantic map, which it then used to generate an image matching that layout.
The segmentation model was trained on the diverse, realistic images generated by the diffusion model, as well as the corresponding ground truth segmentation maps. This allowed the segmentation model to learn robust features that generalize well to new domains, without overfitting to any single dataset.
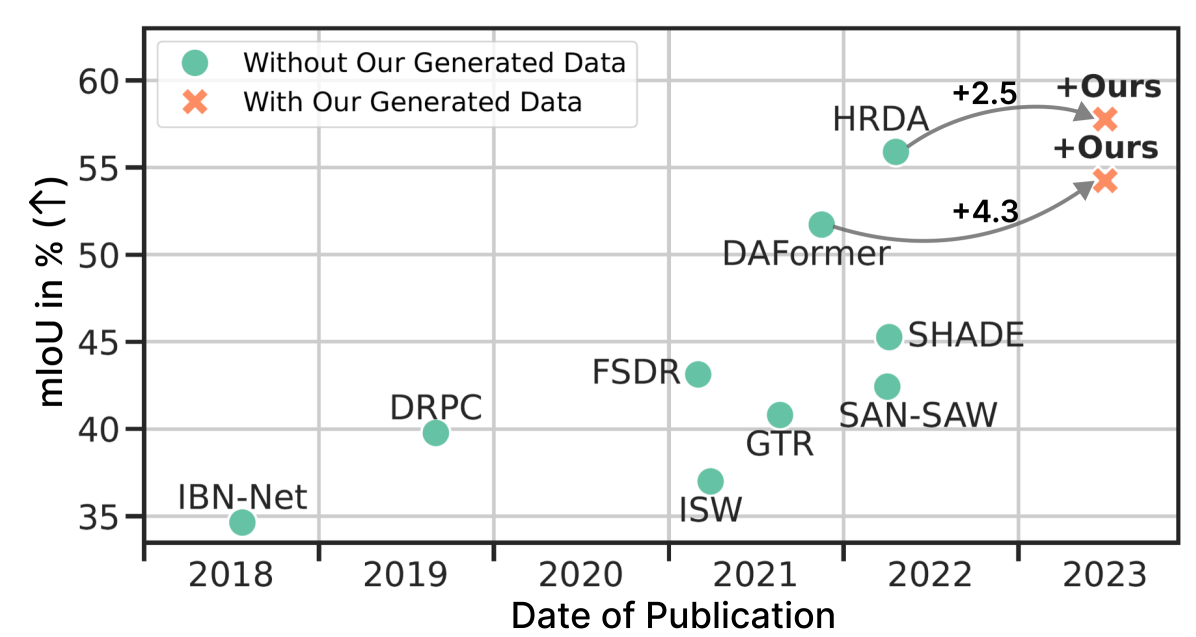
The researchers evaluated DGInStyle on several standard semantic segmentation benchmarks, including PASCAL-VOC, Cityscapes, and ADE20K. The results showed that DGInStyle outperformed previous state-of-the-art methods for domain-generalized semantic segmentation, demonstrating the effectiveness of the diffusion-based approach.
Critical Analysis
The authors acknowledge several limitations of their work. First, the computational and memory requirements of training the diffusion model may be prohibitive for some practical applications. Additionally, the stylized semantic control mechanism relies on having access to ground truth segmentation maps, which may not always be available.
Another potential issue is that the diversity of the generated images, while beneficial for domain generalization, may not necessarily match the distribution of the target domain. This could lead to suboptimal performance on specific datasets, despite the overall improved generalization.
Further research is needed to explore ways of reducing the computational burden of the diffusion model, as well as techniques for generating diverse, realistic images without requiring ground truth segmentation maps. Integrating additional domain adaptation or meta-learning strategies could also help improve the model's performance on specific target domains.
Conclusion
The DGInStyle approach presented in this paper represents a promising direction for achieving domain-generalizable semantic segmentation. By leveraging the power of diffusion models and stylized semantic control, the researchers have demonstrated a way to train segmentation models that can perform well across a wide range of visual domains, rather than being confined to a single dataset or scenario.
This work has important implications for applications that require robust and adaptable computer vision models, such as autonomous vehicles, medical image analysis, and robotic perception. As the field of machine learning continues to advance, techniques like DGInStyle will play an increasingly important role in developing AI systems that can reliably and safely operate in the complex, real-world environments we inhabit.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
LDEdit: Towards Generalized Text Guided Image Manipulation via Latent Diffusion Models
Paramanand Chandramouli, Kanchana Vaishnavi Gandikota
0
0
Research in vision-language models has seen rapid developments off-late, enabling natural language-based interfaces for image generation and manipulation. Many existing text guided manipulation techniques are restricted to specific classes of images, and often require fine-tuning to transfer to a different style or domain. Nevertheless, generic image manipulation using a single model with flexible text inputs is highly desirable. Recent work addresses this task by guiding generative models trained on the generic image datasets using pretrained vision-language encoders. While promising, this approach requires expensive optimization for each input. In this work, we propose an optimization-free method for the task of generic image manipulation from text prompts. Our approach exploits recent Latent Diffusion Models (LDM) for text to image generation to achieve zero-shot text guided manipulation. We employ a deterministic forward diffusion in a lower dimensional latent space, and the desired manipulation is achieved by simply providing the target text to condition the reverse diffusion process. We refer to our approach as LDEdit. We demonstrate the applicability of our method on semantic image manipulation and artistic style transfer. Our method can accomplish image manipulation on diverse domains and enables editing multiple attributes in a straightforward fashion. Extensive experiments demonstrate the benefit of our approach over competing baselines.
