Diffusion Meets DAgger: Supercharging Eye-in-hand Imitation Learning

0
Sign in to get full access
Overview
• This paper presents a novel imitation learning approach that combines diffusion models and the DAgger algorithm to improve eye-in-hand manipulation tasks.
• The key idea is to use a diffusion model to generate diverse and realistic demonstration trajectories, which are then used to train a policy via the DAgger algorithm.
Plain English Explanation
The paper introduces a new way to teach a robot how to perform tasks by watching human demonstrations. Traditional imitation learning approaches rely on a limited set of demonstrations provided by a human expert. However, this can be challenging, as it may be difficult to capture all the nuances of a task in a few examples.
To address this, the researchers propose using a diffusion model - a type of generative AI model - to generate additional, diverse demonstration trajectories. These synthetic demonstrations are then used to train the robot's policy using the DAgger algorithm, a popular imitation learning technique.
The advantage of this approach is that the robot can learn from a much richer set of examples, including variations that may not have been captured in the original human demonstrations. This can lead to the robot developing more robust and versatile skills for the task at hand.
Technical Explanation
The paper introduces a novel imitation learning framework that integrates diffusion models and the DAgger algorithm to improve eye-in-hand manipulation tasks.
Diffusion models are a class of generative AI models that can be used to generate diverse and realistic demonstration trajectories. The authors leverage this capability to augment the limited human demonstrations typically available for imitation learning. They train a diffusion model on the provided demonstrations, and then use this model to generate additional synthetic trajectories.
These augmented demonstration sets are then used to train a policy via the DAgger algorithm. DAgger is an iterative imitation learning approach that collects additional training data by having the learner execute its current policy and querying the expert for corrections. By combining DAgger with the diverse demonstrations generated by the diffusion model, the authors are able to achieve superior performance on eye-in-hand manipulation tasks compared to standard imitation learning baselines.
Critical Analysis
The paper presents a promising approach to improving imitation learning by leveraging diffusion models to generate diverse demonstration data. This is an interesting and well-executed idea that has the potential to advance the state-of-the-art in robot learning from human demonstrations.
