InvertAvatar: Incremental GAN Inversion for Generalized Head Avatars

0
📶
Sign in to get full access
Overview
- Existing methods for creating digital avatars often have limitations such as shape distortion, expression inaccuracy, and identity flickering.
- Traditional one-shot inversion techniques fail to fully leverage multiple input images for detailed feature extraction.
- The proposed framework, Incremental 3D GAN Inversion, aims to enhance avatar reconstruction performance by increasing fidelity from multiple frames.
Plain English Explanation
The research focuses on improving the quality and realism of digital avatars, which are virtual representations of people's faces and expressions. Current methods for creating these avatars often have issues, such as the shape of the face being distorted, the expressions not being accurately captured, and the identity of the person flickering or changing.
Additionally, existing techniques that only use a single input image to create the avatar struggle to fully capture all the detailed features and nuances of the person's appearance. The researchers propose a new framework called Incremental 3D GAN Inversion that aims to address these problems.
The key idea is to use multiple input images of a person, rather than just one, to reconstruct a more detailed and accurate 3D avatar. The framework includes a unique "animatable 3D GAN prior" that helps control the expressions and movements of the avatar, as well as a novel "neural texture encoder" that categorizes the different textures and features of the person's face.
By using these techniques and aggregating information from multiple frames, the researchers were able to create avatars with improved geometry, texture, and overall fidelity compared to previous methods. This could lead to more realistic and engaging digital avatars for a variety of applications, such as video games, virtual reality, and online communication.
Technical Explanation
The Incremental 3D GAN Inversion framework introduces several key innovations to enhance avatar reconstruction performance. First, it incorporates a unique "animatable 3D GAN prior" that provides enhanced expression controllability, building on previous work like GeneAvatar and InstantAvatar.
Additionally, the framework includes a "neural texture encoder" that categorizes texture feature spaces based on UV parameterization, allowing for more detailed and accurate texture reconstruction. This addresses limitations of traditional techniques that struggle to learn correspondences between observation and canonical spaces.
The architecture also emphasizes pixel-aligned image-to-image translation, which helps mitigate the need to learn these challenging correspondences. Furthermore, the researchers incorporate ConvGRU-based recurrent networks to aggregate temporal data from multiple frames, boosting the reconstruction of both geometry and texture details.
These innovations, combined with the use of multiple input images, enable the Incremental 3D GAN Inversion framework to achieve state-of-the-art performance on one-shot and few-shot avatar animation tasks, outperforming previous methods like Diffusion-Driven GAN Inversion and GGAvatar.
Critical Analysis
The research paper presents a compelling and innovative approach to enhancing the quality and realism of digital avatars. The key strengths of the Incremental 3D GAN Inversion framework include its ability to leverage multiple input images, its unique animatable 3D GAN prior and neural texture encoder, and its emphasis on pixel-aligned image-to-image translation.
However, the paper does acknowledge some potential limitations, such as the need for further investigation into the scalability and robustness of the framework when dealing with more diverse datasets and real-world scenarios. Additionally, the researchers mention that the current implementation may not be suitable for real-time applications due to its computational complexity.
Further research could explore ways to optimize the framework's efficiency, as well as investigate its applicability to other types of avatar-related tasks, such as full-body reconstruction or integration with virtual reality systems. Exploring the ethical implications of such advanced avatar technologies, particularly regarding privacy and identity representation, could also be an important area for future study.
Conclusion
The Incremental 3D GAN Inversion framework represents a significant advancement in the field of digital avatar creation, addressing key limitations of existing methods. By leveraging multiple input images and incorporating novel architectural components, the researchers have demonstrated a way to improve the fidelity, expression accuracy, and temporal stability of reconstructed avatars.
This work has the potential to enhance various applications, from video games and virtual reality to online communication and social media. As the demand for more realistic and engaging digital representations continues to grow, the insights and techniques presented in this paper could pave the way for a new generation of high-quality, personalized avatars that better capture the nuances and individuality of human appearance and expression.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📶
0
InvertAvatar: Incremental GAN Inversion for Generalized Head Avatars
Xiaochen Zhao, Jingxiang Sun, Lizhen Wang, Jinli Suo, Yebin Liu
While high fidelity and efficiency are central to the creation of digital head avatars, recent methods relying on 2D or 3D generative models often experience limitations such as shape distortion, expression inaccuracy, and identity flickering. Additionally, existing one-shot inversion techniques fail to fully leverage multiple input images for detailed feature extraction. We propose a novel framework, textbf{Incremental 3D GAN Inversion}, that enhances avatar reconstruction performance using an algorithm designed to increase the fidelity from multiple frames, resulting in improved reconstruction quality proportional to frame count. Our method introduces a unique animatable 3D GAN prior with two crucial modifications for enhanced expression controllability alongside an innovative neural texture encoder that categorizes texture feature spaces based on UV parameterization. Differentiating from traditional techniques, our architecture emphasizes pixel-aligned image-to-image translation, mitigating the need to learn correspondences between observation and canonical spaces. Furthermore, we incorporate ConvGRU-based recurrent networks for temporal data aggregation from multiple frames, boosting geometry and texture detail reconstruction. The proposed paradigm demonstrates state-of-the-art performance on one-shot and few-shot avatar animation tasks. Code will be available at https://github.com/XChenZ/invertAvatar.