5/7/2024

Grounding Stylistic Domain Generalization with Quantitative Domain Shift Measures and Synthetic Scene Images
Yiran Luo, Joshua Feinglass, Tejas Gokhale, Kuan-Cheng Lee, Chitta Baral, Yezhou Yang
0
0
Domain Generalization (DG) is a challenging task in machine learning that requires a coherent ability to comprehend shifts across various domains through extraction of domain-invariant features. DG performance is typically evaluated by performing image classification in domains of various image styles. However, current methodology lacks quantitative understanding about shifts in stylistic domain, and relies on a vast amount of pre-training data, such as ImageNet1K, which are predominantly in photo-realistic style with weakly supervised class labels. Such a data-driven practice could potentially result in spurious correlation and inflated performance on DG benchmarks. In this paper, we introduce a new DG paradigm to address these risks. We first introduce two new quantitative measures ICV and IDD to describe domain shifts in terms of consistency of classes within one domain and similarity between two stylistic domains. We then present SuperMarioDomains (SMD), a novel synthetic multi-domain dataset sampled from video game scenes with more consistent classes and sufficient dissimilarity compared to ImageNet1K. We demonstrate our DG method SMOS. SMOS first uses SMD to train a precursor model, which is then used to ground the training on a DG benchmark. We observe that SMOS contributes to state-of-the-art performance across five DG benchmarks, gaining large improvements to performances on abstract domains along with on-par or slight improvements to those on photo-realistic domains. Our qualitative analysis suggests that these improvements can be attributed to reduced distributional divergence between originally distant domains. Our data are available at https://github.com/fpsluozi/SMD-SMOS .
5/28/2024
🖼️
Diffusion-driven GAN Inversion for Multi-Modal Face Image Generation
Jihyun Kim, Changjae Oh, Hoseok Do, Soohyun Kim, Kwanghoon Sohn
0
0
We present a new multi-modal face image generation method that converts a text prompt and a visual input, such as a semantic mask or scribble map, into a photo-realistic face image. To do this, we combine the strengths of Generative Adversarial networks (GANs) and diffusion models (DMs) by employing the multi-modal features in the DM into the latent space of the pre-trained GANs. We present a simple mapping and a style modulation network to link two models and convert meaningful representations in feature maps and attention maps into latent codes. With GAN inversion, the estimated latent codes can be used to generate 2D or 3D-aware facial images. We further present a multi-step training strategy that reflects textual and structural representations into the generated image. Our proposed network produces realistic 2D, multi-view, and stylized face images, which align well with inputs. We validate our method by using pre-trained 2D and 3D GANs, and our results outperform existing methods. Our project page is available at https://github.com/1211sh/Diffusion-driven_GAN-Inversion/.
5/8/2024
Complex Style Image Transformations for Domain Generalization in Medical Images
Nikolaos Spanos, Anastasios Arsenos, Paraskevi-Antonia Theofilou, Paraskevi Tzouveli, Athanasios Voulodimos, Stefanos Kollias
0
0
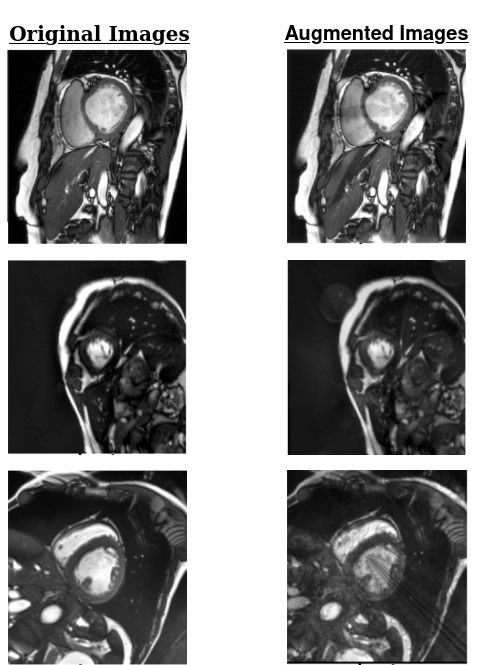
The absence of well-structured large datasets in medical computer vision results in decreased performance of automated systems and, especially, of deep learning models. Domain generalization techniques aim to approach unknown domains from a single data source. In this paper we introduce a novel framework, named CompStyle, which leverages style transfer and adversarial training, along with high-level input complexity augmentation to effectively expand the domain space and address unknown distributions. State-of-the-art style transfer methods depend on the existence of subdomains within the source dataset. However, this can lead to an inherent dataset bias in the image creation. Input-level augmentation can provide a solution to this problem by widening the domain space in the source dataset and boost performance on out-of-domain distributions. We provide results from experiments on semantic segmentation on prostate data and corruption robustness on cardiac data which demonstrate the effectiveness of our approach. Our method increases performance in both tasks, without added cost to training time or resources.
6/4/2024