One potential limitation is the reliance on the diffusion model's ability to faithfully capture the underlying distribution of demonstration trajectories. If the diffusion model fails to generate diverse and realistic enough examples, the benefits of the proposed approach may be diminished. The authors do not provide a deep analysis of the diffusion model's performance or limitations in this specific context.
Additionally, the paper focuses primarily on eye-in-hand manipulation tasks, and it is not clear how well the approach would generalize to other robotic control problems. Further research would be needed to assess the broader applicability of the method.
Conclusion
This paper presents a novel imitation learning framework that combines diffusion models and the DAgger algorithm to improve eye-in-hand manipulation tasks. By using a diffusion model to generate diverse demonstration trajectories, the authors are able to train more robust and versatile policies than standard imitation learning approaches.
The work demonstrates the potential of integrating generative AI models, such as diffusion models, with established imitation learning techniques to enhance the performance and versatility of robotic control systems. As robots continue to play an increasingly important role in our lives, advances in this area could have significant real-world impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Diffusion Meets DAgger: Supercharging Eye-in-hand Imitation Learning
Xiaoyu Zhang, Matthew Chang, Pranav Kumar, Saurabh Gupta
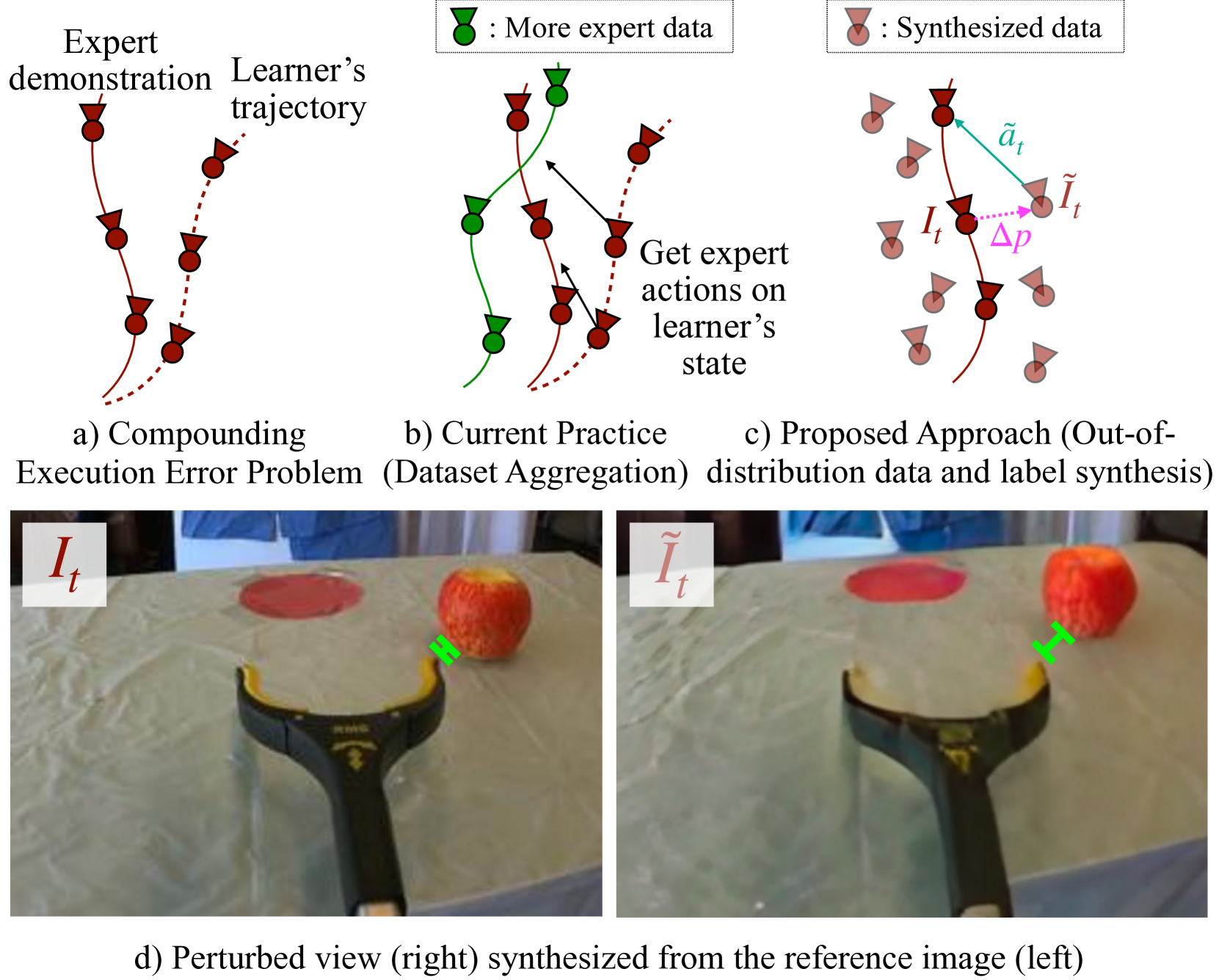
A common failure mode for policies trained with imitation is compounding execution errors at test time. When the learned policy encounters states that are not present in the expert demonstrations, the policy fails, leading to degenerate behavior. The Dataset Aggregation, or DAgger approach to this problem simply collects more data to cover these failure states. However, in practice, this is often prohibitively expensive. In this work, we propose Diffusion Meets DAgger (DMD), a method to reap the benefits of DAgger without the cost for eye-in-hand imitation learning problems. Instead of collecting new samples to cover out-of-distribution states, DMD uses recent advances in diffusion models to synthesize these samples. This leads to robust performance from few demonstrations. We compare DMD against behavior cloning baseline across four tasks: pushing, stacking, pouring, and shirt hanging. In pushing, DMD achieves 80% success rate with as few as 8 expert demonstrations, where naive behavior cloning reaches only 20%. In stacking, DMD succeeds on average 92% of the time across 5 cups, versus 40% for BC. When pouring coffee beans, DMD transfers to another cup successfully 80% of the time. Finally, DMD attains 90% success rate for hanging shirt on a clothing rack.