Read more5/28/2024
🐍
0
In-N-Out: Faithful 3D GAN Inversion with Volumetric Decomposition for Face Editing
Yiran Xu, Zhixin Shu, Cameron Smith, Seoung Wug Oh, Jia-Bin Huang
3D-aware GANs offer new capabilities for view synthesis while preserving the editing functionalities of their 2D counterparts. GAN inversion is a crucial step that seeks the latent code to reconstruct input images or videos, subsequently enabling diverse editing tasks through manipulation of this latent code. However, a model pre-trained on a particular dataset (e.g., FFHQ) often has difficulty reconstructing images with out-of-distribution (OOD) objects such as faces with heavy make-up or occluding objects. We address this issue by explicitly modeling OOD objects from the input in 3D-aware GANs. Our core idea is to represent the image using two individual neural radiance fields: one for the in-distribution content and the other for the out-of-distribution object. The final reconstruction is achieved by optimizing the composition of these two radiance fields with carefully designed regularization. We demonstrate that our explicit decomposition alleviates the inherent trade-off between reconstruction fidelity and editability. We evaluate reconstruction accuracy and editability of our method on challenging real face images and videos and showcase favorable results against other baselines.
Read more4/16/2024
🖼️
0
Diffusion-driven GAN Inversion for Multi-Modal Face Image Generation
Jihyun Kim, Changjae Oh, Hoseok Do, Soohyun Kim, Kwanghoon Sohn
We present a new multi-modal face image generation method that converts a text prompt and a visual input, such as a semantic mask or scribble map, into a photo-realistic face image. To do this, we combine the strengths of Generative Adversarial networks (GANs) and diffusion models (DMs) by employing the multi-modal features in the DM into the latent space of the pre-trained GANs. We present a simple mapping and a style modulation network to link two models and convert meaningful representations in feature maps and attention maps into latent codes. With GAN inversion, the estimated latent codes can be used to generate 2D or 3D-aware facial images. We further present a multi-step training strategy that reflects textual and structural representations into the generated image. Our proposed network produces realistic 2D, multi-view, and stylized face images, which align well with inputs. We validate our method by using pre-trained 2D and 3D GANs, and our results outperform existing methods. Our project page is available at https://github.com/1211sh/Diffusion-driven_GAN-Inversion/.
Read more5/8/2024
0
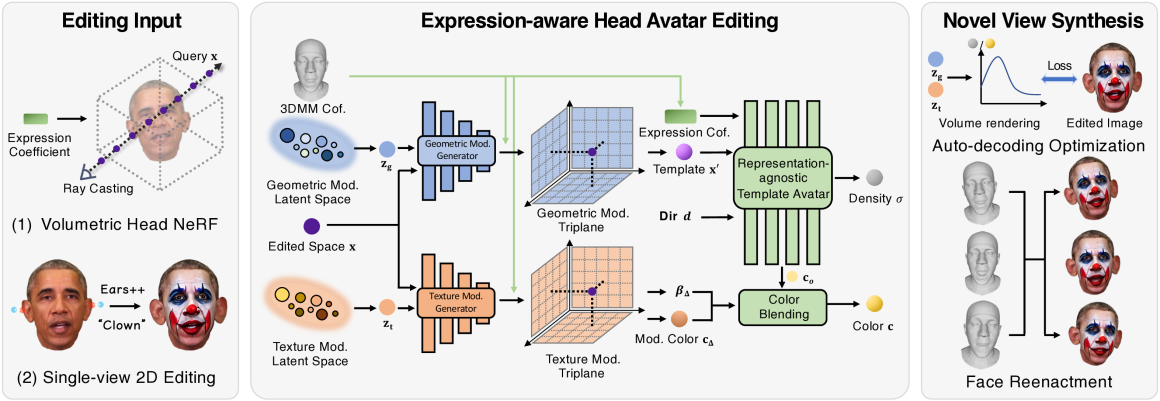
GeneAvatar: Generic Expression-Aware Volumetric Head Avatar Editing from a Single Image
Chong Bao, Yinda Zhang, Yuan Li, Xiyu Zhang, Bangbang Yang, Hujun Bao, Marc Pollefeys, Guofeng Zhang, Zhaopeng Cui
Recently, we have witnessed the explosive growth of various volumetric representations in modeling animatable head avatars. However, due to the diversity of frameworks, there is no practical method to support high-level applications like 3D head avatar editing across different representations. In this paper, we propose a generic avatar editing approach that can be universally applied to various 3DMM driving volumetric head avatars. To achieve this goal, we design a novel expression-aware modification generative model, which enables lift 2D editing from a single image to a consistent 3D modification field. To ensure the effectiveness of the generative modification process, we develop several techniques, including an expression-dependent modification distillation scheme to draw knowledge from the large-scale head avatar model and 2D facial texture editing tools, implicit latent space guidance to enhance model convergence, and a segmentation-based loss reweight strategy for fine-grained texture inversion. Extensive experiments demonstrate that our method delivers high-quality and consistent results across multiple expression and viewpoints. Project page: https://zju3dv.github.io/geneavatar/
Read more4/3/2024