Read more6/6/2024
🏷️
0
MEGA-DAgger: Imitation Learning with Multiple Imperfect Experts
Xiatao Sun, Shuo Yang, Mingyan Zhou, Kunpeng Liu, Rahul Mangharam
Imitation learning has been widely applied to various autonomous systems thanks to recent development in interactive algorithms that address covariate shift and compounding errors induced by traditional approaches like behavior cloning. However, existing interactive imitation learning methods assume access to one perfect expert. Whereas in reality, it is more likely to have multiple imperfect experts instead. In this paper, we propose MEGA-DAgger, a new DAgger variant that is suitable for interactive learning with multiple imperfect experts. First, unsafe demonstrations are filtered while aggregating the training data, so the imperfect demonstrations have little influence when training the novice policy. Next, experts are evaluated and compared on scenarios-specific metrics to resolve the conflicted labels among experts. Through experiments in autonomous racing scenarios, we demonstrate that policy learned using MEGA-DAgger can outperform both experts and policies learned using the state-of-the-art interactive imitation learning algorithms such as Human-Gated DAgger. The supplementary video can be found at url{https://youtu.be/wPCht31MHrw}.
Read more5/3/2024
⚙️
0
Diffusion Model-Augmented Behavioral Cloning
Shang-Fu Chen, Hsiang-Chun Wang, Ming-Hao Hsu, Chun-Mao Lai, Shao-Hua Sun
Imitation learning addresses the challenge of learning by observing an expert's demonstrations without access to reward signals from environments. Most existing imitation learning methods that do not require interacting with environments either model the expert distribution as the conditional probability p(a|s) (e.g., behavioral cloning, BC) or the joint probability p(s, a). Despite the simplicity of modeling the conditional probability with BC, it usually struggles with generalization. While modeling the joint probability can improve generalization performance, the inference procedure is often time-consuming, and the model can suffer from manifold overfitting. This work proposes an imitation learning framework that benefits from modeling both the conditional and joint probability of the expert distribution. Our proposed Diffusion Model-Augmented Behavioral Cloning (DBC) employs a diffusion model trained to model expert behaviors and learns a policy to optimize both the BC loss (conditional) and our proposed diffusion model loss (joint). DBC outperforms baselines in various continuous control tasks in navigation, robot arm manipulation, dexterous manipulation, and locomotion. We design additional experiments to verify the limitations of modeling either the conditional probability or the joint probability of the expert distribution, as well as compare different generative models. Ablation studies justify the effectiveness of our design choices.
Read more6/4/2024

0
Learning Multimodal Behaviors from Scratch with Diffusion Policy Gradient
Zechu Li, Rickmer Krohn, Tao Chen, Anurag Ajay, Pulkit Agrawal, Georgia Chalvatzaki
Deep reinforcement learning (RL) algorithms typically parameterize the policy as a deep network that outputs either a deterministic action or a stochastic one modeled as a Gaussian distribution, hence restricting learning to a single behavioral mode. Meanwhile, diffusion models emerged as a powerful framework for multimodal learning. However, the use of diffusion policies in online RL is hindered by the intractability of policy likelihood approximation, as well as the greedy objective of RL methods that can easily skew the policy to a single mode. This paper presents Deep Diffusion Policy Gradient (DDiffPG), a novel actor-critic algorithm that learns from scratch multimodal policies parameterized as diffusion models while discovering and maintaining versatile behaviors. DDiffPG explores and discovers multiple modes through off-the-shelf unsupervised clustering combined with novelty-based intrinsic motivation. DDiffPG forms a multimodal training batch and utilizes mode-specific Q-learning to mitigate the inherent greediness of the RL objective, ensuring the improvement of the diffusion policy across all modes. Our approach further allows the policy to be conditioned on mode-specific embeddings to explicitly control the learned modes. Empirical studies validate DDiffPG's capability to master multimodal behaviors in complex, high-dimensional continuous control tasks with sparse rewards, also showcasing proof-of-concept dynamic online replanning when navigating mazes with unseen obstacles.
Read more6/4/2024